









机器学习顶会ICML 2023于4月放榜,共有6538份论文提交,1827篇论文被接收,录用率27.9%,达历史之最。因为今年生成式AI的火爆,在提交的论文中,与大模型相关的论文数目也非常可观。
今天我就和大家分享9篇 ICML 2023 中大模型和鲁棒性相关 Oral 文章。
1.Scaling Vision Transformers to 22 Billion Parameters
这篇论文总结了训练2.2万亿参数视觉转换器模型的方法,提出了一种对 22B 参数 VIT(VIT-22B)高效且稳定的培训的配方,并在所得模型上进行了多种实验。
主要贡献:
转换器架构已经带来语言模型显著能力提升。最好的语言模型包含上百亿的参数。视觉转换器将相同架构带到图像和视频建模,但尚未成功扩展到相同程度;最大的视觉转换器只有400亿参数。
-
作者提出训练2.2万亿参数视觉转换器(ViT-22B)的高效稳定方法。
-
在下游任务上的评估(使用固化特征的轻量线性模型)表明,与模型规模增长效能也在增加。
-
作者还观察到规模增加带来其他好处:公平性和效能之间的更好权衡、在形状/纹理偏置方面符合人类视觉感知的state-of-the-art 对齐、性能提升。
-
ViT-22B表明视觉也可以通过"LLM方式"扩展规模,并向该目标迈出关键一步。
规模增加还带来提高公平性与效能之间权衡、更好模拟人类视觉感知以及改善鲁棒性等许多好处。这表明视觉可以通过类似语言模型的方式扩大规模,ViT-22B是一个重要的里程碑。
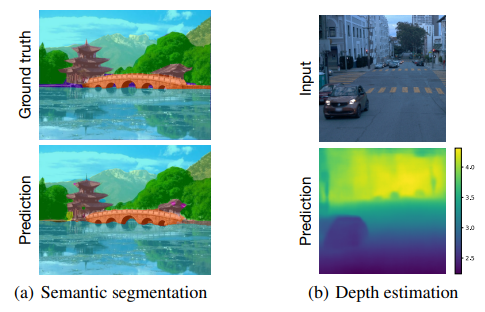
2.Specializing Smaller Language Models towards Multi-Step Reasoning
这篇文章总结了如何从更大模型(GPT-3.5) distillation 到更小模型(T5),专注于特定任务。
主要贡献:
-
作者利用多步数学推理作为实验场景,表明较大模型(≥175B参数)具有强大的建模能力,可以完成广泛任务。
-
小模型(≤11B参数)具有有限能力,但如果专注于特定任务,效果可以有明显提升。
-
作者提出模型专门化,专注模型能力于特定任务。
-
作者表明:实现多个任务的平衡是一个微妙问题,单个任务上的提升可能破坏其他任务;但通过有意牺牲广度,作者清楚地改善了10B以下多种模型尺寸,有较好的多步数学推理能力。
-
进一步讨论了几个设计选择如数据格式组合和起始模型点来改善泛化。
-
该实践和发现可以作为在LLMs设置的新研究范式下得到更小模型专门化的重要尝试。
通过专注于特定任务,小模型可以有明显提升。这是一个有趣的方向,为在LLMs范式下得到更小模型专门化踏出重要一步。

3.Pretraining Language Models with Human Preferences
本论文概括了一种用人类反馈预训练语言模型的方法。
主要贡献:
语言模型常基于大量数据预训练,但其中数据可能包含生成后违反人类偏好的内容(虚假、冒犯、敏感信息等)。
-
作者探索了一种用人类反馈预训练语言模型的方式,使其生成与人类偏好一致的文本。
-
在3个任务上对5种用人类反馈预训练的目标进行对比,研究它们影响预训练模型的侧重点和能力。
-
条件训练(基于词的人类偏好分数学习条件概率分布)是一种最优解。
-
条件训练可使不符偏好的文本减少一量级,在无提示和对抗提示生成下效果一致。
-
条件训练也保持标准预训练模型下游任务效能,即使在特定任务微调后仍然有效。
-
与标准预训练后在特定任务微调时使用人类反馈相比,用人类反馈预训练可更好满足偏好。
结果说明,相比模仿学习,预训练时应考虑人类偏好,以避免后续不想要的行为。
4.Whose Opinions Do Language Models Reflect?
作者总结了一种量化语言模型观点的框架。
主要贡献:
语言模型越来越用于开放上下文,其反应的观点对用户满意度和社会观点形成有重大影响。
-
作者提出一种量化框架来调查语言模型观点 - 使用高质量的民意调查和相应的人类反应。
-
使用该框架,作者创建 OpinionsQA 数据集,评估60个美国人口群体在 abortion 到 automation 范围话题上语言模型观点的一致性。
-
作者发现当前语言模型和美国人口群体观点存在重大不一致性:与美国民主党和共和党在气候变化上的分歧相当。
-
即使明确驱动语言模型朝特定人口群体,不一致性仍存在。
-
分析不仅证实某些语言模型存在偏左趋势,而且表明当前语言模型 poorly reflected 65+ 年龄和守寡人口群体观点。

5.Mimetic Initialization of Self-Attention Layers
这篇论文总结了一种使用学习线索初始化Transformer自注意力权重的技巧。
主要贡献:
训练小数据集的Transformer存在困难,通常使用预训练模型作为起点。
-
作者分析预训练Transformer权重,(特别是用于视觉),尝试找到这一差异的原因。
-
初始化自注意力权重"看起来"更像预训练权重,可以更快更高的准确度训练基本的Transformer,特别在CIFAR-10和ImageNet分类这样的视觉任务中。
-
作者的初始化方案将查询和键值的乘积设置为近似单位矩阵,将值和投影权重的乘积设置为近似负单位矩阵。
-
由于这模拟了我们在预训练Transformer中看到的模式,作者称该技巧为"模仿初始化"。
实验证明这一简单技巧可以有效地训练Transformer,特别是在视觉任务上。这表明预训练Transformer的权重具有学习线索可供提取。

