






Diffusion模型近年来在时间序列预测领域引起了广泛关注。这类模型最初用于生成高质量图像,但其独特的建模能力和对复杂数据分布的捕捉能力使其逐渐应用于时间序列预测中。Diffusion模型通过逐步添加噪声到数据,并学习逆过程,有效地捕捉时间序列中的潜在模式和趋势。这种方法不仅可以处理具有高维特征的数据,还能够增强模型对时间序列中不确定性的适应性。与传统时间序列预测方法相比,Diffusion模型能够更好地捕捉数据的非线性和复杂性。随着研究的深入,许多学者开始探索Diffusion模型在不同应用场景中的潜力,涵盖金融市场、交通流量、气象预测等多个领域。
此外,Diffusion模型的灵活性使其适合于与其他深度学习技术结合,进一步提升预测的准确性和鲁棒性。以下将介绍四篇应用Diffusion模型于时间序列预测的相关论文,展示这些模型如何为解决实际问题提供新的视角和方法,以及它们在各自领域中的创新应用。
论文1
CSDI: Conditional Score-based Diffusion Models for Probabilistic Time Series Imputation
方法:
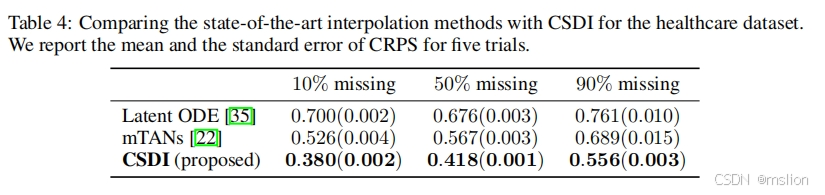
