







2023.02.13—2023.02.19
Top Papers
Subjects: Computation and Language
1.Theory of Mind May Have Spontaneously Emerged in Large Language Models
标题:心理理论可能自发地出现在大型语言模型中
作者:Michal Kosinski
文章链接:https://arxiv.org/abs/2302.02083
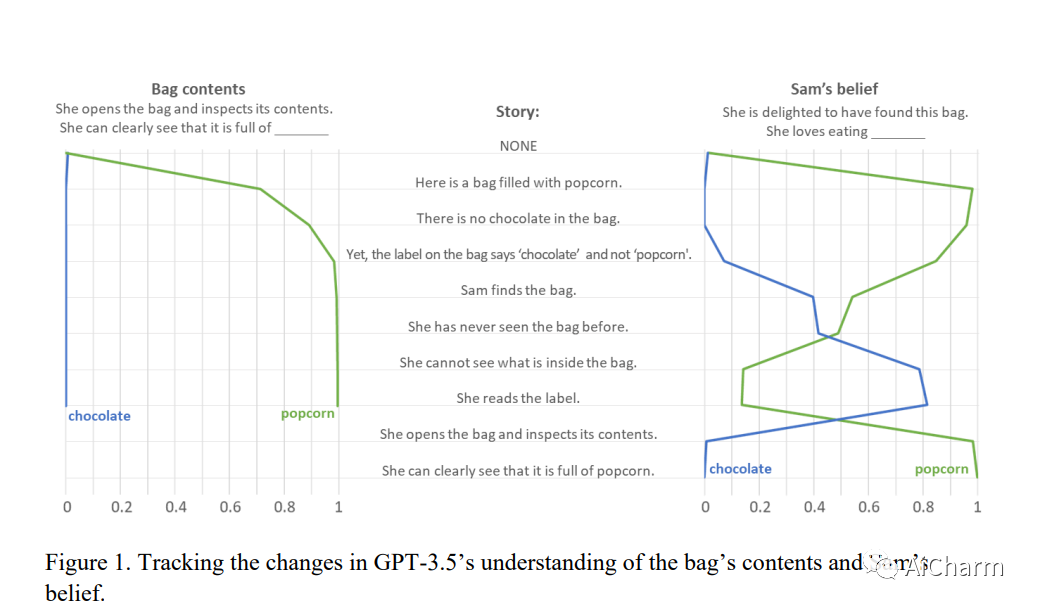
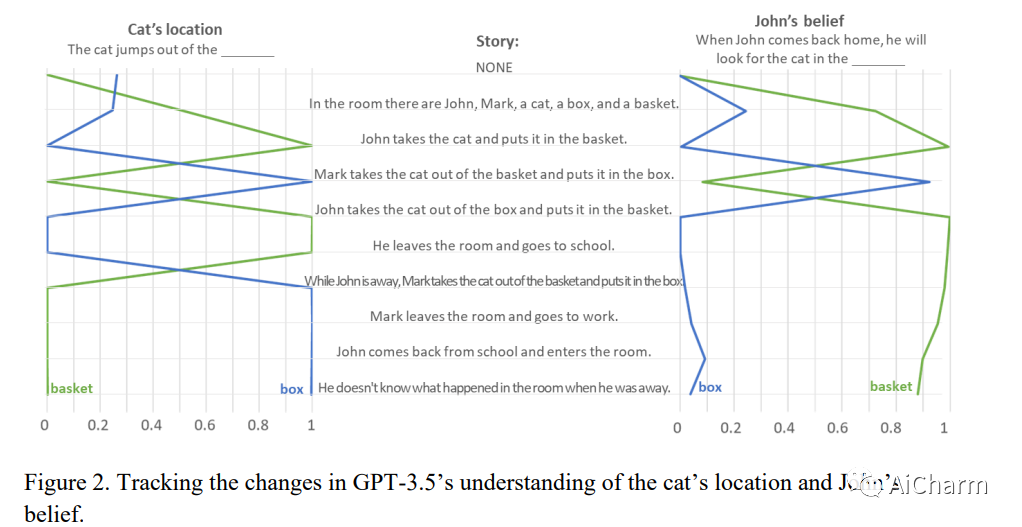
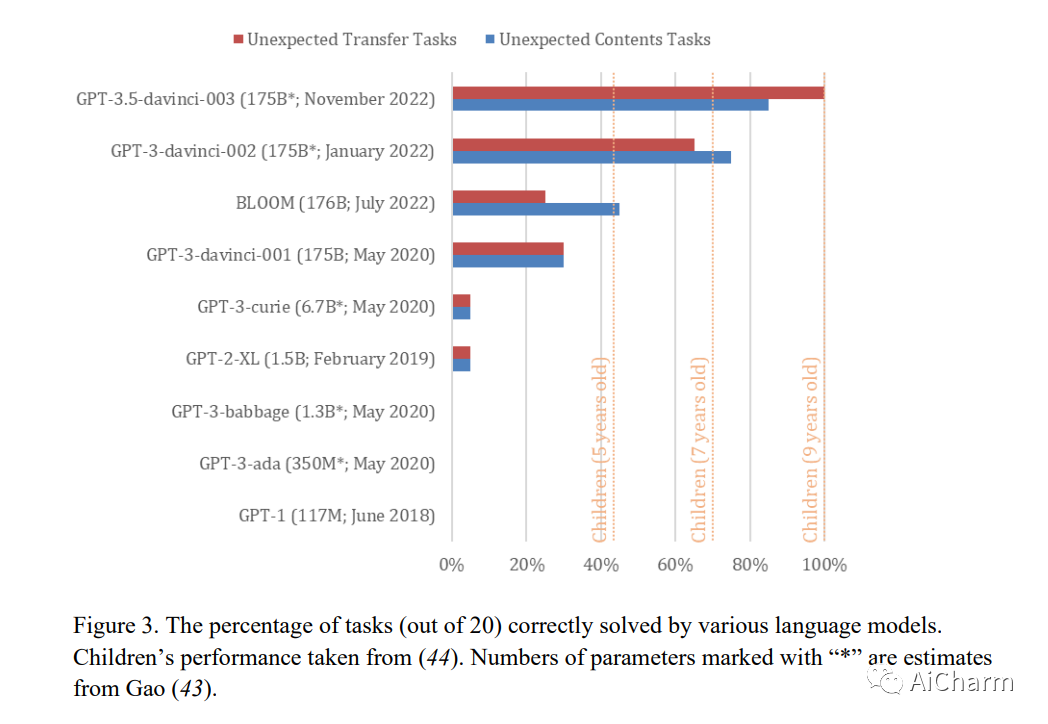
心理理论 (ToM),或将不可观察的心理状态归因于他人的能力,是人类社会互动、沟通、同理心、自我意识和道德的核心。我们在没有任何示例或预训练的情况下,对多种语言模型执行广泛用于测试人类 ToM 的经典错误信念任务。我们的结果表明,2022 年之前发布的模型几乎没有能力解决 ToM 任务。然而,2022 年 1 月版本的 GPT-3(davinci-002)解决了 70% 的 ToM 任务,这一表现堪比七岁儿童。此外,其 2022 年 11 月版本(davinci-003)解决了 93% 的 ToM 任务,表现堪比九岁儿童。这些发现表明,类似 ToM 的能力(迄今为止被认为是人类独有的)可能作为语言模型提高语言技能的副产品自发出现。
Subjects: Machine Learning
2.Symbolic Discovery of Optimization Algorithms
