






大家好,我是玄姐。
正文开始之前,先给我自己打个广告,大家过年好,为了回馈粉丝们的支持,原价199元的《3天 AI Agent 智能体项目实战直播训练营》,直接降价到19元,今天再开放一天报名特权,仅限99名。
回到正题。
DeepSeek-V3 重磅登场!以1/10计算量实现对标 Llama 3 405B 的顶尖性能,三大硬核创新重塑大模型架构范式。技术团队通过:1)首创多头潜注意力机制(MLA),攻克长文本推理的显存效率瓶颈;2)革新动态路由算法,突破MoE模型长期存在的专家选择困境;3)创新性多令牌预测框架,实现推理吞吐量跨越式提升,完成对传统Transformer架构的颠覆性改造。这场由 DeepSeek 引领的架构革命,不仅印证了中国团队在 AI 基础研究领域的深厚积累,更以突破性技术路径重新定义行业基准!
—1—
小计算量,大智慧:DeepSeek V3 惊艳亮相
还在为高昂的推理成本困扰?面对长文本处理束手无策?DeepSeek V3 以颠覆性技术架构创新强势破局!革命性的上下文处理机制实现长文本推理成本断崖式下降,综合算力需求锐减90%,开启高效 AI 新纪元!
最新开源的 DeepSeek V3模型不仅以顶尖基准测试成绩比肩业界 SOTA 模型,更以惊人的训练效率引发行业震动——仅耗费 280万H800 GPU 小时(对应 4e24 FLOP@40% MFU)即达成巅峰性能。对比同级别 Llama3-405B 模型,训练计算量实现10倍级压缩,创下大模型训练效率新标杆!
这一里程碑式突破不仅印证了 DeepSeek 团队的技术攻坚能力,更揭示了 AI 发展的新范式:通过架构创新实现性能与效率的协同进化,真正打破AI规模化应用的成本桎梏。从算法底层重构到工程实现优化,DeepSeek V3如何实现效率的指数级跃迁?背后的技术奥秘究竟何在?
—2—
技术架构揭秘:DeepSeek V3 的三大创新利器