时间序列中缺失值的填补在医疗保健和金融领域有许多应用。虽然自回归模型是时间序列填补的自然候选者,但基于分数的扩散模型最近在许多任务(例如图像生成和音频合成)中的表现优于现有的同类模型(包括自回归模型),并且有望成为时间序列填补的有力工具。在本文中,我们提出了基于条件分数的填补扩散模型 (CSDI),这是一种新颖的时间序列填补方法,它利用基于观察数据的基于分数的填补模型。与现有的基于分数的方法不同,条件扩散模型是专门为填补而训练的,可以利用观察值之间的相关性。在医疗保健和环境数据上,CSDI 在流行的性能指标上比现有的概率填补方法提高了 40-65%。此外,与最先进的确定性填补方法相比,CSDI 的确定性填补将误差降低了 5-20%。此外,CSDI 还可应用于时间序列插值和概率预测,并且与现有基线具有竞争力。
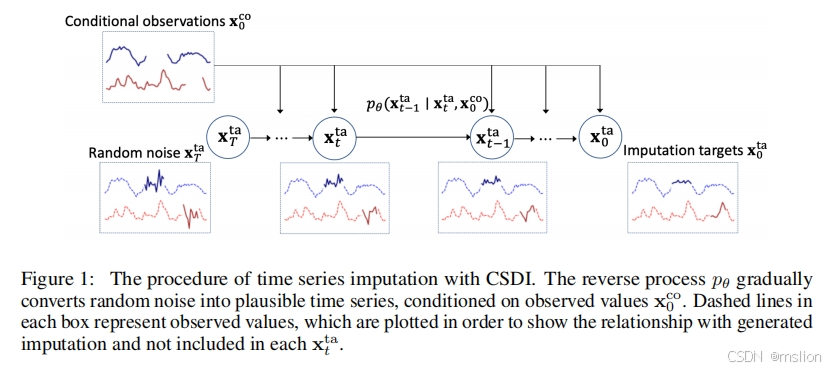
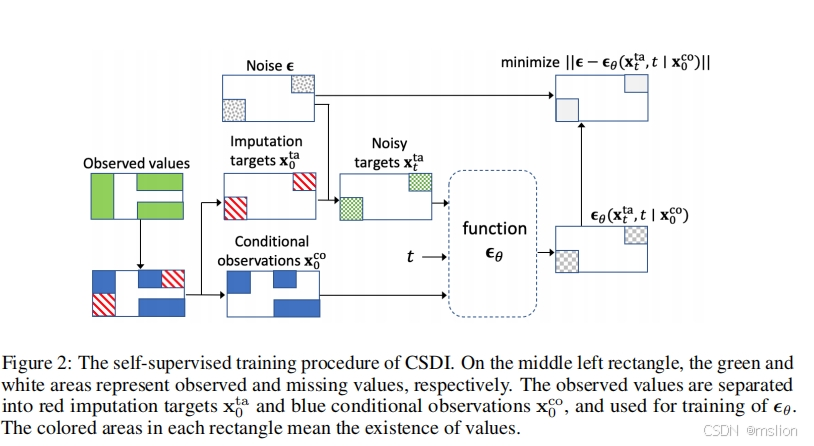
创新点:
(1)我们提出了基于条件分数的概率插补扩散模型 (CSDI),并实现了 CSDI 进行时间序列插补。为了训练条件扩散模型,我们开发了一种自监督训练方法。
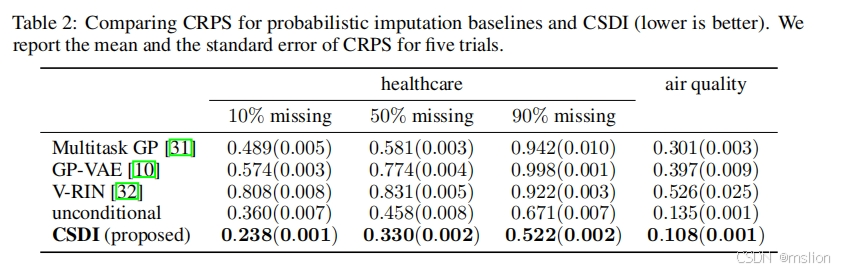
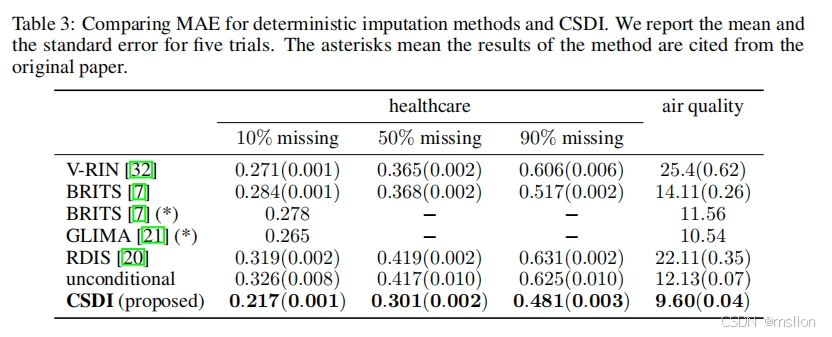
(2)我们通过实证研究证明,CSDI 在医疗保健和环境数据上比现有的概率方法将连续排序概率分数 (CRPS) 提高了40-65%。此外,与为确定性插补开发的最先进的方法相比,使用 CSDI 进行确定性插补可将平均绝对误差 (MAE) 降低 5-20%。
