









博客内容将首发在微信公众号"跟我一起读论文啦啦",上面会定期分享机器学习、深度学习、数据挖掘、自然语言处理等高质量论文,欢迎关注!

本文要分享总结的是论文Improving Language Understanding by Generative Pre-Training,论文链接openAI-GPT.
论文动机以及创新点
-
现实世界中,无标签的文本语料库非常巨大,而带有标签的数据则显得十分匮乏,如何有效利用无标签的原始文本,对缓解自然语言处理相关任务对有监督学习方式的依赖显得至关重要。
-
有效的从无标签文本中利用超单词级信息有两个主要的难点:
①无法确定什么样的优化目标能学到最有效的文本表征,使之更好的用于迁移目的。
②对于学习到的文本表征,采用何种方式将其迁移到目标任务上,目前尚无共识。 -
论文中提出了半监督的方式来做语言理解,也就是无监督的pre-train,和有监督的fine-tune。该方法首先无监督的 p r e − t r a i n pre-train pre−train模型,学习到更加普遍、更适用的表征,然后模型以很小的微调迁移到众多特定的有监督学习任务上。在实验效果上,大幅超过了众多任务的state-of-art。不同于 w o r d E m b e d d i n g wordEmbedding wordEmbedding、 E L M o ELMo ELMo 以无监督的方式学习到一些特征,然后利用这些特征喂给一些特定的有监督模型,这里是先无监督的 p r e − t r a i n pre-train pre−train 模型,然后直接fine-tune预训练后的模型,迁移到一些特定的有监督任务上。
-
ELMo方法中,训练基于LSTM的双向语言模型能结合上下文内容学习到语义更丰富的词表征,而本论文中预训练的语言模型中使用了transformer(Masked Multi-Head Attention,单向)结构,相对而言,transformer更加鲁棒,在长距离依赖上的效果更好,迁移效果也更好。
-