DeepSeek V3以三大颠覆性创新重构 Transformer 架构(如下图技术架构全景图所示)——多头潜注意力(MLA)、深度优化混合专家系统(DeepSeekMoE)及多令牌预测机制,精准击破算力消耗、长上下文处理与训练效率三大行业痛点,实现性能与成本的跨代平衡。
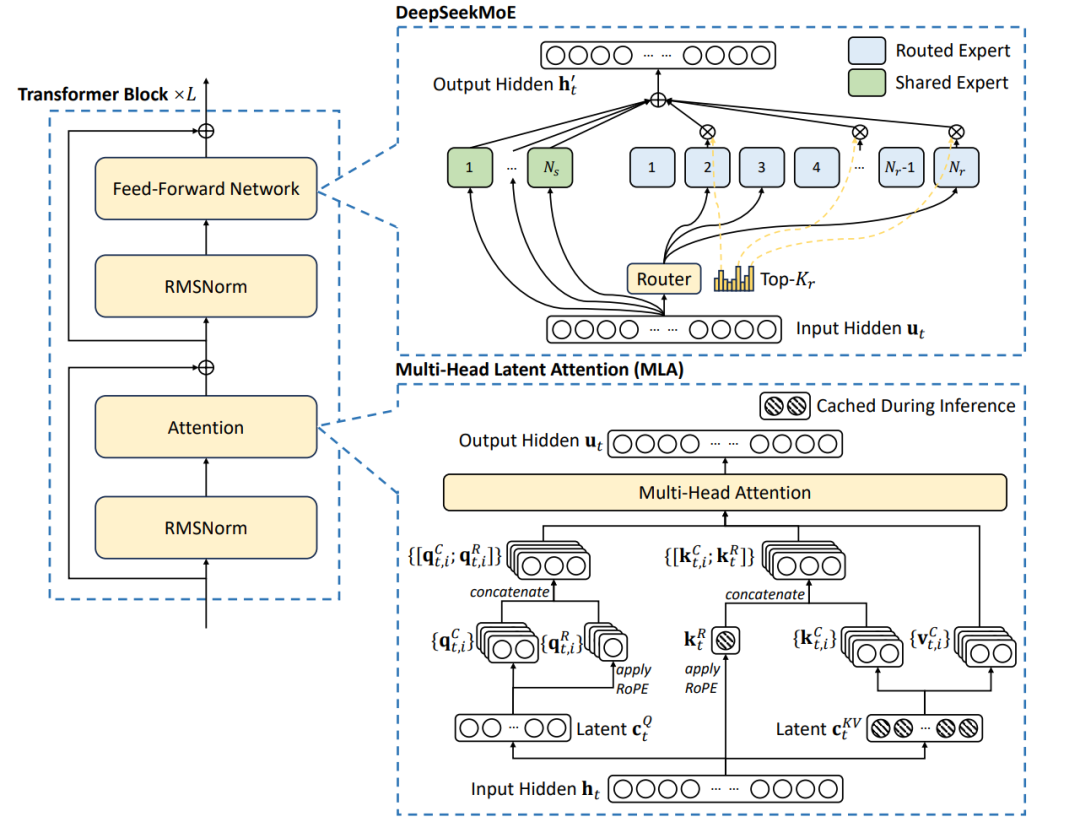
技术核爆点一:多头潜注意力(MLA)——长文本推理的降本奇兵
▎KV缓存:大模型的"记忆包袱"
Transformer 模型处理长文本时,需缓存历史键值向量(KV Cache)以维持上下文关联性。以 GPT-3 为例:单 token 需占用 4.7MB 缓存空间(2字节/参数),处理 32k tokens 时,仅 KV缓 存便需消耗 150GB 显存!这成为长文本场景的算力黑洞。
▎传统方案的代价:性能妥协的困局
行业主流方案如分组查询注意力(GQA)通过多头共享 KV 缓存,虽能降低80%-90%显存占用,却以牺牲语义理解精度为代价。如同为减重丢弃精密仪器,虽轻装上阵却削弱核心能力。
▎MLA革命:低秩分解重构缓存范式
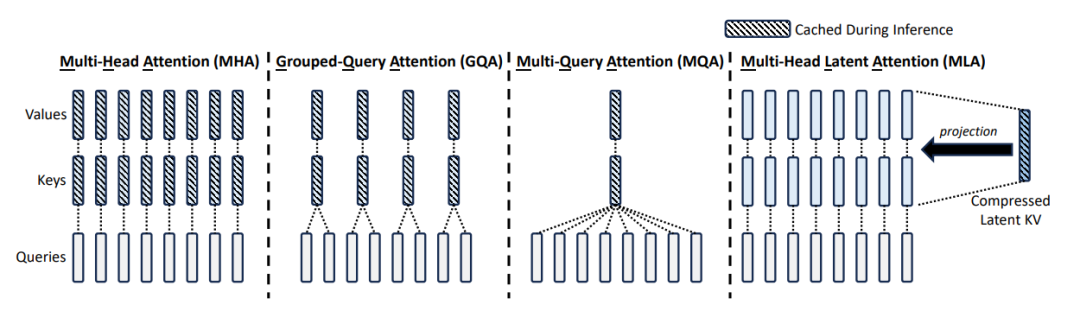
如上图所示,MLA 创造性引入潜变量中介层,将传统 KV生 成路径拆解为两步:
1. 潜向量生成:通过低秩矩阵(潜维度 × 模型维度)压缩原始特征
2. 差异化重构:各注意力头基于潜向量二次解码专属 KV 特征
推理时仅需缓存潜向量(潜维度<<原 KV 维度),实现缓存体积锐减80%+。这种"基因压缩-定向表达"机制,既保留多头注意力差异性,又挖掘跨头信息共性,实验显示在 32k 长度场景下,MLA 较 GQA 方案在 MMLU 等基准测试中提升2-3个精度点。
低秩压缩的智慧:效率与性能的共生进化**
MLA 的精妙之处在于:
- 信息蒸馏:通过矩阵低秩分解提取跨注意力头共享特征
- 动态适配:各头基于共享基向量进行个性化权重调整
- 隐式正则:压缩过程天然过滤噪声信息,增强模型鲁棒性