(3)我们证明 CSDI 也可以应用于时间序列插值和概率预测,并且与为这些任务设计的现有基线具有竞争力。
结果:

论文2
Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting
方法:
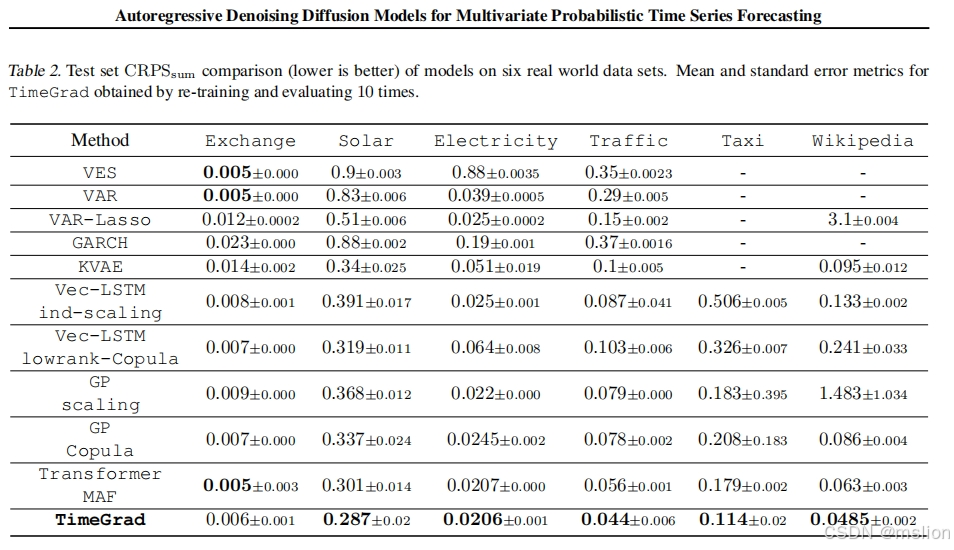
在本研究中,我们提出了 TimeGrad,这是一种用于多元概率时间序列预测的自回归模型,它通过估计其梯度在每个时间步骤中从数据分布中抽样。为此,我们使用扩散概率模型,这是一类与分数匹配和基于能量的方法密切相关的潜变量模型。我们的模型通过优化数据似然的变分界限来学习梯度,并在推理时通过朗之万采样的马尔可夫链将白噪声转换为感兴趣分布的样本。我们通过实验证明,所提出的自回归去噪扩散模型是具有数千个相关维度的真实世界数据集上新的最先进的多元概率预测方法。我们希望这种方法对从业者来说是一个有用的工具,并为该领域的未来研究奠定基础。
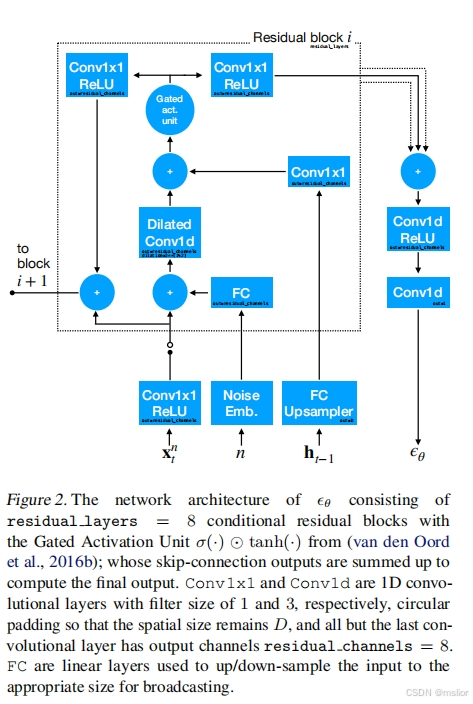
创新点:
(1)在这项工作中,我们提出了自回归 EBM,通过我们称为 TimeGrad 的模型来解决多元概率时间序列预测问题,并表明我们不仅能够使用概率时间序列预测的所有归纳偏差来训练这种模型,而且与其他现代方法相比,该模型的表现非常出色。