适用场景:无标签样本量(只有X)远大于有标签样本量的数据集(同时有X,y),如果只用这少量的带标签样本训练出的模型泛化能力肯定比较弱,这个时候我们可以先用无标签样本(也就是只用X)预训练好一个语言模型,然后在该语言模型基础上用少量带标签的样本(同时有X,y)进行fine-tune,有监督的训练。
transformer简介
要介绍本论文,必须简单回顾下大名鼎鼎的transformer。
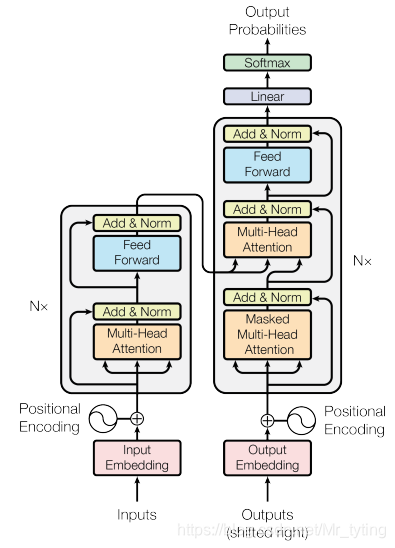
这里简单提下我个人认为的transformer关键点:
- Position Encoding 决定每个词的位置顺序,或者说在一个句子中不同的词之间的距离
- 注意力计算公式
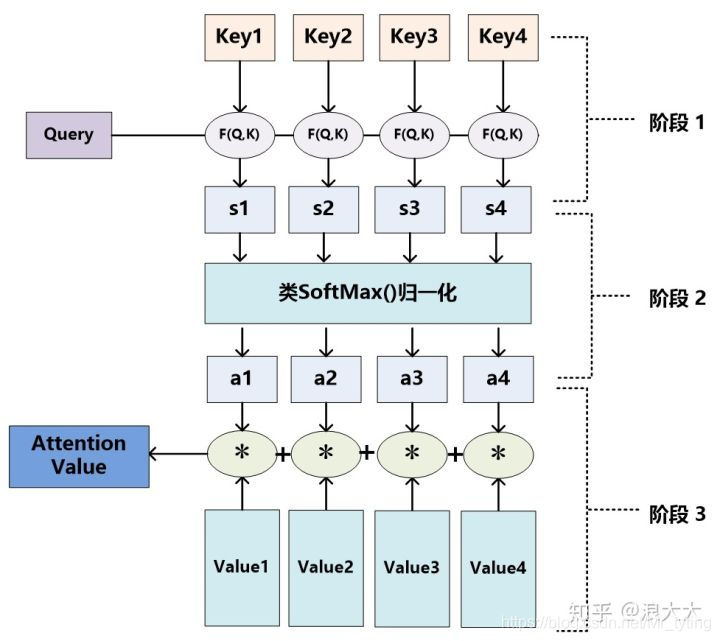
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
可以看到最后得到的Attention Value是个标量。
-
Self-attention (Encoder)和 masked self-attention(decoder)决定了当我们在某个位置encode一个词时,对输入句子的其他部分的关注程度。
-
Multi-Head 做多次不同的self-attention (对q,k,v赋予几组几次不同的权重,初始化多组不同的Q、K、V的矩阵)或者mask self-attention,起到ensemble的效果。
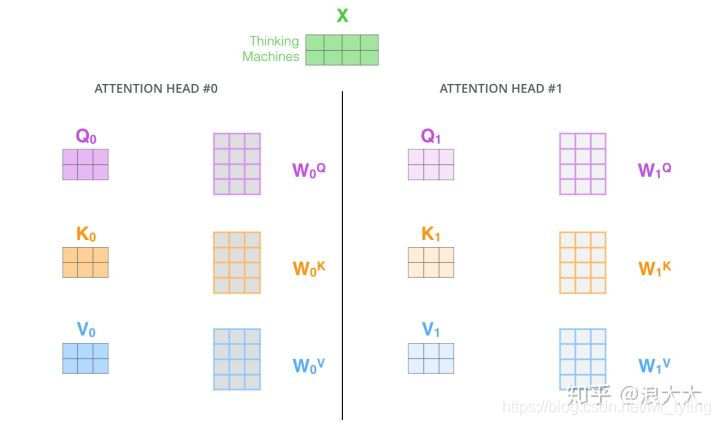
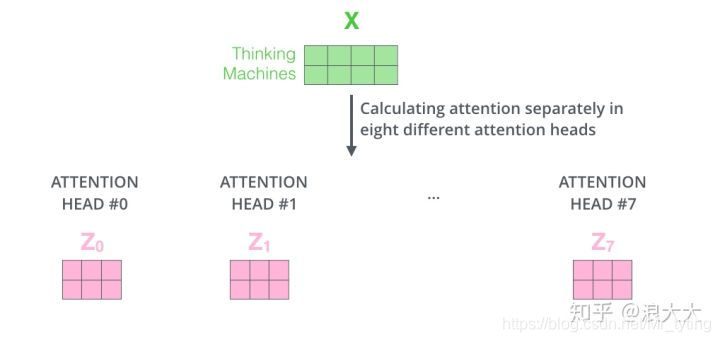
然后这些Z向量,concat成一个向量喂给下一层。 -
encoder-decoder Attention: Encoder的输出,会和每一层的Decoder输出状态做Attention计算。
-