这种设计哲学突破传统"性能-效率"零和博弈,如同为每个注意力头配备专属解码器,既能共享基础计算资源,又可保留个性表达空间。技术团队透露,MLA 架构下潜维度每压缩50%,推理速度可提升1.8倍,而精度损失控制在0.5%以内,真正实现"鱼与熊掌兼得"。
技术核爆点二:DeepSeekMoE——破解路由崩溃的终极武器
MoE 进化论:从“专家分工”到“智能联邦”
▎传统 MoE 的桎梏:效率与稳定的二律背反
传统混合专家模型通过动态路由分配任务至稀疏激活的专家网络,理论上实现"计算量恒定,模型容量指数增长"。但实际训练中,**路由崩溃(Routing Collapse)**现象导致超80%专家处于"休眠"状态,如同神经网络版的"马太效应"——强者愈强,弱者消亡。
▎DeepSeek V3 破局双刃:动态负反馈调节+知识联邦体系
创新方案一:无监督负载均衡算法
- 抛弃传统辅助损失函数,首创专家动态偏置自适应技术
- 每个专家配备可学习偏置参数,实时监测激活频率
- 低频专家自动获得正向偏置补偿,形成负反馈调节回路
实验数据显示,该方案在32专家配置下,专家利用率从传统 MoE 的 12% 提升至 89%,且无损模型效果。
创新方案二:共享-路由专家联邦架构

这种"常驻军+特种兵"的设计,既保障语言建模的共性需求,又满足垂直场景的个性表达。在代码生成任务中,路由专家对 Python 语法特征的捕捉精度提升37%。
技术核爆点三:多令牌预测——打破自回归模型的时空诅咒
自回归效率革命:从"逐字雕刻"到"并行雕刻"
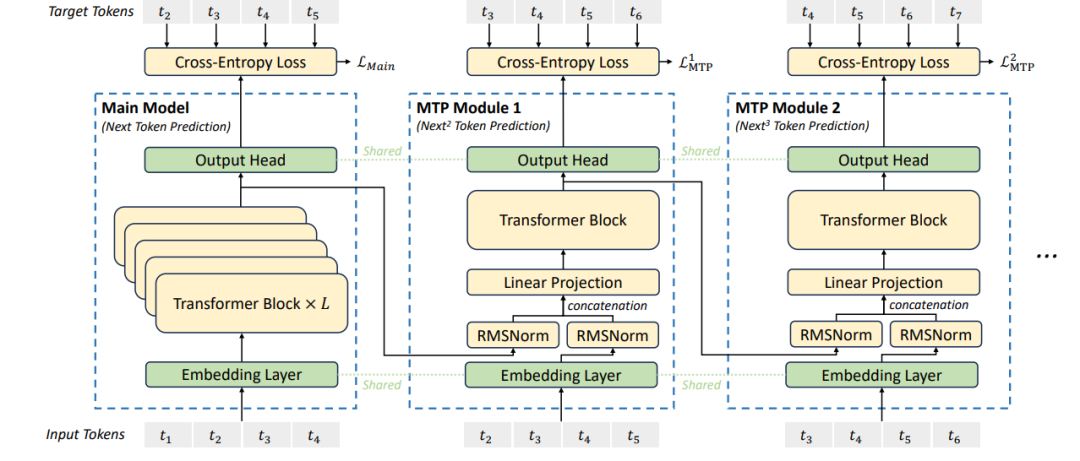
▎传统模式的致命延时
传统 Transformer 逐 token 生成如同"单线程流水线":
- 训练时:99% 算力仅用于预测下一 token,信息利用率不足
- 推理时:GPU 计算单元大量闲置,利用率常低于 40%
▎时空折叠技术:单次前馈双倍收益

DeepSeek V3创新引入残差流分形解码架构:
1. 主预测模块:输出当前token概率分布(标准模式)
2. 次预测模块:将最终残差流注入轻量化 Transformer 子块,生成次 token 预测