(2)这种自回归-EBM 组合保留了自回归模型的强大功能,例如在推断未来方面具有良好的性能,同时具有 EBM 作为通用高维分布模型的灵活性,同时保持了计算上的可处理性。
结果:
论文3
DIFFUSION-TS: INTERPRETABLE DIFFUSION FOR GENERAL TIME SERIES GENERATION
方法:
去噪扩散概率模型 (DDPM) 正在成为生成模型的主要范例。它最近在音频合成、时间序列归纳和预测方面取得了突破。在本文中,我们提出了 Diffusion-TS,这是一种基于扩散的新型框架,它使用具有解缠结时间表示的编码器-解码器变换器生成高质量的多变量时间序列样本,其中分解技术引导 Diffusion-TS 捕捉时间序列的语义含义,而变换器从嘈杂的模型输入中挖掘详细的序列信息。与现有的基于扩散的方法不同,我们训练模型在每个扩散步骤中直接重建样本而不是噪声,结合基于傅里叶的损失项。Diffusion-TS 有望生成同时满足可解释性和真实性的时间序列。此外,结果表明,所提出的 Diffusion-TS 可以轻松扩展到条件生成任务,例如预测和归因,而无需任何模型更改。这也促使我们进一步探索 Diffusion-TS 在不规则设置下的性能。最后,通过定性和定量实验,结果表明 Diffusion-TS 在各种实际时间序列分析中取得了最先进的结果。
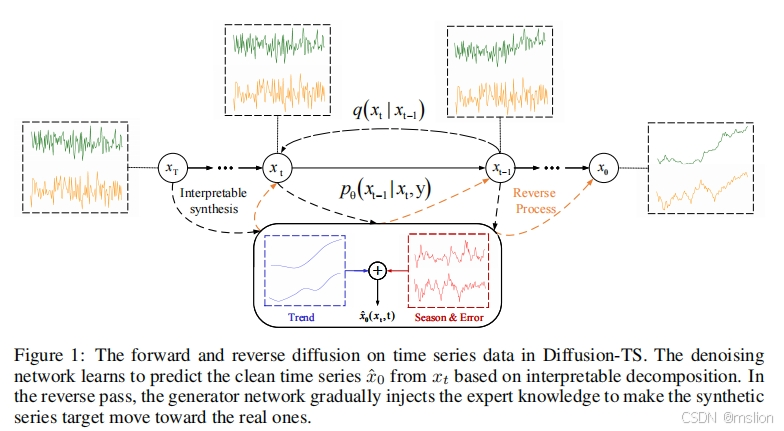