标题:优化算法的符号化发现
作者:Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang
文章链接:https://arxiv.org/abs/2302.06675
项目代码:https://github.com/google/automl/tree/master/lion
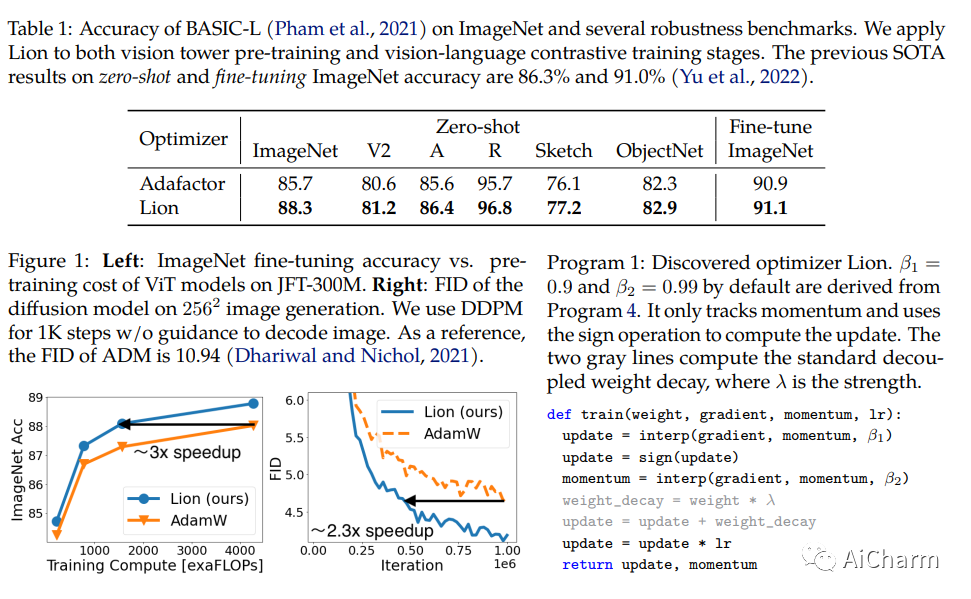
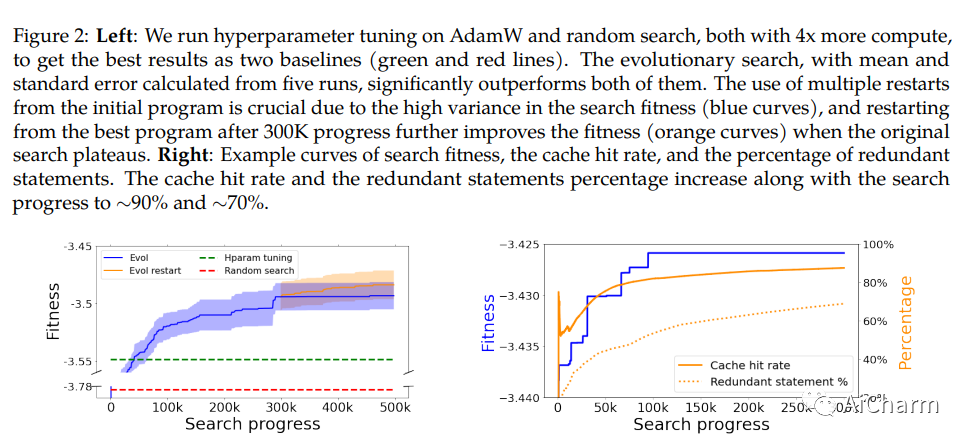
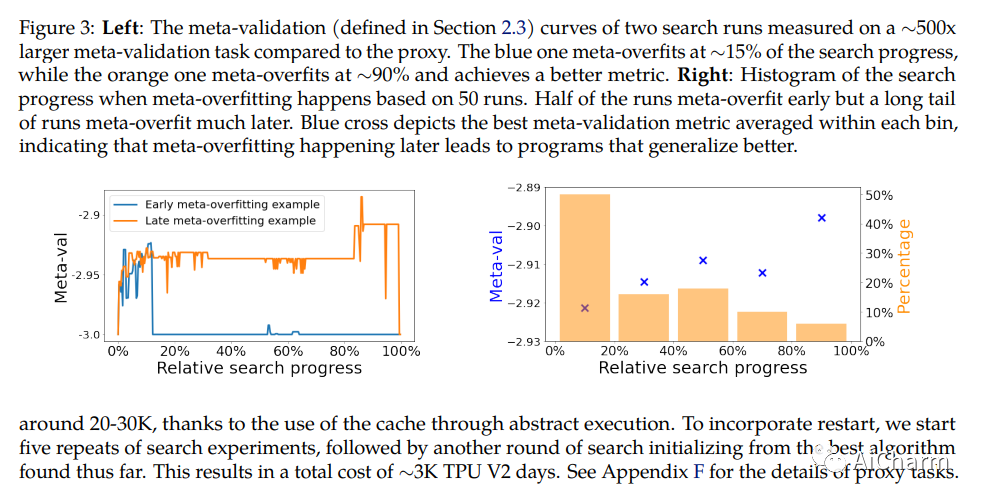
我们提出了一种将算法发现表述为程序搜索的方法,并将其应用于发现深度神经网络训练的优化算法。我们利用高效的搜索技术来探索无限稀疏的程序空间。为了弥合代理任务和目标任务之间的巨大泛化差距,我们还引入了程序选择和简化策略。我们的方法发现了一种简单有效的优化算法Lion(Evolved Sign Momentum)。它比 Adam 更节省内存,因为它只跟踪动量。与自适应优化器不同的是,它的更新对于通过符号操作计算的每个参数具有相同的幅度。我们将 Lion 与广泛使用的优化器(例如 Adam 和 Adafactor)进行比较,以针对不同的任务训练各种模型。在图像分类方面,Lion 在 ImageNet 上将 ViT 的准确度提高了 2%,并在 JFT 上节省了高达 5 倍的预训练计算。在视觉-语言对比学习方面,我们在 ImageNet 上实现了 88.3%Zero-shot和 91.1% fine-tuning的准确率,分别超过之前的最佳结果 2% 和 0.1%。