3. 动态损失融合:主次预测损失以 7:3 权重混合训练,兼顾精度与前瞻性
该设计使单次前向传播学习效率提升 1.8 倍,在代码补全任务中,token 预测准确率相对位置误差降低 42%。
推测式解码:让语言模型拥有"预见未来"的能力
▎自验证加速引擎
推理时系统同步执行:
1. 生成主次双 token 候选
2. 用主模型反向验证逻辑一致性
3. 动态采纳通过验证的预测链
技术白皮书显示,在 32k 上下文场景中:
- 次 token 接受率稳定在 87.3%
- 推理吞吐量峰值达 189% 提升
- 每 token 平均能耗下降 58%
▎工业级加速范式
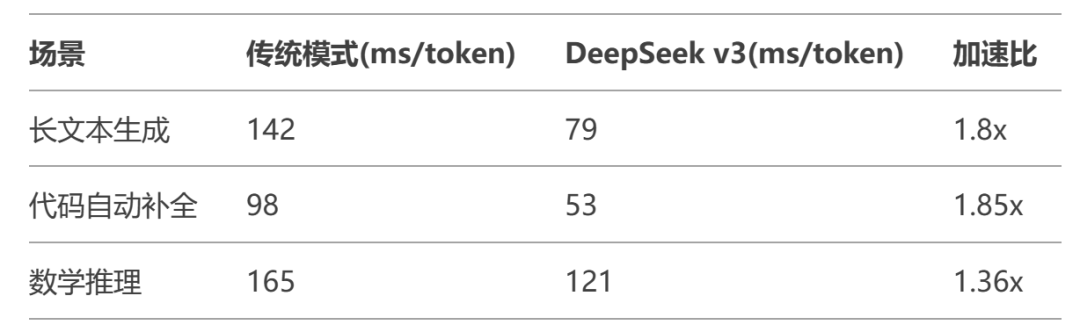
这种"预判-验证-执行"的三段式推理,如同为语言模型装载涡轮增压引擎,在保证生成质量的同时突破物理算力限制。
—3—
技术美学启示:优雅比暴力更重要
DeepSeek 团队展现的"技术品味"值得深思:
- 物理直觉:将残差流视作"信息势能",二次解码挖掘潜能
- 系统思维:训练/推理协同设计,避免局部优化陷阱
- 简约哲学:用 20% 架构改动获得 200% 效能提升
这项创新证明,在 LLM 领域,"聪明地设计"比"粗暴地堆算力"更能触及效率本质。当行业沉迷于万亿参数竞赛时,DeepSeek V3用精妙的正交性设计开辟了新航道——或许这就是通向 AGI 的最短路径。
随着 DeepSeek 的爆火,2025年必定是 AI 大模型应用的爆发之年,其中最重要的应用形态就是 AI Agent 智能体,为了帮助大家快速掌握 AI Agent 智能体技术,我和团队落地大模型项目2年,帮助60多家企业落地近100个项目,根据我们企业级实战的项目经验,打造3天 AI Agent 项目实战直播训练营,截至今天已经报名2万名学员,如此火爆!原价199元,过年期间,为了回馈粉丝的支持,价格直接降到 19元,再开放今天一天的报名权限,仅限99名,抢完立刻恢复到199元。
—4—
AI Agent 智能体为啥如此重要?