从外在表现来看,transform和LSTM是一样的,每个输入位置都会有对应的概率分布(或是label)输出,只不过transformer是并行的计算(不依赖上一时刻信息,每个位置可以同时做self attention得到一个注意力值z),可以同时获取所有位置的输出以及loss(无论是双向的encoder,还是单向的mask decoder,注:这里指的是训练阶段,预测阶段mask decoder肯定是串行的。),效率更高。
transformer在机器翻译应用上的动态图:
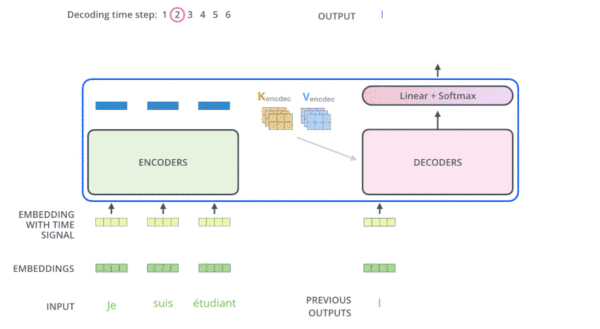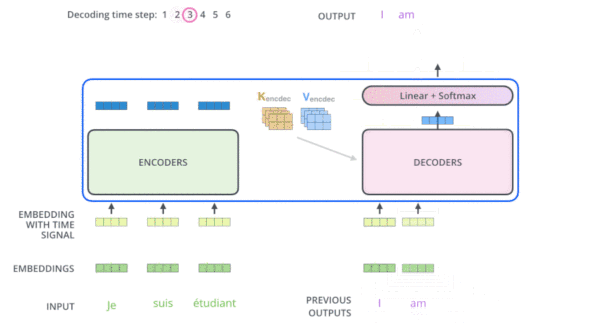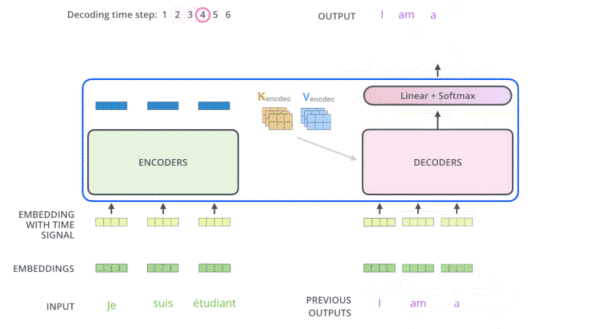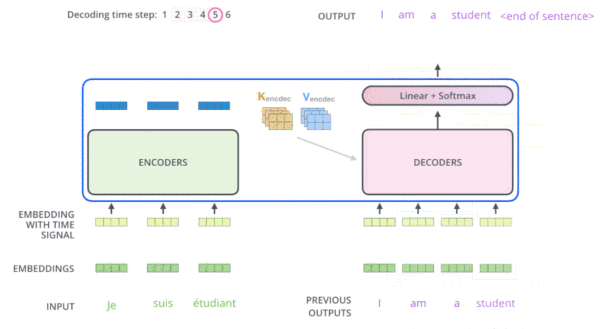
FrameWork
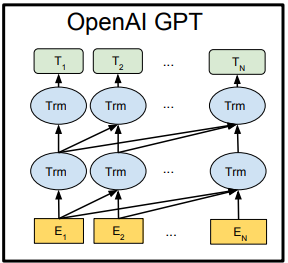
上图中,每一层的所有Trm属于一个自左向右的单向transformer,故在embedding输入和上一层的输出到下一层的输入时,都会做self attention操作,而这个self attention操作相当于当前位置cell会结合上一层所有位置的状态信息,这样就相当于双向连接了,因此需要乘以一个mask矩阵,用来屏蔽当前位置后面的位置的隐藏层状态信息。这是transformer decoder的一个关键。可看代码:
def mask_attn_weights(w):
n = shape_list(w)[-1]
b = tf.matrix_band_part(tf.ones([n, n]), -1, 0)## 下三角
b = tf.reshape(b, [1, 1, n, n])
w = w*b + -1e9*(1-b)
return w
如果不做这样的一个屏蔽操作,那么就变成双向的了。
分两步走,第一步:利用海量无标签的样本集预训练一个语言模型;第二步:利用预训练后的模型通过fine-tuning迁移到有监督的任务上。
无监督的预训练
利用大量的无监督语料库训练一个语言模型,其训练的目标函数(MLE)如下:
L
1
(
μ
)
=
∑
i
l
o
g
P
(
μ
i
∣
μ
i
−
k
,
.
.
.