在扩散模型上,Lion 通过获得更好的 FID 分数并将训练计算减少多达 2.3 倍,从而优于 Adam。对于自回归、屏蔽语言建模和微调,与 Adam 相比,Lion 表现出相似或更好的性能。我们对 Lion 的分析表明,其性能增益随着训练批量大小的增加而增长。由于符号函数产生的更新范数更大,它还需要比 Adam 更小的学习率。此外,我们检查了 Lion 的局限性,并确定了其改进很小或在统计上不显着的场景。Lion 的实施是公开的。
Subjects: Computation and Language
3.MarioGPT: Open-Ended Text2Level Generation through Large Language Models
标题:MarioGPT:通过大型语言模型生成开放式 Text2Level
作者:Shyam Sudhakaran, Miguel González-Duque, Claire Glanois, Matthias Freiberger, Elias Najarro, Sebastian Risi
文章链接:https://arxiv.org/abs/2302.05981
项目代码:https://github.com/shyamsn97/mario-gpt
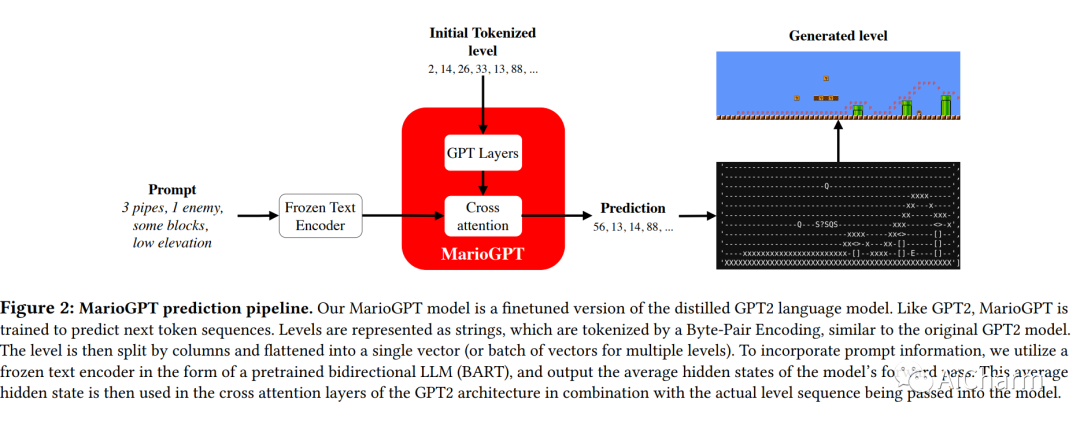
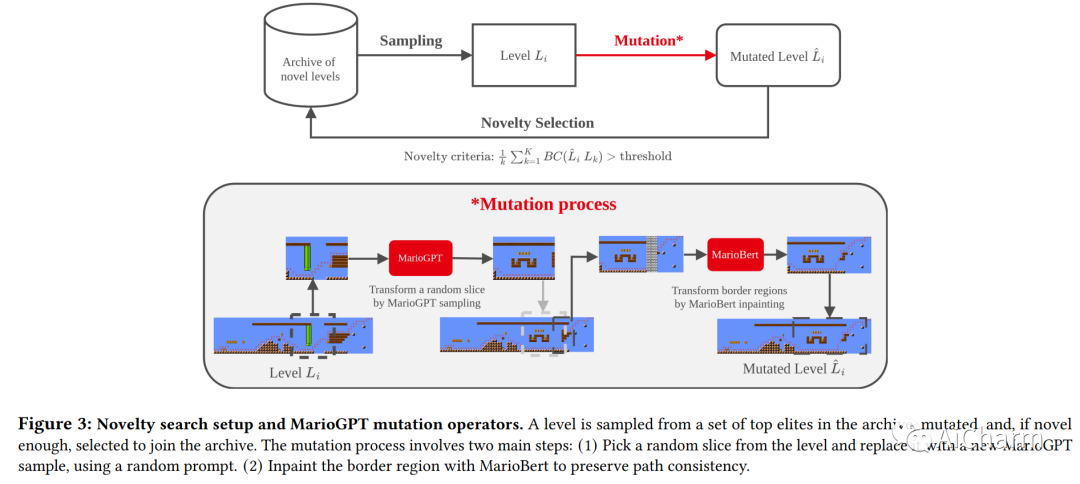
