



随着计算机视觉领域的快速发展,图像分割技术在众多应用中发挥着越来越重要的作用。分割一切模型(Segment Anything Model, SAM)作为一种先进的图像分割技术,旨在实现对各种对象的自动分割,展现出卓越的灵活性和准确性。图像分割不仅限于传统的场景分析,还扩展至遥感图像处理,后者通过卫星或飞机等平台获取的高分辨率图像被广泛应用于环境监测、城市规划和农业评估等领域。然而,源域与目标域之间的域差距常常导致模型性能下降,因此,解决域适应问题成为提高模型泛化能力的关键。
为了应对自然图像之间的差距,我们总结了四种基于SAM的技术点改进。
论文1
PointSAM: Pointly-Supervised Segment Anything Model for Remote Sensing Images
方法:
利用 SAM 的零样本功能,我们采用了一种自训练框架,该框架迭代生成伪标签进行训练。但是,如果伪标签包含噪声标签,则存在错误累积的风险。为了解决这个问题,我们从目标数据集中提取目标原型,并使用匈牙利算法将它们与预测原型进行匹配,以防止模型朝错误的方向学习。此外,由于 RSI 中的背景复杂且物体分布密集,使用点提示可能会导致多个物体被识别为一个。为了解决这个问题,我们提出了一种基于实例掩码不重叠性质的负提示校准方法。简而言之,我们使用重叠掩码的提示作为相应的负信号,从而得到精细的掩码。结合上述方法,我们提出了一种新的点监督分割一切模型,名为 PointSAM。
