









自从 Google 于 2017 年提出 Transformer,它已成为 NLP 和生成式 AI 模型的主流架构,彻底颠覆了传统 RNN、CNN 结构的局限。Transformer 最大的创新点在于:完全基于注意力机制,无需循环与卷积,实现高效的并行训练和全局信息捕获。
本文将围绕四个维度全面拆解 Transformer:
-
原理解析:三种核心注意力机制
-
模块架构:编码器与解码器的层级结构
-
数据流向表:结构与计算路径总览
-
模拟代码框架:模块划分与伪代码演示
一、Transformer 模型架构
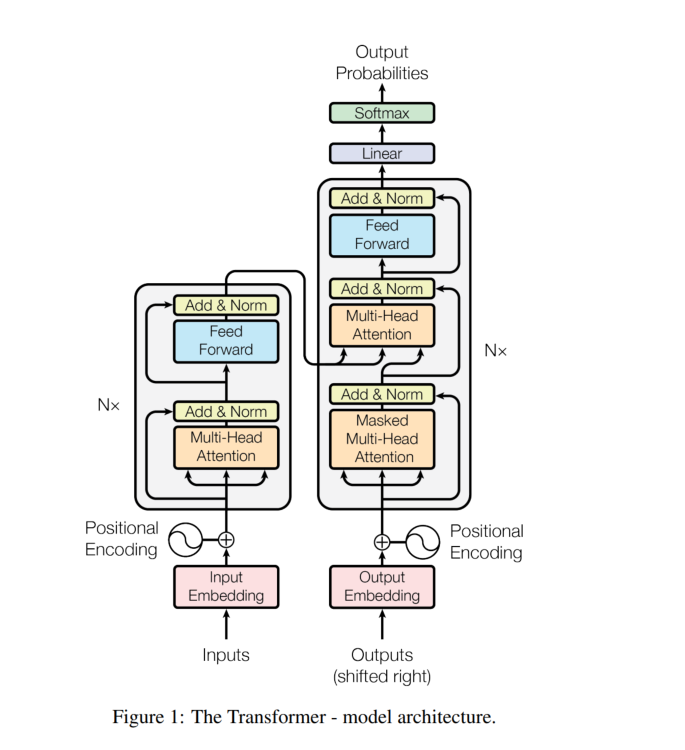
二、核心原理:注意力机制全解
Transformer 最核心的思想是 Attention is All You Need —— 注意力即一切。它使用注意力机制直接在输入序列的所有位置之间建立连接,从而有效建模长距离依赖。
✅三种关键注意力机制:
| 类型 | 使用位置 | Query 来源 | Key/Value 来源 | 是否 Mask | 用途说明 |
|---|---|---|---|---|---|
| 自注意力(Self-Attention) | 编码器 | 当前 token | 当前 token | ❌ 否 | 提取当前输入与上下文的关系 |
| 多头注意力(Multi-Head Attention) | 解码器 | 当前 token | 当前 token | ✅ 是 | 防止看到未来 token,保证生成顺序性 |
| 编码器-解码器注意力(融合注意力) | 解码器 | decoder token | encoder 输出 | ❌ 否 | 解码器融合编码器上下文信息 |
✅注意力机制公式