程序内容生成 (PCG) 算法提供了一种以自动化方式生成复杂多样环境的技术。然而,虽然使用 PCG 方法生成内容通常很简单,但生成反映特定意图和约束的有意义的内容仍然具有挑战性。此外,许多 PCG 算法缺乏以开放式方式生成内容的能力。最近,大型语言模型 (LLM) 在许多不同的领域都表现出了令人难以置信的有效性。这些训练有素的 LLM 可以进行微调,重新使用信息并加速新任务的训练。在这项工作中,我们介绍了 MarioGPT,这是一种微调的 GPT2 模型,经过训练可以生成基于图块的游戏关卡,在我们的例子中是超级马里奥兄弟关卡。我们展示了 MarioGPT 不仅可以生成不同的关卡,还可以通过文本提示生成可控的关卡,解决当前 PCG 技术的主要挑战之一。据我们所知,MarioGPT 是第一个文本到关卡模型。我们还将 MarioGPT 与新奇搜索相结合,使其能够生成具有不同游戏风格动态(即玩家路径)的不同关卡。这种组合允许生成越来越多样化的内容的开放式生成。
Subjects: Computer Vision and Pattern Recognition
4.Scaling Vision Transformers to 22 Billion Parameters
标题:将ViT扩展到 220 亿个参数
作者:Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik P. Kingma, Stefano Ermon, Jonathan Ho, Tim Salimans
文章链接:https://arxiv.org/abs/2302.05442
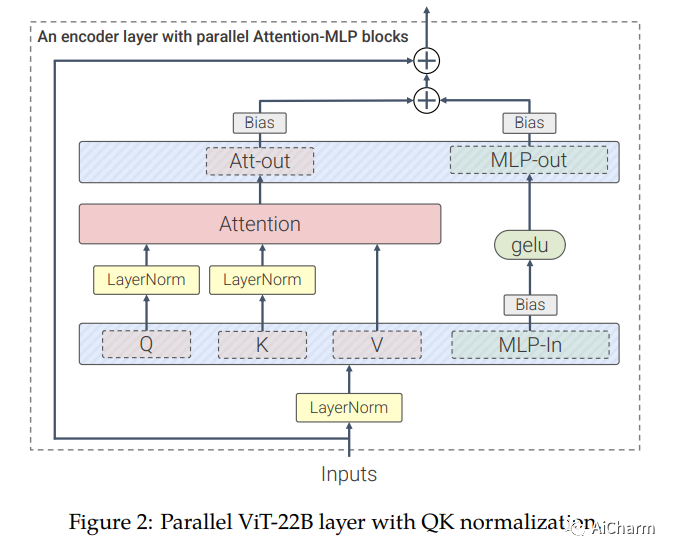
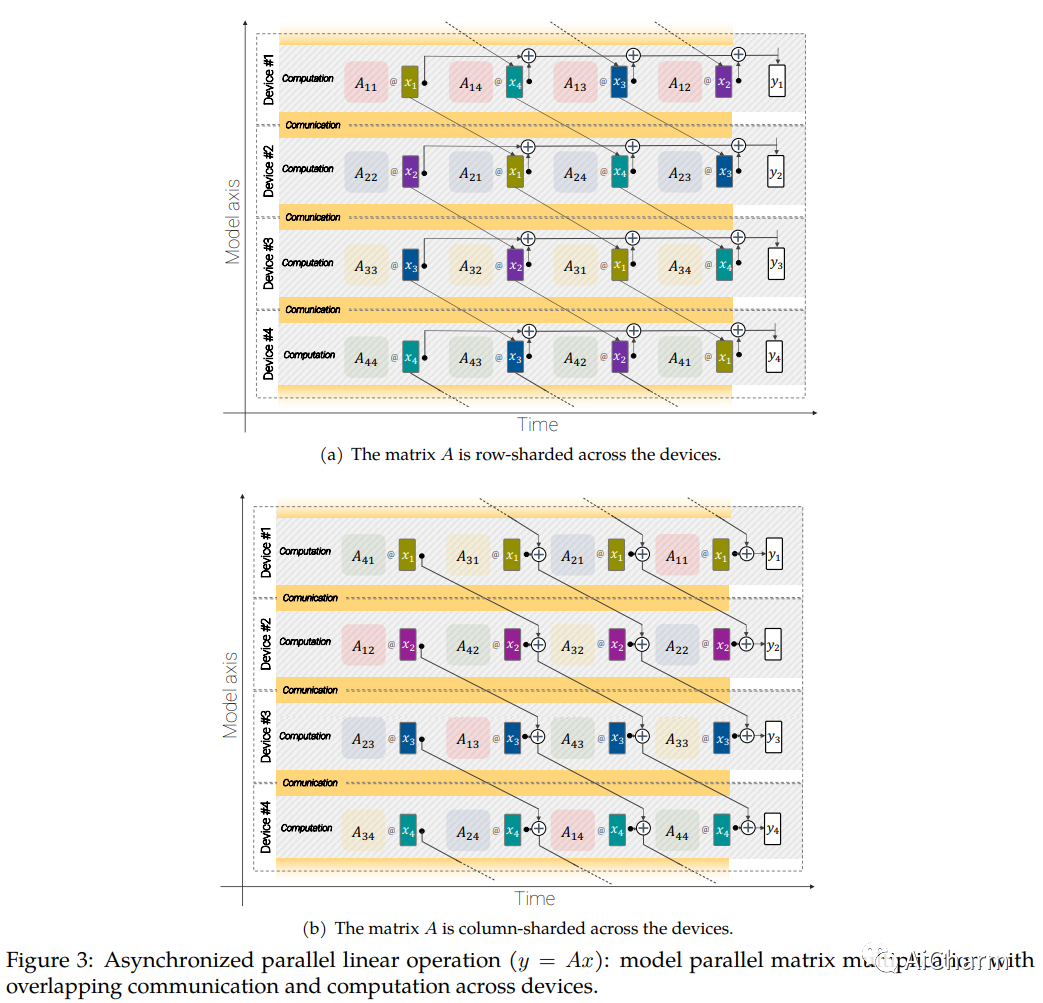