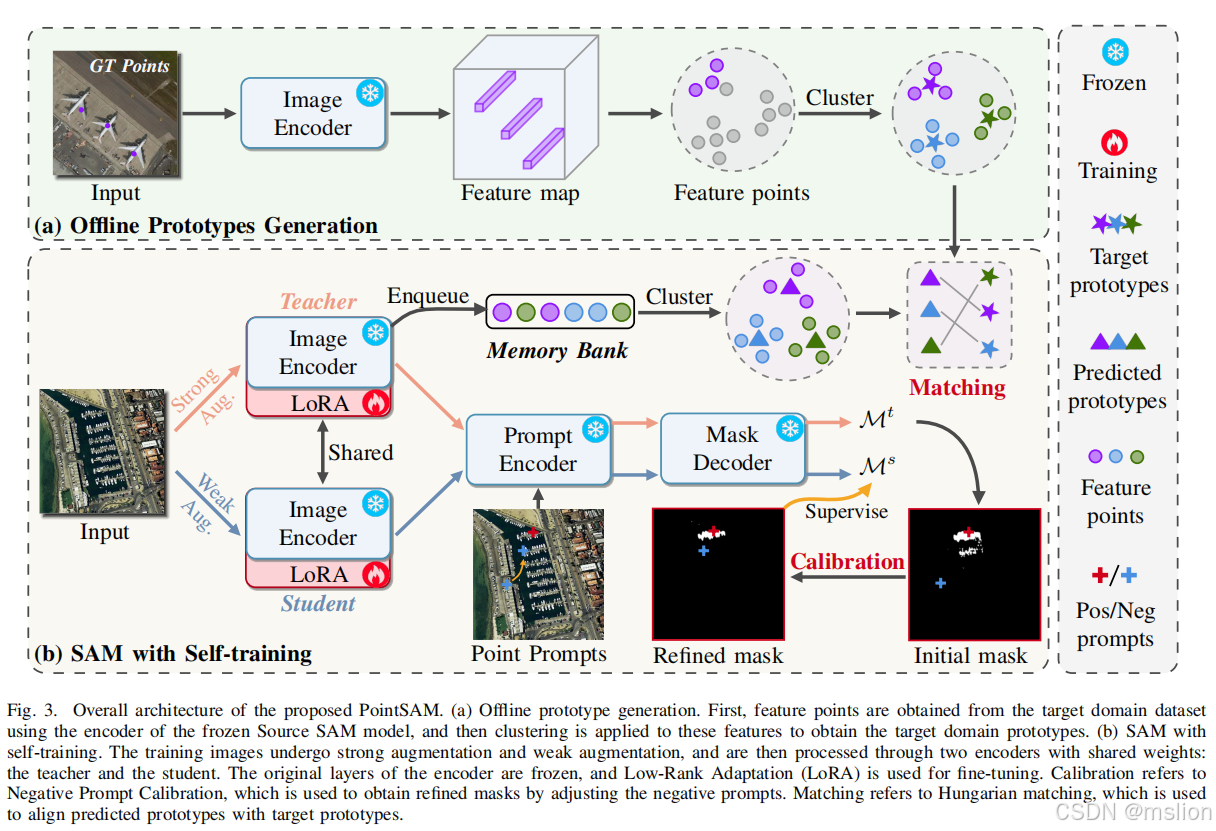
创新点:
(1)我们引入了基于原型的正则化(PBR),它在实例级别对齐源模型和目标模型的特征,利用动态原型更新和匈牙利算法来提高模型泛化能力。
(2)我们开发了负提示校准(NPC),它在训练过程中自适应地调整负提示,提高了密集场景ios中预测掩模的准确性。
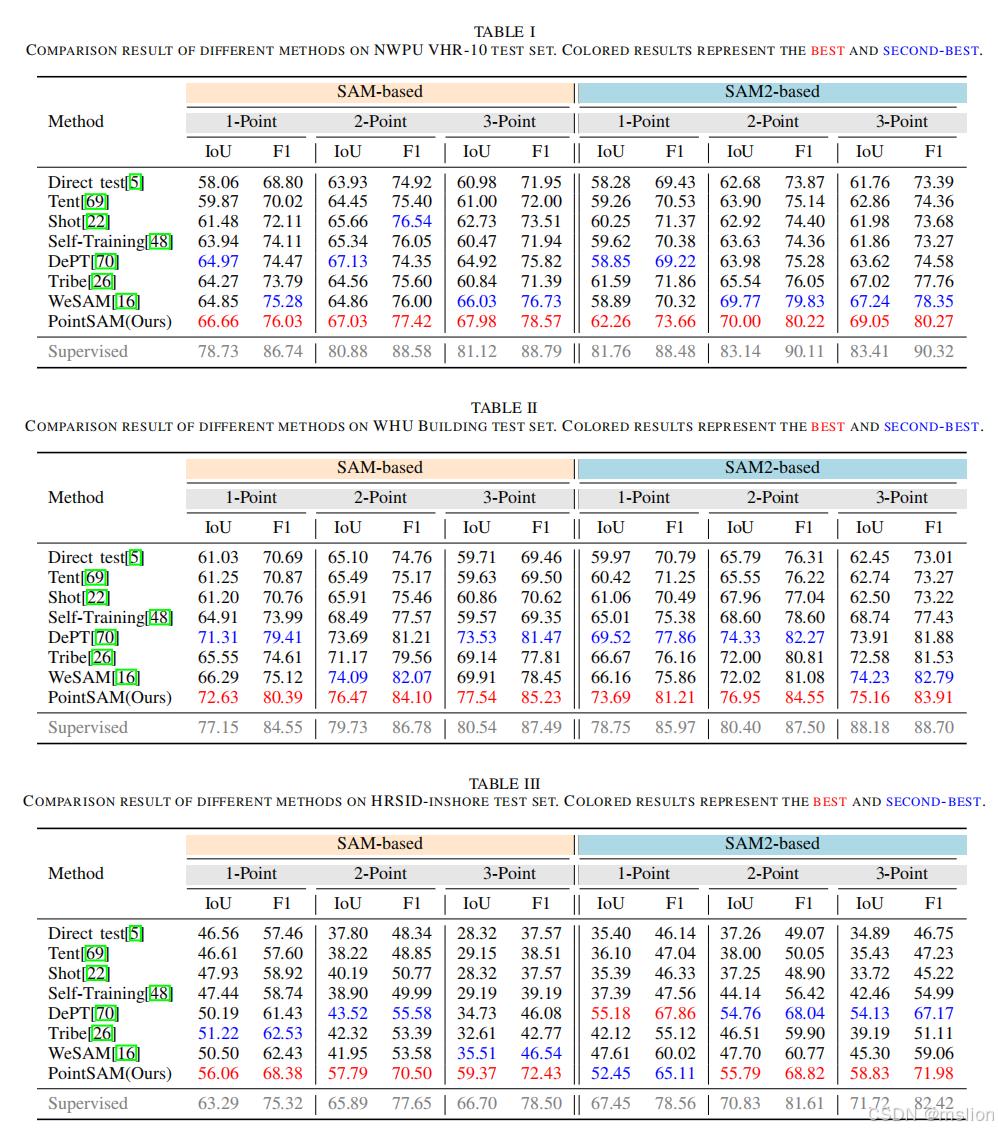
(3)我们通过对三个RSI 数据集(NWPU VHR-10、WHU 和HRSID)进行大量实验证明了PointSAM 的有效性,显示了点监督下分割性能的显着改进。此外,我们将 PointSAM 的应用扩展到面向点监督的对象检测任务中的边界框生成,展示了其多功能性以及在基于点的监督学习场景中更广泛使用的潜力。
结果:
论文2
Bootstrap Segmentation Foundation Model under Distribution Shift via Object-Centric Learning
方法:
我们引入了 SlotSAM,这是一种以自我监督的方式重建编码器特征以创建以对象为中心的表示的方法。然后将这些表示集成到基础模型中,增强其对象级感知能力,同时减少与分布相关的变量的影响。SlotSAM 的优点在于其简单性和对各种任务的适应性,使其成为一种多功能解决方案,可显着增强基础模型的泛化能力。
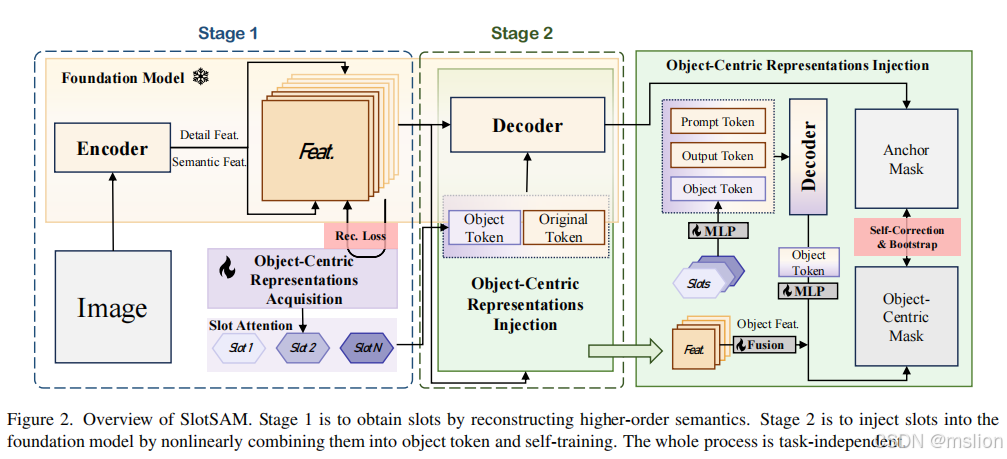
创新点:
(1)引入Bootstrap方法:论文中使用了Bootstrap策略来增强模型的鲁棒性,尤其是在处理分布变化时。这种方法通过重新采样和生成多样本,帮助模型更好地适应不同的数据分布。
(2)物体中心学习:研究者提出了物体中心的学习方法,强调对图像中各个物体的识别和分割。这种方法不仅关注全局特征,还能增强对局部特征的学习,从而提高分割的精确度。
(3)分布变化下的适应性:论文特别关注如何在训练和测试阶段数据分布不同的情况下进行有效的图像分割。通过设计新的损失函数和训练策略,模型能够在面对未知分布时保持较高的性能。
结果:
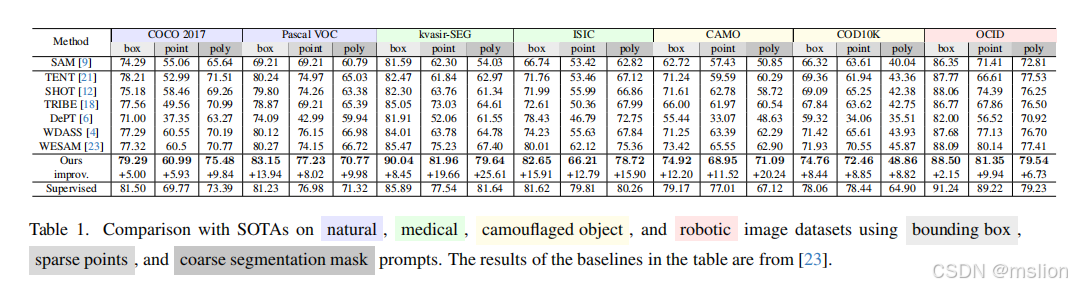
论文3
CAT-SAM: Conditional Tuning for Few-Shot Adaptation of Segment Anything Model
方法:
我们提出了 CAT-SAM,这是一种 ConditionAl Tuning 网络,它以数据高效的方式探索 SAM 对各种具有挑战性的下游领域的少量适应性。核心设计是一个即时桥结构,可以实现重量级图像编码器和轻量级掩模解码器的解码器条件联合调整。桥接将掩模解码器的特定领域特征映射到图像编码器,促进两个组件的协同适应,仅与少量目标样本互惠互利,最终在各种下游任务中实现卓越的分割。
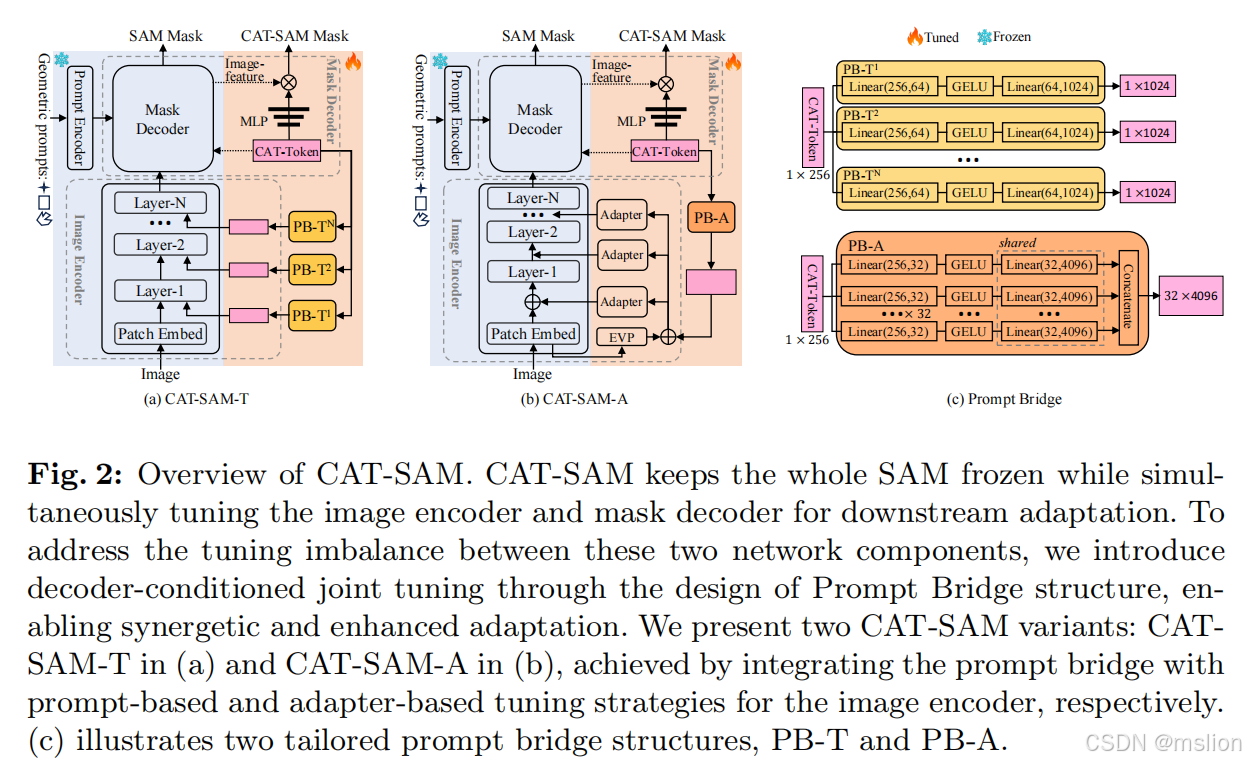
创新点:
(1)这项工作的主要贡献可以概括为三个方面。首先,我们提出了 CAT-SAM,这是一种条件调整网络,可以使 SAM 有效且数据高效地适应各种具有挑战性的下游领域。
(2)我们在 CAT-SAM 中设计了即时桥,这是一种解码器条件联合调谐结构,可以有效地实现重量级图像编码器和轻量级掩模解码器的协同和数据高效适应。
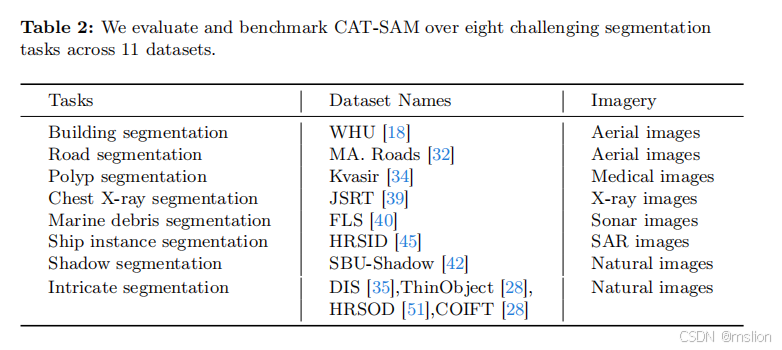
(3)其次,我们通过将提示桥嵌入到两种代表性的调整策略中来开发两种 CAT-SAM 变体,一种在输入空间中引入可学习的提示标记,另一种插入轻量级适配器网络。第三,对 11 个不同分割数据集的大量实验表明,即使在具有挑战性的一次性设置下,CAT-SAM 也能始终如一地实现卓越的图像分割。
结果:
论文4
Improving the Generalization of Segmentation Foundation Model under Distribution Shift via Weakly Supervised Adaptation