第一、这是大势所趋,我们正在经历一场重大技术变革,还不像当年的互联网的兴起,这是一场颠覆性的变革,掉队就等于淘汰,因为未来所有应用都将被 AI Agent 智能体重写一遍;

第二、现在处于红利期,先入场的同学至少会享受4~5年的红利,拿高薪,并且会掌握技术的主动权和职业选择权。
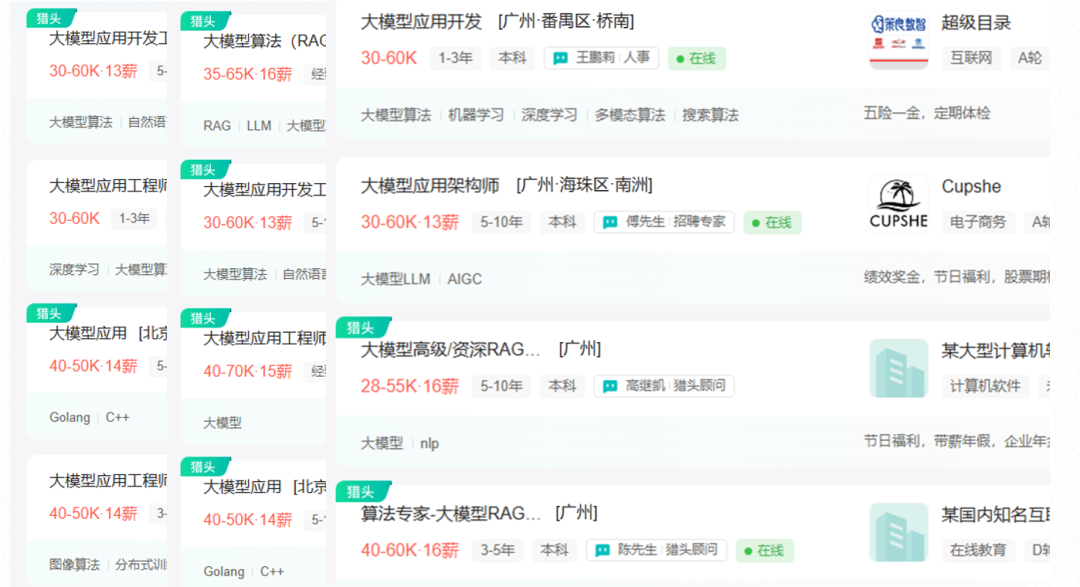
第三、企业需求旺盛,越来越多的企业已经在 Agent 智能体领域进行落地,这为我们提供了丰富的岗位机会和广阔的发展空间。

第四、大厂都在战略布局的方向,不管是国外的微软、谷歌,还是国内的百度等大厂都在战略布局,2025年必定是 AI Agent 智能体商业化的一年。
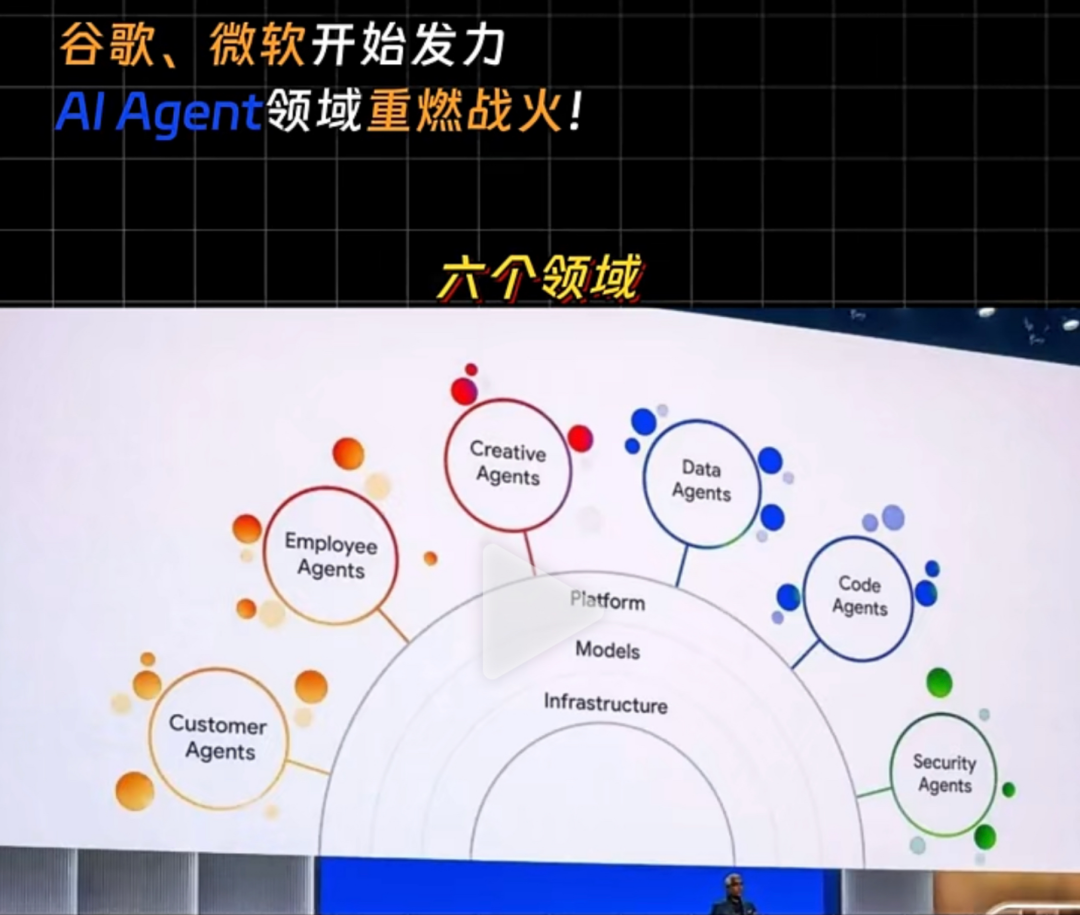
我和团队最近两年一直在研究大模型应用技术,我想说:大模型的价值太大了,AI Agent 智能体的潜力太大了!“未来所有应用都会被 AI Agent 智能体重写一遍”!这句话也是今年听到最多的一句话。我和团队这两年,尤其是今年已经帮助60多家企业落地了近100个 AI Agent 智能体的项目。我自己贴身感受:越来越多的企业的确都开始落地 AI Agent 智能体项目了。
因此 AI Agent 智能体足够重要,但也足够复杂,我这两年实践结论是,想开发出一个能够可靠稳定的 AI Agent 智能体应用实在太难了,大模型技术本身的复杂度,大模型推理的不确定性,响应速度性能问题等等,这些困难直接导致很多人对其望而却步,或是遇到问题无从下手。一般技术同学想要自己掌握 AI Agent 智能体着实很不容易!
