









博客内容将首发在微信公众号"跟我一起读论文啦啦",上面会定期分享机器学习、深度学习、数据挖掘、自然语言处理等高质量论文,欢迎关注!

本文将总结ICLR2018论文:DEEP TEMPORAL CLUSTERING: FULLY UNSUPERVISED LEARNING OF TIME-DOMAIN FEATURES,论文链接DTC,参考的论文代码 DeepTemporalClustering,本论文方法是完全针对时序数据的无监督聚类算法,是第一次提出在无标签的时序数据上,建立了一个端到端的深度学习算法框架。
论文动机以及创新点
-
不同于一般的静态数据,时序数据内样本某时刻的状态变化会与之前后时刻状态相关,例如天气数据、语言数据等等,那么如何捕捉到这种变化规律非常重要,往往需要结合前后时刻状态去分析。
-
深度学习在有标签数据集上取得了巨大的成功,相对而言,复杂、高阶的结构化、多特征的无标签数据则获得较少的关注,对于该类无监督数据,传统的做法是利用某种相似度衡量算法去进行聚类,例如K-means、层次聚类等等,但是这些普通的聚类算法只是在静态数据上取得了较好的效果,对于时序数据不是很适用。
-
对时序数据的无监督聚类,主要有两个难点
① 以何种方式对序列数据进行降维,因为每个样本是有时间步长的,普通的静态数据集是二维的[batch_size, feature_nums],而时序数据集是三维的[batch_size, time_step, feature_num],如何降低维度变的至关重要。
② 对降维后的样本进行何种相似度的计算也非常重要,对最后的聚类效果有着决定性影响。 -
本论文提出了一个新的方法,Deep temporal Clustering(DTC),首先会利用可训练的深度自编码,将输入的序列数据映射到低纬度的隐空间,然后利用K-mean或层次聚类算法对映射后的向量进行聚类,并且可根据聚类后的分布,反向的更新神经网络参数和聚类中心。故这里面是有两个方向的训练,其自编码的损失函数采用MSE,聚类的损失函数采用KL散度(这点需要注意,因为是无监督的,但是论文根据hiton2015年论文,提出可以构造一个target distribution)。两者是联合训练的。
-
本论文还提出了可视化的方法,能以图形的方式展示序列哪个片段对该序列的聚类结果产生了影响,导致该序列样本被分到了该类,提高了模型的可解释性。
网络框架
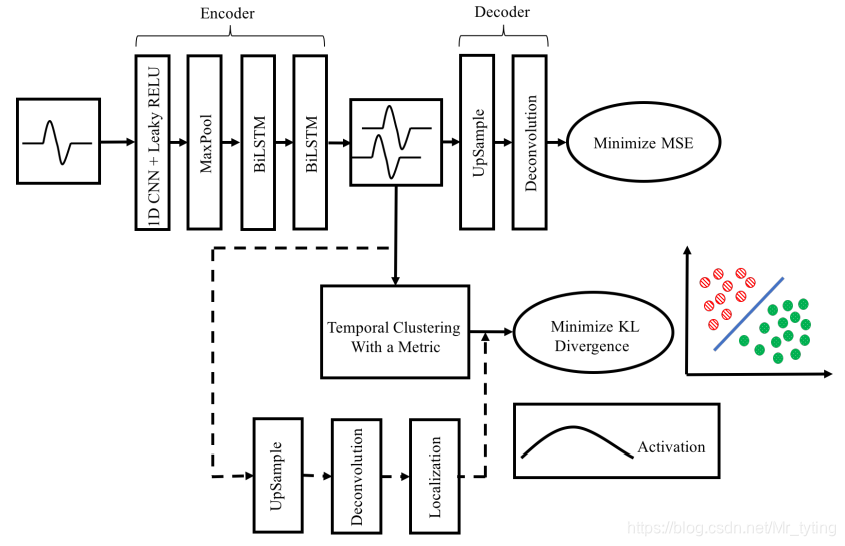
Effective Latent Representation
上图中上半部分,是一个深度自编码网络,网络的输入是一个个序列样本,其维度是[batch_size, time_step, feature_nums]
自编码模型
- 首先会让输入序列经过一维卷积核映射(自上向下一个方向做卷积),让其捕捉序列间短距离波动规律,然后在经过大小为P的max pooling操作,进行降维,期间使用的都是Leaky rectifying激活函数。经过以上的操作,我们可以将序列数据压缩成一个紧凑的向量表示,同时保留了序列间的结构化信息。这一点我认为是至关重要的,避免处理长序列数据导致最后效果很差。
- 再将max_pooling的输出结果输入到一个双向的LSTM网络中,LSTM网络能从两个方向学习序列间跨步长的变化规律,并且可以把输入序列压缩成更加紧凑的Latent Representation。
- 以上讲的是编码器结构,输入序列经过编码器的压缩,可以得到一个表征,但是这个表征效果如何呢?我们需要把这个表征反向还原成原始序列,然后自己跟自己训练,使得中间得到的表征效果能有保证。于是,我们对该表征进行UpSample和Deconvolution操作,其实就是反卷积操作,使之能重构输入序列,得到一个输出序列。