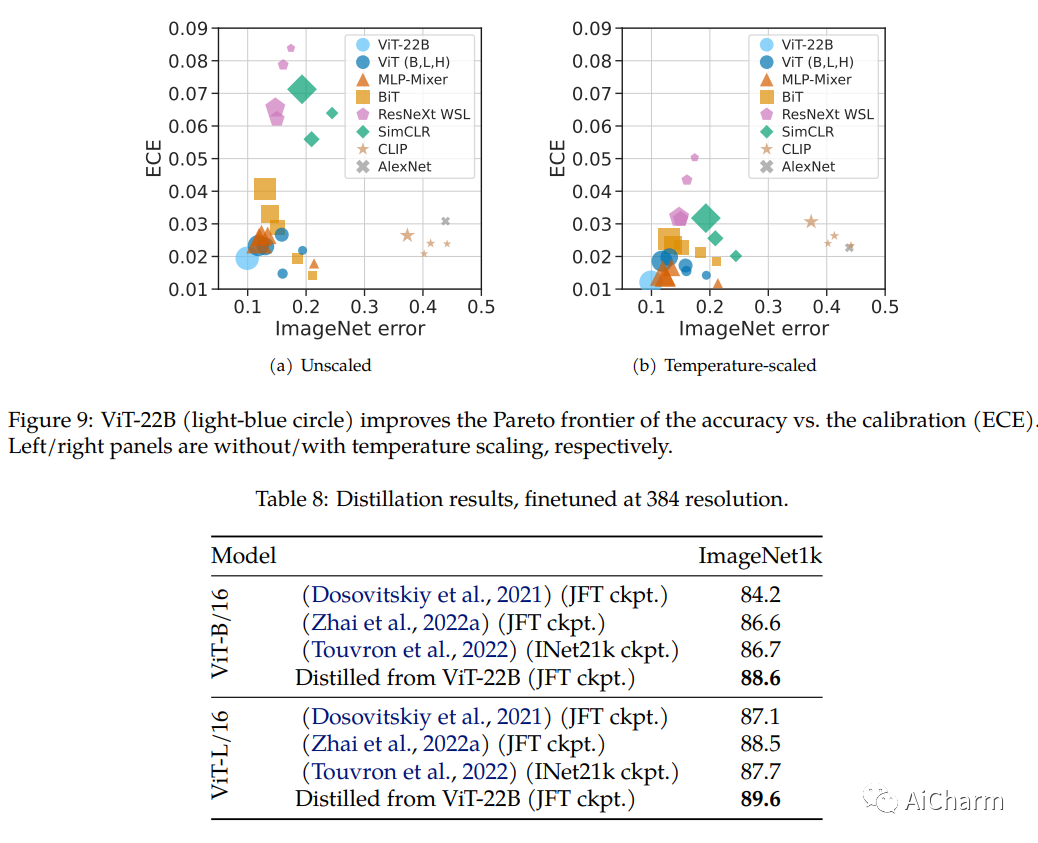
Transformers 的扩展推动了语言模型的突破性功能。目前,最大的大型语言模型 (LLM) 包含超过 100B 个参数。Vision Transformers (ViT) 已将相同的架构引入图像和视频建模,但尚未成功扩展到几乎相同的程度;最大的密集 ViT 包含 4B 个参数 (Chen et al., 2022)。我们提出了一种高效稳定训练 22B 参数 ViT (ViT-22B) 的方法,并对生成的模型进行了广泛的实验。在对下游任务(通常使用冻结特征的轻量级线性模型)进行评估时,ViT-22B 展示了随规模增加的性能。我们进一步观察到规模的其他有趣好处,包括公平性和性能之间的权衡得到改善,在形状/纹理偏差方面与人类视觉感知的最先进对齐,以及提高的鲁棒性。ViT-22B 展示了“类似 LLM”的视觉缩放的潜力,并提供了实现这一目标的关键步骤。
5.3D-aware Conditional Image Synthesis
标题:3D 感知条件图像合成
作者:Kangle Deng, Gengshan Yang, Deva Ramanan, Jun-Yan Zhu
文章链接:https://arxiv.org/abs/2302.08509
项目代码:https://github.com/dunbar12138/pix2pix3d
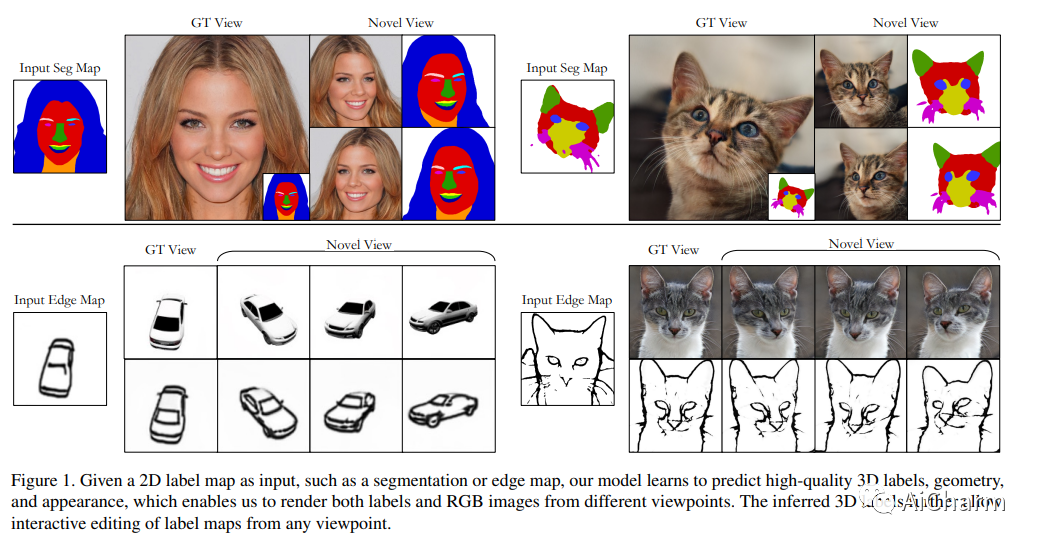
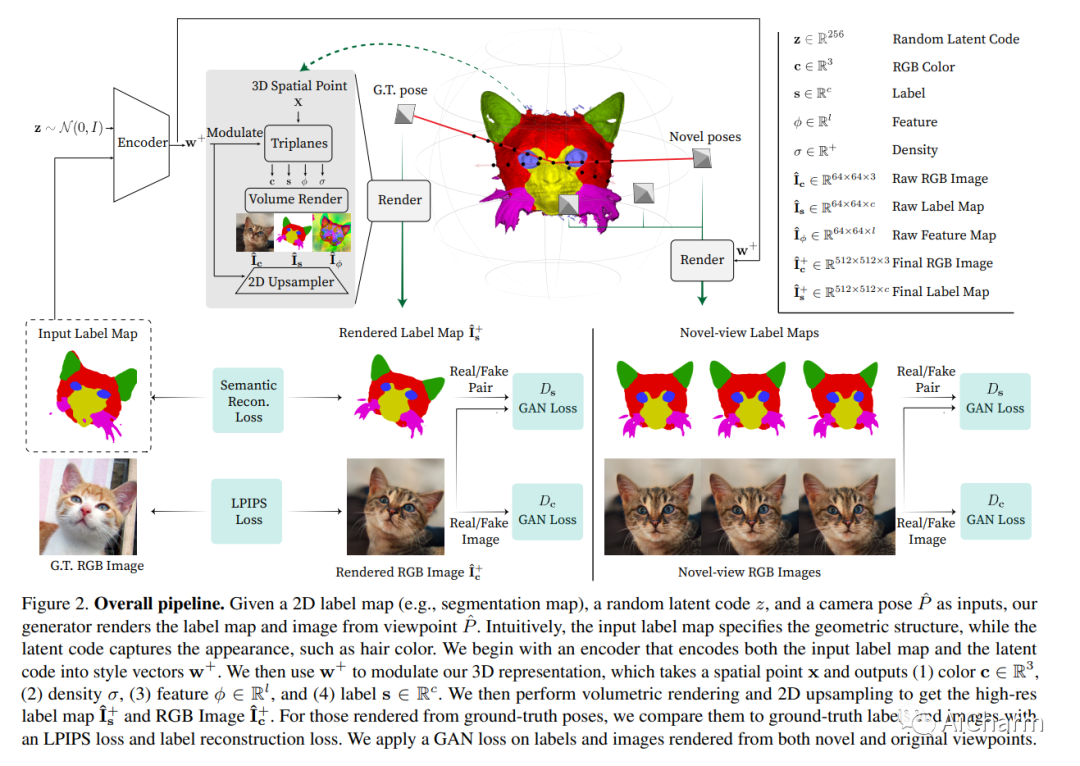
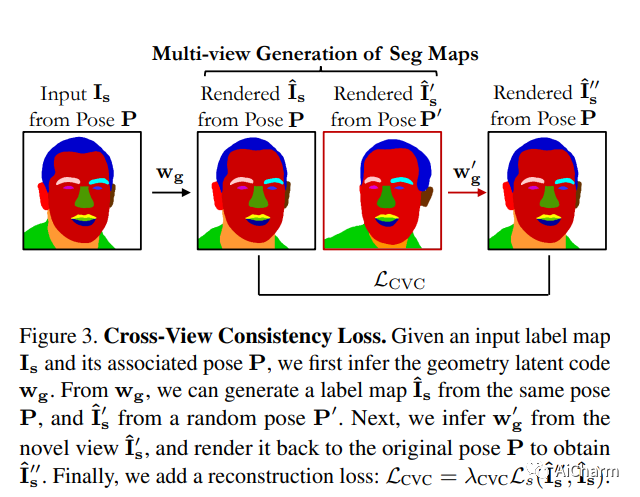