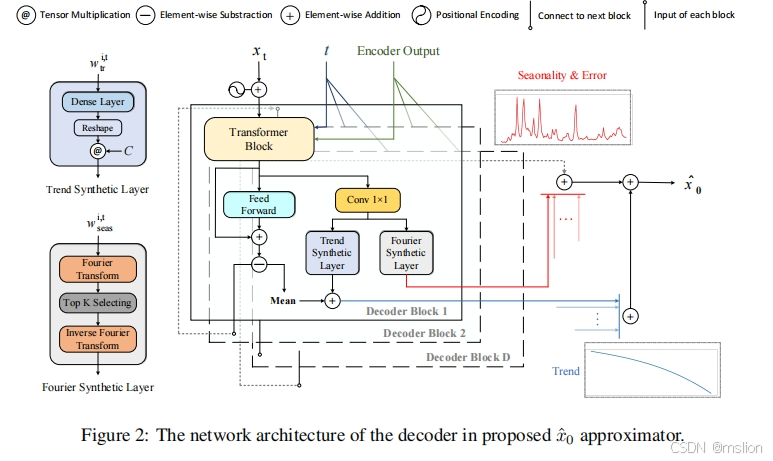
创新点:
(1)我们提出了一个名为 Diffusion-TS 的时间序列生成框架,它将季节性趋势分解技术与去噪扩散模型相结合。这是通过基于傅里叶的训练目标和深度分解架构的嵌入实现的。该框架允许模型从数据中学习有意义的时间属性,使其成为通用时间序列生成的高效且可解释的解决方案。
(2)对于条件生成,我们采用基于目标度量(例如重建)的实例感知指导策略,这使 Diffusion-TS 能够以即插即用的方式适应不同的可控生成任务。
(3)我们的实验表明,Diffusion-TS 可以在具有挑战性的环境下生成逼真的时间序列,同时保持高度的多样性和新颖性,并且与为下游应用设计的现有基于扩散的方法具有竞争力。我们还通过几个案例研究展示了该模型的可解释性。
结果:
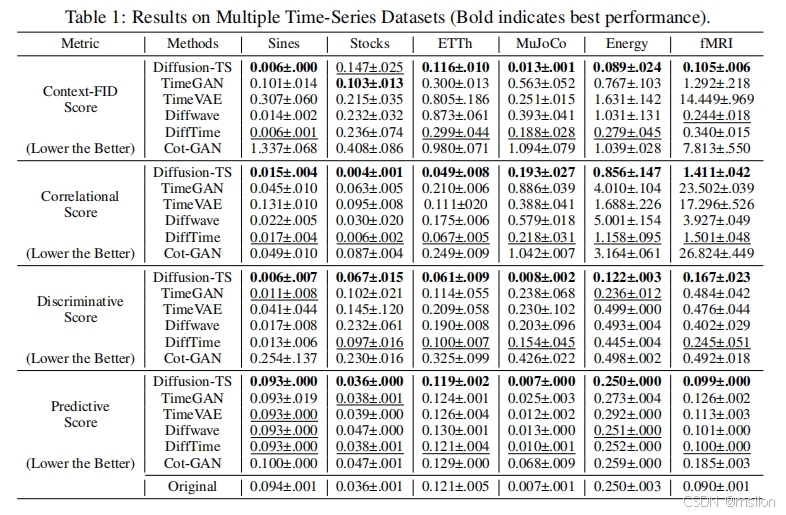
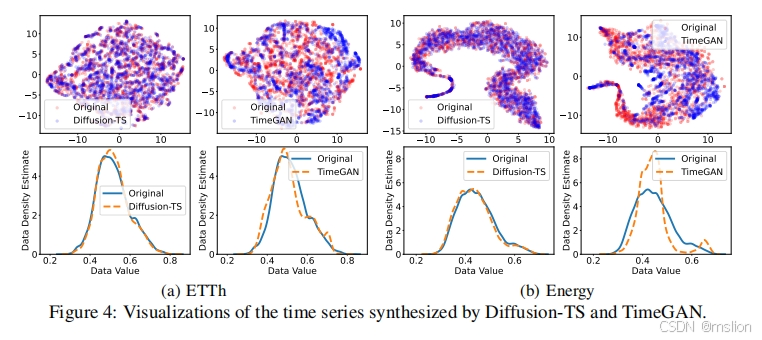
论文4
Diffusion-based Time Series Imputation and Forecasting with Structured State Space Models
方法:
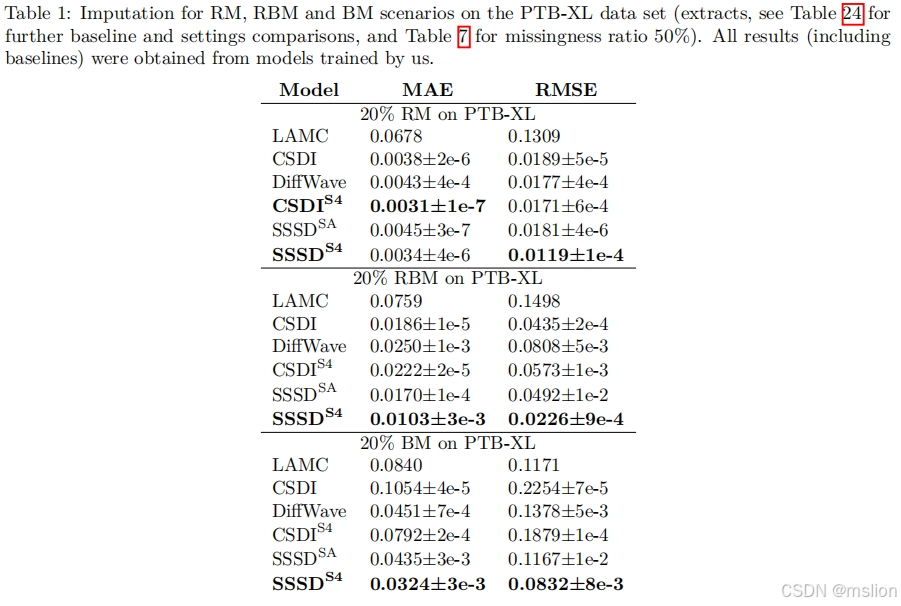
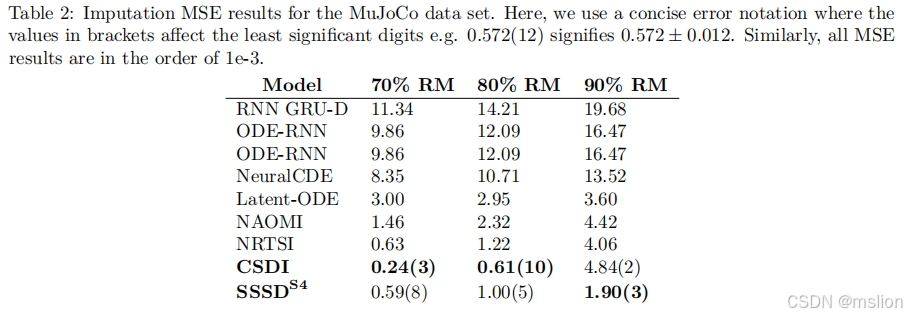