方法:
我们开发了一种基于自我训练的策略,使 SAM 适应目标分布。考虑到源数据集大、计算成本高和伪标签不正确的独特挑战,我们提出了一种具有锚正则化和低秩微调的弱监督自训练架构,以提高适应的鲁棒性和计算效率。
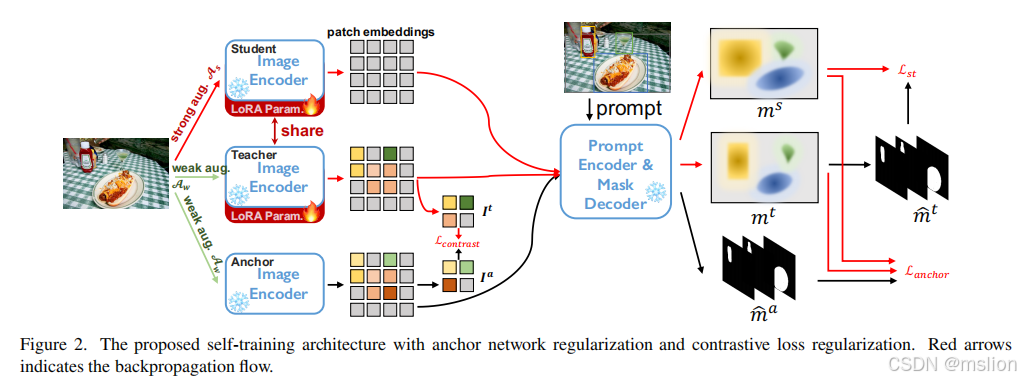
创新点:
(1)弱监督适应方法:文章提出了一种新的弱监督适应框架,该框架能够在仅使用少量标注数据的情况下,提升模型在目标领域的表现。这种方法有效利用未标注数据,通过自适应学习来缓解因分布变化造成的性能下降。
(2)适应性损失函数:研究者设计了一种新的损失函数,专门用于处理分布转移带来的挑战。该损失函数不仅考虑了分割的准确性,还能够增强模型对不同域的适应能力,从而提高泛化性能。
(3)领域不变特征提取:文章强调通过提取领域不变的特征来增强模型的鲁棒性。这一方法帮助模型在面对未见数据时,保持较好的分割性能,减少对特定域的依赖。
结果:
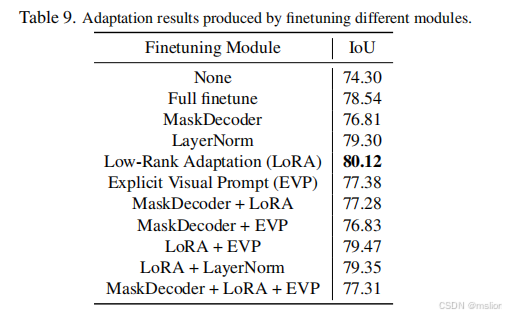

















 1731
1731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