损失函数
我们以MSE为损失函数,不断的训练这个深度自编码网络,就能得到一个可信的Latent Representation,其形状为[batch_size, time_step2, feature_num2],其中 t i m e _ s t e p 2 < t i m e _ s t e p , f e a t u r e _ n u m 2 < f e a t u r e _ n u m time\_step2 < time\_step, feature\_num2 < feature\_num time_step2<time_step,feature_num2<feature_num。以下将这个Latent Representation简称为 z z z,第i个样本的Latent Representation称为 z i z_i zi
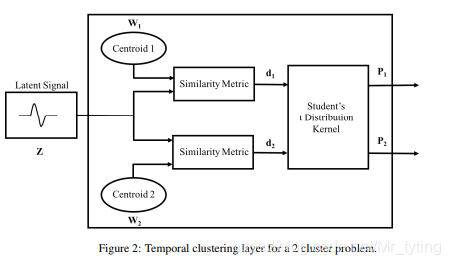
Temporal Clustering Layer
由以上步骤,我们得到了输入序列压缩后的Latent Representation,那么如何对这些Latent Representation进行聚类呢?
这里以K-mean举例(论文中说以层次聚类,但是我看论文明明是k-means),对Latent Representation进行聚类。
K-means聚类初始化
- 论文中提出,假设聚类结果有K个类别,以 w j w_j wj 表示第j类的中心,随机初始化k个聚类中心,然后以k-means方法更新一下聚类中心,注意这里的聚类中心 w w w其实就是聚类模型的参数,在实做时,就是形状如[k, time_step2, feature_num2]大小的参数矩阵。
- 那么我们得到了聚类中心了,如何计算每个样本距离每个中心的距离呢?
q i , j = ( 1 + s i m l ( z i , w j ) α ) − α + 1 2 ∑ j = 1 k ( 1 + s i m l ( z i , w j ) α ) − α + 1 2 q_{i,j}=\frac{(1+\frac{siml(z_i,w_j)}{\alpha})^{-\frac{\alpha+1}{2}}}{\sum_{j=1}^{k}{(1+\frac{siml(z_i,w_j)}{\alpha})}^{-\frac{\alpha+1}{2}}} qi,j=∑j=1k(1+αsiml(zi,wj))−2α+1(1+αsiml(zi,wj))−2α+1
上式的概率分布计算是由hinton在08年提出的 S t u d e n t ′ s t d i s t r i b u t i o n k e r n e l Student's\ t\ distribution\ kernel Student′s t distribution kernel。其中 q i , j q_{i,j} qi,j 表示 z i z_i zi 属于 w j w_j wj 的概率。其中 z i z_i zi 为第i个输入样本经过压缩后的表示。 s i m l ( z i , w j ) siml(z_i,w_j) siml(zi,wj) 表示相似度计算。论文中将 α \alpha α 设为1。其中论文中实验中试验了多种 s i m l ( z i , w j ) siml(z_i,w_j) siml(zi,wj) 有计算方式。具体计算方式请详看论文。 - 由此我们得到了一个概率分布 q q q。
聚类损失函数