为此我特意打造了一个为期3天的 AI Agent 智能体企业实战训练营:这个训练营是我和团队落地大模型项目2年,根据我们企业级实战的项目经验,打造3天 AI Agent 项目实战直播训练营。

课程原价199元,现在仅花19元就能拿下!文末再赠送4个报名福利!抢完立刻恢复199元!
—5—
3天直播训练营,你能收获什么?
3天的直播课,带你快速掌握 AI Agent 智能体核心技术和企业级项目实践经验。
模块一:AI Agent 智能体技术原理篇
全面拆解 AI Agent 智能体技术原理,深度掌握 AI Agent 智能体三大能力及其运行机制。
模块二:AI Agent 智能体应用开发实战篇
深度讲解 AI Agent 智能体技术选型及开发实践,学会开发 AI Agent 智能体核心技术能力。
模块三:AI Agent 智能体企业级案例实战篇
从需求分析、架构设计、架构技术选型、硬件资料规划、核心代码落地、服务治理等全流程实践,深度学习企业级 AI Agent 智能体项目全流程重点难点问题解决。

3天时间,你能学会什么?
在真实项目实践中,你会获得4项硬核能力:
第一、全面了解 AI Agent 智能体的原理、架构和实现方法,掌握核心技术精髓。
第二、熟练使用 Dify/Coze 平台、LangChain、AutoGen 等开发框架,为企业级技术实践打下坚实基础。
第三、通过企业级项目实战演练,能够独立完成 AI Agent 智能体的设计开发和维护,学会解决企业级实际问题的能力。
第四、为职业发展提供更多可能性,无论是晋升加薪还是转行跳槽,提升核心技术竞争力。
限时优惠:
原价199元,现在报名只需19元!文末再赠送4个报名福利!这是一个难得的机会,让我们一起踏上 AI Agent 智能技术之旅,开启技术新纪元!