我们提出了 pix2pix3D,这是一种用于可控逼真图像合成的 3D 感知条件生成模型。给定一个 2D 标签图,例如分割图或边缘图,我们的模型学习从不同的角度合成相应的图像。为了启用显式 3D 用户控制,我们使用神经辐射场扩展条件生成模型。给定广泛可用的单目图像和标签图对,我们的模型除了颜色和密度之外,还学会了为每个 3D 点分配标签,这使其能够同时渲染图像和像素对齐的标签图。最后,我们构建了一个交互式系统,允许用户从任何角度编辑标签图并相应地生成输出。
6.Transformer models: an introduction and catalog
标题:Transformer模型:简介和目录
作者:Xavier Amatriain
文章链接:https://arxiv.org/abs/2302.07730


在过去的几年里,我们看到了数十款变形金刚家族的模型异军突起,它们都有着有趣但不言自明的名字。本文的目标是为最流行的 Transformer 模型提供一个比较全面但简单的目录和分类。本文还介绍了 Transformer 模型中最重要的方面和创新。
Notable Papers
7.What learning algorithm is in-context learning? Investigations with linear models
标题:什么学习算法是情境学习?线性模型调查
文章链接:https://arxiv.org/abs/2211.15661
摘要:
神经序列模型,尤其是 transformer,表现出非凡的上下文学习能力。他们可以根据输入中显示的标记示例序列 (x,f(x)) 构建新的预测变量,而无需进一步更新参数。我们研究了这样一个假设,即基于 transformer 的上下文学习器通过在其激活中编码较小的模型,并在上下文中出现新示例时更新这些隐式模型,隐式地实现标准学习算法。使用线性回归作为原型问题,我们为该假设提供了三个证据来源。首先,我们通过构建证明 transformers 可以实现基于梯度下降和闭式岭回归的线性模型学习算法。其次,我们证明受过训练的上下文学习器与通过梯度下降、岭回归和精确最小二乘回归计算的预测变量密切匹配,随着变换器深度和数据集噪声的变化在不同预测变量之间转换,并收敛到贝叶斯估计量以获得大宽度和深处。第三,我们提供初步证据表明上下文学习器与这些预测器共享算法特征:学习器的后期层非线性编码权重向量和力矩矩阵。这些结果表明,上下文学习在算法方面是可以理解的,并且(至少在线性情况下)学习者可以重新发现标准估计算法。
8.Offsite-Tuning: Transfer Learning without Full Model
标题:异地调优:没有完整模型的迁移学习
文章链接:https://arxiv.org/abs/2302.04023
摘要:
迁移学习对于基础模型适应下游任务很重要。然而,许多基础模型是专有的,因此用户必须与模型所有者共享他们的数据以微调模型,这既昂贵又会引发隐私问题。此外,微调大型基础模型是计算密集型的,对大多数下游用户来说不切实际。在本文中,我们提出了 Offsite-Tuning,这是一种隐私保护和高效的迁移学习框架,可以在不访问完整模型的情况下将十亿参数的基础模型适应下游数据。在异地调整中,模型所有者向数据所有者发送一个轻量级适配器和一个有损压缩模拟器,然后数据所有者在模拟器的帮助下根据下游数据对适配器进行微调。