







DeepSeek 惊艳背后的架构创新
原创 非子爱 子非AI 2025年01月23日 21:07 美国

DeepSeek v3 震撼发布,仅用十分之一计算量就达到比肩 Llama 3 405B 的性能!其秘诀在于三大架构创新:多头潜注意力 (MLA) 大幅降低长文本推理成本,混合专家模型 (MoE) 创新解决了路由崩溃难题,多令牌预测显著提升推理速度。DeepSeek 团队对 Transformer 的深刻理解和精妙设计,为 AI 领域树立了新的标杆。
小计算量,大智慧:DeepSeek v3 的惊艳亮相
你是否曾经因为大模型推理成本过高而望而却步?你是否曾经因为处理长文本而感到力不从心?现在,DeepSeek v3 来了!它以革命性的架构创新,将长文本推理成本暴降,算力需求狂砍 90%!
DeepSeek 近期发布的 DeepSeek v3 模型,在开源权重模型中,以其卓越的基准测试性能脱颖而出,可与当前最先进的模型相媲美。更令人惊叹的是,DeepSeek v3 仅用了约 280 万 H800 小时的训练硬件时间,就实现了这一领先性能。这相当于约 4e24 FLOP 的计算量(假设 MFU,即模型 FLOP 利用率为 40%),与性能相近的 Llama 3 405B 相比,训练计算量足足减少了约十倍!
这一突破性的进展,不仅彰显了 DeepSeek 团队强大的技术实力,也为 AI 领域的发展带来了新的启示:通过巧妙的架构设计,可以大幅提升模型的效率和性能,降低 AI 应用的门槛。DeepSeek v3 究竟是如何做到的?让我们一探究竟!
架构揭秘:DeepSeek v3 的三大创新利器
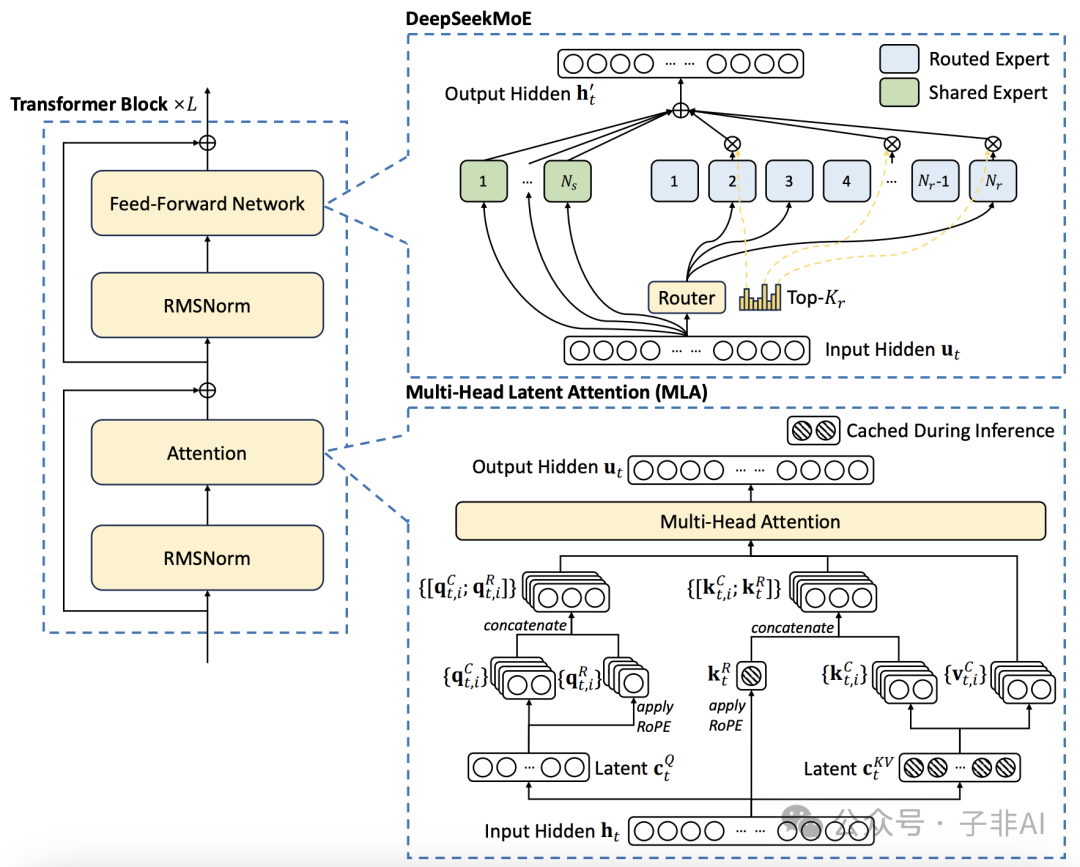
图 1:DeepSeek v3 架构概览图,展示了其两大核心改进:DeepSeekMoE 和多头潜注意力 (MLA)。图中未显示多令牌预测部分。
DeepSeek v3 之所以能够以小博大,关键在于其三大架构创新:多头潜注意力 (MLA)、混合专家模型 (MoE) 的改进以及多令牌预测。这三大创新分别针对 Transformer 架构中的不同瓶颈,实现了性能和效率的双重提升。
1. 多头潜注意力 (MLA):突破长文本推理的性能瓶颈
-
• 什么是 KV 缓存?它为什么重要?
想象一下,你在读一本很长的小说,为了理解后面的情节,你需要记住前面的人物关系和事件发展。Transformer 模型也是一样,在进行推理时,为了理解当前输入与历史信息之间的关系,需要访问所有历史信息。为了避免重复计算,模型会将历史信息中的关键信息(键和值向量)存储起来,这就是所谓的 KV 缓存。
KV 缓存的大小直接影响了模型的推理速度和内存消耗,尤其是在处理长文本时,KV 缓存
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