,
μ
i
−
1
;
θ
)
(1)
L_1(\mu) = \sum_ilog P(\mu_i|\mu_{i-k},...,\mu_{i-1};\theta)\tag 1
L1(μ)=i∑logP(μi∣μi−k,...,μi−1;θ)(1)
在本论文的语言模型中,我们不采用RNN或LSTM,而是采用深层的transformer decoder(Masked):
h
0
=
U
W
e
+
W
p
(2)
h_0=UW_e+W_p \tag 2
h0=UWe+Wp(2)
h
l
=
t
r
a
n
s
f
o
r
m
e
r
_
b
l
o
c
k
(
h
l
−
1
)
∀
i
∈
[
1
,
n
]
(3)
h_l=transformer\_block(h_{l-1}) \forall i \in[1, n] \tag 3
hl=transformer_block(hl−1)∀i∈[1,n](3)
P
(
μ
)
=
s
o
f
t
m
a
x
(
h
n
W
e
T
)
(4)
P(\mu)=softmax(h_nW_e^T) \tag 4
P(μ)=softmax(hnWeT)(4)
上式中, U U U 表示要输入的 t o k e n token token, W e W_e We表示 t o k e n E m b e d d i n g token\ Embedding token Embedding 矩阵(所以注意公式2和公式4乘以了 W e W_e We 和 W e T W_e^T WeT), W p W_p Wp表示 p o s i t i o n e m b e d d i n g position\ embedding position embedding 矩阵, n n n 表示transformer_block个数,也就是网络深度。得出的 P ( μ ) P(\mu) P(μ) 表示在词表上概率分布。
有监督的fine-tuning
上述无监督的语言模型经过公式
1
1
1 的预训练后,我们将该模型参数作为初始参数应用到一些特定的有监督任务上。例如对于有标签的数据集
C
C
C,我们利用网络中最后一个
t
r
a
n
s
f
o
r
m
e
r
_
b
l
o
c
k
transformer\_block
transformer_block的输出
h
l
m
h_l^m
hlm 做如下处理:
P
(
y
∣
x
1
,
.
.
.
,
x
m
)
=
s
o
f
t
m
a
x
(
h
l
m
W
y
)
P(y|x^1,...,x^m)=softmax(h_l^mW_y)
P(y∣x1,...,xm)=softmax(hlmWy)
最大化下面目标函数:
L
2
(
C
)
=
∑
(
x
,
y
)
l
o
g
P
(
y
∣
x
1
,
.
.
.
,
x
m
)
L_2(C)=\sum_{(x,y)}logP(y|x^1,...,x^m)
L2(C)=(x,y)∑logP(y∣x1,...,xm)
W
y
W_y
Wy 是模型需要学习的参数。
论文中提到,先以无监督的预训练作为对有监督fine-tuning的辅助,有如下好处:
- 提高了有监督模型的泛化能力
- 加速收敛
综上,模型的目标函数如下:
L
3
(
C
)
=
L
2
(
C
)
+
λ
∗
L
1
(
C
)
(4)
L_3(C) = L_2(C) + \lambda * L_1(C) \tag 4
L3(C)=L2(C)+λ∗L1(C)(4)
注意上式中的
L
1
L_1
L1中的
μ
\mu
μ 变成了C。
特定任务的输入变换
首先需要将结构化的输入文本转换成有序的序列文本输入,这样预训练的无监督模型才能接受。注意式4中的 L 1 L_1 L1中的 μ \mu μ 变成了 C C C,也就是无监督预训练和有监督训练的语料是同一个,只不过在预训练时,只是将结构化文本变成有序的序列文本训练出了一个语言模型。
对于不同的任务做不同的处理如下:
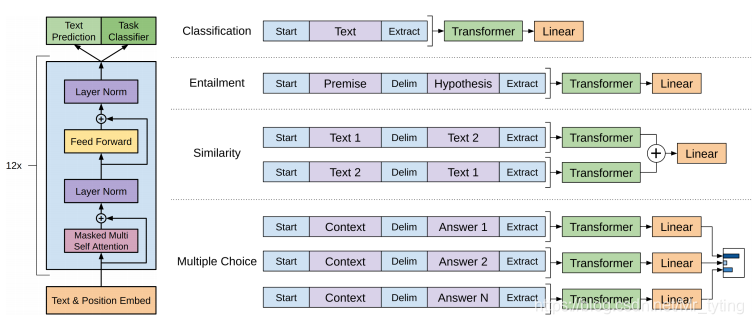
上图中的Delim表示分隔符,论文中是’$’,为的是将结构化文本转变成序列文本。
实验分析
论文实验部分,对比了在多个NLP任务上,该方法与当前的state-of-art方法的实验结果,验证了论文所提方法的有效性。
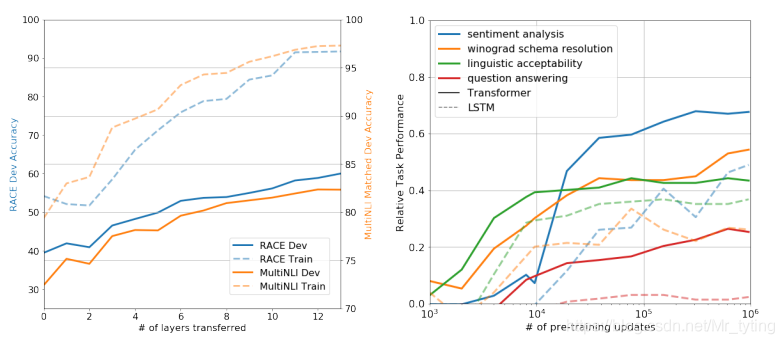
上面左图显示了预训练模型越深对目标任务效果越好。右图显示了预训练迭代次数越多,则模型在多个任务上的表现越好。
关键代码