—6—
今天报名再送4个配套福利
配套福利一:AI Agent 智能体训练营配套学习资料,包括:PPT 课件、实战代码、企业级智能体案例和补充学习资料。

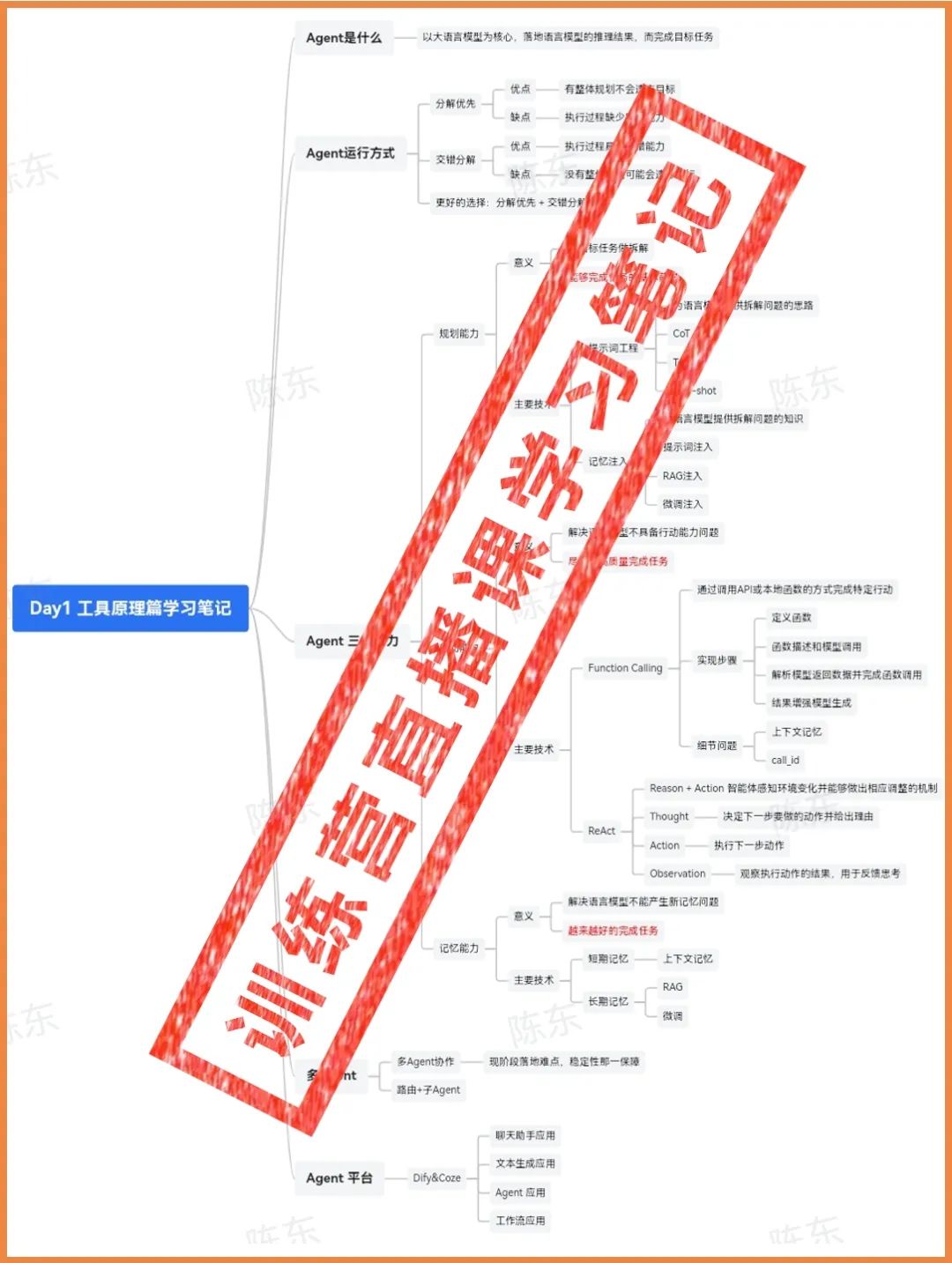
配套福利二:AI Agent 智能体训练营学习笔记,包含3天直播的所有精华。
配套福利三:AI Agent 智能体大厂面试真题100道!覆盖百度、阿里、腾讯、字节、美团、滴滴等大厂的100道真题,不论是跳槽还是升职加薪,参考意义都重大!

配套福利四:2024年中国 AI Agent 智能体行业研究报告!AI Agent 智能体是新的应用形态,大模型时代的“APP”,技术范式也发生了很大的变化, 此份研究报告探索新一代人机交互及协作范式,覆盖技术、产品、商业、企业落地应用等方面,非常值得一读!

原价199元,现在19元就能拿下!
—7—
添加助教直播学习
购买后,添加助理进行直播学习👇

报名完添加助教二维码,立刻领取4重福利!
参考:
https://mp.weixin.qq.com/s/fIvUFHbEM1v4nwPYe3fxmA
END

















 1955
1955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