缺失值的填补是许多现实世界数据分析流程面临的重大障碍。在这里,我们专注于时间序列数据,并提出了 SSSD,这是一种依赖于两种新兴技术的填补模型,即(条件)扩散模型作为最先进的生成模型,结构化状态空间模型作为内部模型架构,特别适合捕获时间序列数据中的长期依赖关系。我们证明,SSSD 在广泛的数据集和不同的缺失场景中达到甚至超过最先进的概率填补和预测性能,包括具有挑战性的停电缺失场景,而之前的方法未能提供有意义的结果。
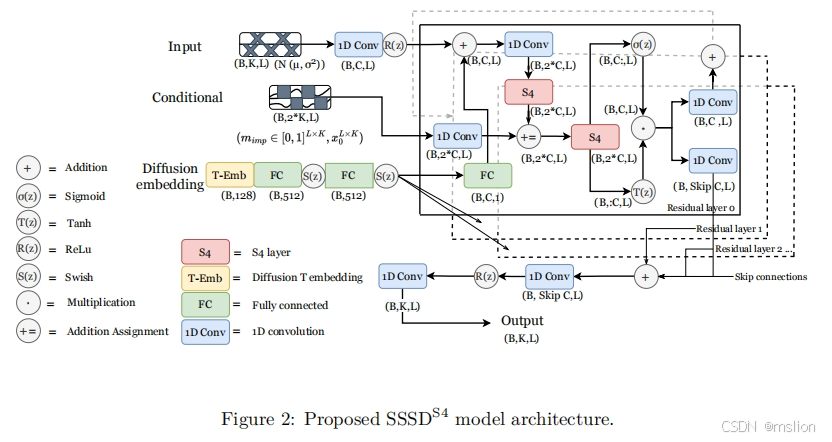
创新点:
(1) 我们提出了一种状态空间模型与(条件)扩散模型的组合,作为捕捉时间序列中长期依赖关系的理想构建块,作为当前最先进的生成建模技术。
(2) 我们建议对当代扩散模型架构 DiffWave(Kong 等人,2021 年)进行修改,以增强其时间序列建模能力。此外,我们提出了一种简单而强大的方法,其中扩散过程的噪声仅引入要插补的区域,事实证明,这优于在图像修复(Lugmayr 等人,2022 年)背景下提出的方法。
(3) 我们提供了广泛的实验证据,证明与各种缺失方法的不同数据集上的最新方法相比,所提出的方法具有优越性,特别是对于最具挑战性的停电和预测场景。
结果:

















 5948
5948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