def clf(x, ny, w_init=tf.random_normal_initializer(stddev=0.02), b_init=tf.constant_initializer(0), train=False):
with tf.variable_scope('clf'):
nx = shape_list(x)[-1]
w = tf.get_variable("w", [nx, ny], initializer=w_init)
b = tf.get_variable("b", [ny], initializer=b_init)
return tf.matmul(x, w)+b
def model(X, M, Y, train=False, reuse=False):
with tf.variable_scope('model', reuse=reuse):
we = tf.get_variable("we", [n_vocab+n_special+n_ctx, n_embd], initializer=tf.random_normal_initializer(stddev=0.02))
we = dropout(we, embd_pdrop, train)
X = tf.reshape(X, [-1, n_ctx, 2])
M = tf.reshape(M, [-1, n_ctx])
h = embed(X, we)
for layer in range(n_layer):
h = block(h, 'h%d'%layer, train=train, scale=True)
lm_h = tf.reshape(h[:, :-1], [-1, n_embd]) ##得到最后一个block的输出, 也就是上面所说的$h_l^m$
lm_logits = tf.matmul(lm_h, we, transpose_b=True)
lm_losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=lm_logits, labels=tf.reshape(X[:, 1:, 0], [-1])) ## 注意看预训练的语言模型的label只是将x向后移了一步
lm_losses = tf.reshape(lm_losses, [shape_list(X)[0], shape_list(X)[1]-1])
lm_losses = tf.reduce_sum(lm_losses*M[:, 1:], 1)/tf.reduce_sum(M[:, 1:], 1) ## 得到预训练模型的损失函数
clf_h = tf.reshape(h, [-1, n_embd]) // h 为transformer中最后一个block的输出
pool_idx = tf.cast(tf.argmax(tf.cast(tf.equal(X[:, :, 0], clf_token), tf.float32), 1), tf.int32)
clf_h = tf.gather(clf_h, tf.range(shape_list(X)[0], dtype=tf.int32)*n_ctx+pool_idx)
clf_h = tf.reshape(clf_h, [-1, 2, n_embd])
if train and clf_pdrop > 0:
shape = shape_list(clf_h)
shape[1] = 1
clf_h = tf.nn.dropout(clf_h, 1-clf_pdrop, shape)
clf_h = tf.reshape(clf_h, [-1, n_embd])
clf_logits = clf(clf_h, 1, train=train) ## 执行 上面公式中$softmax(h_l^m *W_y)$
clf_logits = tf.reshape(clf_logits, [-1, 2])
clf_losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=clf_logits, labels=Y) ## 得到监督学习的损失函数
return clf_logits, clf_losses, lm_losses
最终的loss函数:
train_loss = tf.reduce_mean(clf_losses) + lm_coef*tf.reduce_mean(lm_losses)














 7372
7372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