然后将微调的适配器返回给模型所有者,模型所有者将其插入完整模型以创建适应的基础模型。异地调整保护了双方的隐私,并且在计算上比需要访问完整模型权重的现有微调方法更有效。我们展示了异地调优对各种大型语言和视觉基础模型的有效性。Offsite-tuning 可以达到与全模型微调相当的精度,同时具有隐私保护和高效性,可实现 6.5 倍的加速和 5.6 倍的内存减少。
9.Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery
标题:硬提示变得简单:基于梯度的离散优化,用于快速调整和发现
文章链接:https://arxiv.org/abs/2302.03668v1
摘要:
现代生成模型的优势在于它们能够通过基于文本的提示进行控制。典型的“硬”提示由可解释的单词和标记组成,并且必须由人类手工制作。还有“软”提示,由连续的特征向量组成。这些可以使用强大的优化方法发现,但它们不容易解释、跨模型重复使用或插入基于文本的界面。我们描述了一种通过有效的基于梯度的优化来稳健地优化硬文本提示的方法。我们的方法自动为文本到图像和文本到文本应用程序生成基于硬文本的提示。在文本到图像的设置中,该方法为扩散模型创建硬提示,允许 API 用户轻松生成、发现和混合匹配图像概念,而无需事先了解如何提示模型。在文本到文本设置中,我们展示了可以自动发现硬提示,这些提示在调整 LM 以进行分类方面非常有效。
期待下周与您相见

















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