三、模块架构:编码器与解码器
Transformer 使用典型的 Encoder-Decoder 架构,每部分由若干重复层堆叠构成。
✅编码器结构(Encoder)
每层包括:
-
多头自注意力(Self-Attention)
-
残差连接 + LayerNorm
-
前馈网络(FFN)
-
残差连接 + LayerNorm
✅解码器结构(Decoder)
每层包括:
-
Masked 多头自注意力(防止信息泄露)
-
编码器-解码器注意力(融合上下文)
-
前馈网络(FFN)
-
每一步之后均使用残差连接 + LayerNorm
四、Transformer 数据流向总览表
| 阶段 | 输入数据 | 操作模块 | 输出数据 | 说明 |
|---|---|---|---|---|
| 1️⃣ 输入预处理 | Token ID 序列 x | 嵌入层 + 位置编码 | E(x) + PE | 融合语义与位置信息 |
| 2️⃣ 编码器处理 | E(x) + PE | 编码器(N 层):· 多头自注意力· 前馈网络· LayerNorm + 残差 | EncoderOutput | 每个 token 得到全局上下文表达 |
| 3️⃣ 解码器准备 | 目标偏移序列 y(如 <BOS> y1 y2) | 嵌入层 + 位置编码 | E(y) + PE | 准备进入解码器计算 |
| 4️⃣ 解码器处理 | E(y) + PE,EncoderOutput | 解码器(N 层):· Masked 自注意力· 编码器-解码器注意力· 前馈网络· LayerNorm + 残差 | DecoderOutput | 当前 token 依赖上下文和 encoder |
| 5️⃣ 输出层 | DecoderOutput | 线性变换 + Softmax | 预测分布 | 生成下一个 token 的概率分布 |
五、简要代码框架(PyTorch 风格伪代码)
以下为简化结构,帮助理解模块划分:
import torch
import torch.nn as nn
import math
# EncoderDecoder 类
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
def forward(self, src, tgt, src_mask, tgt_mask):
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
# Generator 类
class Generator(nn.Module):
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
def forward(self, x):
return torch.log_softmax(self.proj(x), dim=-1)
# Clones 函数
def clones(module, N):
return nn.ModuleList([module for _ in range(N)])
# Encoder 类
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
# LayerNorm 类
class LayerNorm(nn.Module):
def __init__(self, size, eps=1e-6):
super(LayerNorm, self).__init__()
def forward(self, x):
return x
# SublayerConnection 类
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
# EncoderLayer 类
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
# Decoder 类
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
# DecoderLayer 类
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
def forward(self, x, memory, src_mask, tgt_mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, memory, memory, src_mask))
return self.sublayer[2](x, self.feed_forward)
# MultiHeadedAttention 类
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
def forward(self, query, key, value, mask=None):
return self.attn
# PositionwiseFeedForward 类
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
def forward(self, x):
return self.w_2(self.dropout(torch.relu(self.w_1(x))))
# Embeddings 类
class Embeddings(nn.Module):
def __init__(self, vocab, d_model):
super(Embeddings, self).__init__()
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
# PositionalEncoding 类
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
def forward(self, x):
return x + self.pe[:, :x.size(1)]
# make_model 函数
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N),
nn.Sequential(Embeddings(src_vocab, d_model), c(position)),
nn.Sequential(Embeddings(tgt_vocab, d_model), c(position)),
Generator(d_model, tgt_vocab)
)
return model
六、模型推理
假设我们使用这个模型进行中文到英文的翻译任务。输入的中文句子是:“我在学习。” 我们希望模型生成相应的英文翻译。
步骤:
-
输入序列:我们将输入中文句子转换成模型的词汇索引表示。假设句子 "我在学习" 被映射成索引
[1, 2, 3]。 -
源序列掩码(src_mask):源序列掩码表示哪些词有效。对于该句子,
src_mask的大小是[1, 1, 1],表示所有词都有效。 -
目标序列初始化:目标序列
tgt初始化为一个全零的序列。假设目标词汇表中 "I" 对应的索引为 4,"am" 对应的索引为 5,"learning" 对应的索引为 6。 -
推理过程:
-
首先,
tgt初始化为[0](全零序列)。 -
在第一步,我们通过源序列
[1, 2, 3]和目标序列[0]进行推理,得到的输出会预测下一个词的概率。假设它预测的下一个词是 "I"(索引 4)。 -
目标序列现在变为
[0, 4]。 -
下一步,通过源序列
[1, 2, 3]和目标序列[0, 4]继续推理,得到的输出预测词 "am"(索引 5)。 -
目标序列更新为
[0, 4, 5]。 -
再次,通过源序列
[1, 2, 3]和目标序列[0, 4, 5]推理,得到预测词 "learning"(索引 6)。 -
目标序列更新为
[0, 4, 5, 6]。
-
-
结束推理:此时,目标序列已经填满,推理过程结束。
最终翻译结果:目标序列 [0, 4, 5, 6] 对应的英文翻译为 "I am learning"。
总结:
-
输入中文句子“我在学习”经过模型推理过程,最终翻译为英文句子“I am learning”。
总结
Transformer 架构以其简洁、高效和强大的表示能力,奠定了现代 AI 的技术基础。从本文你应该掌握:
-
三种注意力机制的来源、功能与差异
-
编码器与解码器的模块拆分与计算路径
-
Transformer 的完整数据流动图与模块职责
-
基于 PyTorch 的结构化伪代码框架

















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