6.Cross-Modal Fine-Tuning: Align then Refine
作者提出了一种跨模态微调大规模预训练模型的框架ORCA。
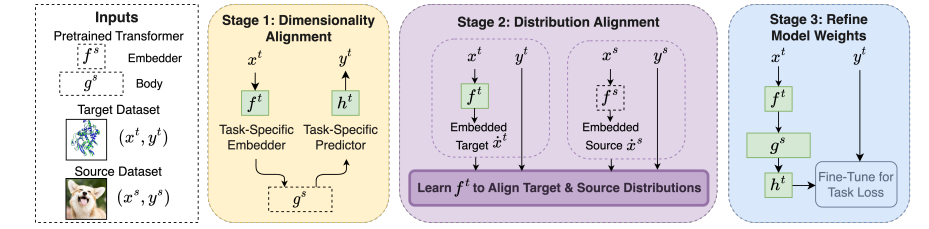
主要贡献:
微调大规模预训练模型带来了视觉和自然语言处理等模态的重大进步。但由于缺少相关的预训练模型,许多其他模态没有获得类似的益处。
-
作者提出ORCA,一种泛模态微调框架,扩展单个大规模预训练模型到多种模态的适用性。
-
ORCA 通过"对齐-微调"工作流来适应目标任务:给予目标输入,ORCA 首先学习一个嵌入网络,使嵌入特征分布与预训练模态一致。
-
然后在嵌入数据上微调预训练模型,利用模态间共享的知识。
-
大量实验表明ORCA在3个基准上获得state-of-the-art结果,包含来自12个模态的60多个数据集,超过广泛范围的人设计、自动机器学习、通用和特定任务方法。
作者强调数据对齐对性能的重要性,并展示ORCA在数据有限情况下的效用。
7.Evaluating Self-Supervised Learning via Risk Decomposition
作者提出了一种用于分析自监督学习模型设计选择的风险分解方法。
主要贡献:
自监督学习方法在设计上存在很多选择,如架构、数据提升、预训练数据等。但自监督学习通常只用一个ImageNet线性探针指标来评估。为了弥补此不足,作者提出自监督学习风险分解,它泛化了经典监督学习抽象-估计分解,考虑表示学习步骤产生的错误。
作者的分解包含4个错误成分:抽象化、表示可用性、探针泛化、编码器泛化。作者提供每个成分的有效估计器,并使用它们分析30种设计选择影响169个自监督视觉模型在ImageNet上的结果。
作者的分析给出宝贵的自监督设计及使用建议。例如,它强调主要错误来源,并展示如何通过折衷不同错误成分改进特定场景(全样本vs少样本)下的自监督学习。
8.Delving into Noisy Label Detection with Clean Data
论文提出了一种利用少量干净数据的方法来提高混乱标签检测的性能。
主要贡献:
混乱标签检测是学习混乱标签的数据的一个关键要素。许多先前的工作都假设在混乱标签检测的上下文中,没有标签来源是干净的。本文放松这个假设,假设训练数据的一个小子集是干净的,这使混乱标签检测性能有了显著改进。
-
具体来说,作者提出了一个新框架,用多重假设检验的问题形式来利用干净数据进行混乱标签检测。
-
作者提出BHN,一种简单有效的混乱标签检测方法,它将Benjamini-Hochberg(BH)过程整合到深层神经网络中。
-
BHN在CIFAR-10上在假阳性率(FDR)上超过基线28.48%,在F1指标上超过18.99%,取得state-of-the-art成绩。
-
进一步的模糊研究进一步证实了BHN的优越性。
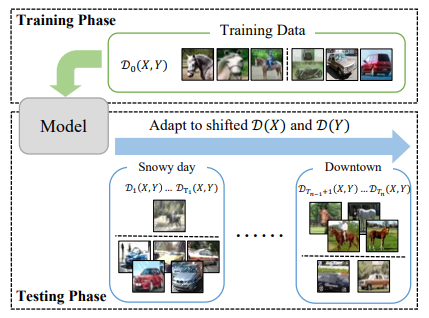
9.ODS: Test-Time Adaptation in the Presence of Open-World Data Shift
作者提出了一种名为“Test-time adaptation with Open-world Data Shift”(AODS)的新问题设置。
主要贡献:
测试时域适应是在没有源数据的情况下,使源模型适应测试数据分布转换。在过去十年,大量算法关注特征空间分布变化(特征分布Dt(X)不同于源数据)。然而在实际应用场景中,标签分布变化Dt(Y)也是必要考虑的,而这一点尚未充分探索。
为了解决这个问题,作者提出一个新的设置:测试时域适应开放世界数据转换(AODS)。
-
其目标是同时适应测试阶段的特征空间和标签分布转换。
-
作者首先分析分类错误和分布转换的关系。
-
基于此,提出ODS框架,分离混合的分布转换,然后分别处理特征空间和标签分布转换。
-
在不同类型分布转换的benchmark上实验,结果表明研究者的方法优于现有方法。
-
而且ODS适合许多测试时域适应算法。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“ICML”免费领取论文原文+代码合集
码字不易,欢迎大家点赞评论收藏!















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