因为我们这里是无监督的,即使得到了一个概率分布 q q q,也不知道真实的概率分布 p p p,论文中提到可以利用论文A fast learning algorithm for deep belief nets 和论文 unsupervised deep embedding for clustering analysis 中的方法,可以有 q q q 分布得到target distribution: p i , j = q i , j 2 / f i ∑ j = 1 k q i j 2 / f i p_{i,j}=\frac{q_{i,j}^{2}/f_i}{\sum_{j=1}^{k}q_{ij}^{2}/f_{i}} pi,j=∑j=1kqij2/fiqi,j2/fi
其中
f
i
=
∑
i
=
1
n
q
i
j
f_i = \sum_{i=1}^{n}q_{ij}
fi=∑i=1nqij,具体细节请参考上面两篇论文。
由此我们可以计算这两种分布的KL散度,作为损失函数。
L
=
∑
i
=
1
n
∑
j
=
1
k
p
i
j
l
o
g
p
i
j
q
i
j
L=\sum_{i=1}^n\sum_{j=1}^kp_{ij}log\frac{p_{ij}}{q_{ij}}
L=i=1∑nj=1∑kpijlogqijpij
这样聚类模型在训练时可以反向更新聚类中心 w w w 和自编码的编码器参数。
可视化与可解释性
因为深度神经网络如同一个黑盒一般,比较难解释聚类的结果,因此论文提出了heatmap,用来可视化的展示。
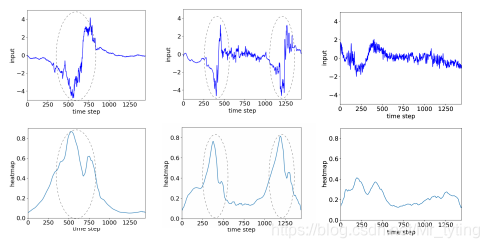
我们可以根据heatmap可视化的定位到导致聚类结果的event,例如上图最左边的图中发生了一个event,中间的图发生了两次的event,最右边的没有发生。DTC模型可以完全无监督的学习到这些规律,从来对这些序列进行聚类。具体这些事如何实现的,请参考上面的代码链接。
实验分析
数据集
- 使用了UCR Time series Classification datasets,这是专门针对时序处理的一系列时序数据集。
- 航空相关的时序数据集,取自NASA的航空磁强计记录的数据。
Baseline Model
当前处理时序无监督聚类的state of art 论文,K-shape
评价指标
数据集是有标签的,但是整个模型训练过程完全无监督,采用AUC作为评价指标。
实验结果
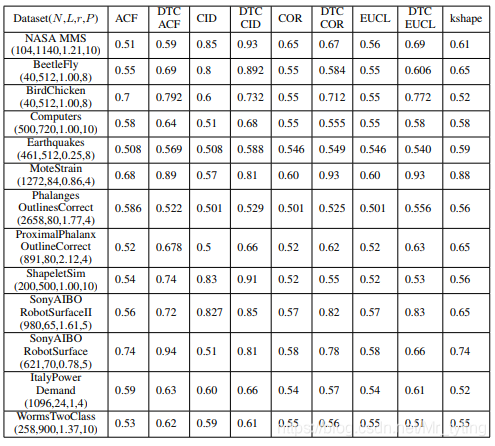
-
上图中的N表示样本数量,L表示样本的步长,r表示实际正样本与负样本数量比,p表示自编码模型中pooling size大小。ACF,CID,COR,EUCL表示不同的 s i m l ( z i , w j ) siml(z_i,w_j) siml(zi,wj) 的相似度计算方式。可以看出我们的DTC ACF、DTC CID、DTC COR、DTC EUCL模型在大多数数据集上要好于K-Shape模型。
-
另外也可以看出,大部分auc的值都不是很高,主要集中在0.5~0.7左右,在有些数据集上只有0.5多一点,比猜好一些而已,所以无监督算法到底靠不靠谱真的不好说
个人小结
- 在训练时自编码模型和聚类模型是同时训练的,也就是论文中提到的jointly optimizes。但是在实做时,可以先预训练自编码模型,然后再与聚类模型联合训练,效果可能更好。
- 本论文提出的网络结构,其实很常见,许多有关深度学习的论文都是如此套路,见怪不怪,只是首次运用到时序数据的无监督聚类上,的确有一番新意,实际业务应用效果如何呢,尚未可知。














 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









