







前言
因为最近的工作重点是Nintendo Switch上的图形优化,所以需要对其GPU架构以及硬件流水线有一定的了解。而NS使用的是NVidia的Tegra X1 SoC芯片,其GPU是Maxwell架构的。一般认为,桌面级GPU是IMR渲染,而移动GPU是TBR/TBDR的。但是NVidia从Maxwell架构开始(比如NS的TegraX1,桌面级的GeFore GTX970),包括后面的Pascal架构的1000系列,已经引入了Tile-based的光栅化。在网上搜到一篇文章 Tile-based Rasterization in Nvidia GPUs,该文介绍了一个实验,作者使用一个特定的Shader去绘制一组三角形,通过控制渲染的像素总数量来研究不同GPU的光栅化模式。本文是对此文中视频所进行的实验的总结和分析。
实验介绍和IMR GPU的光栅化模式
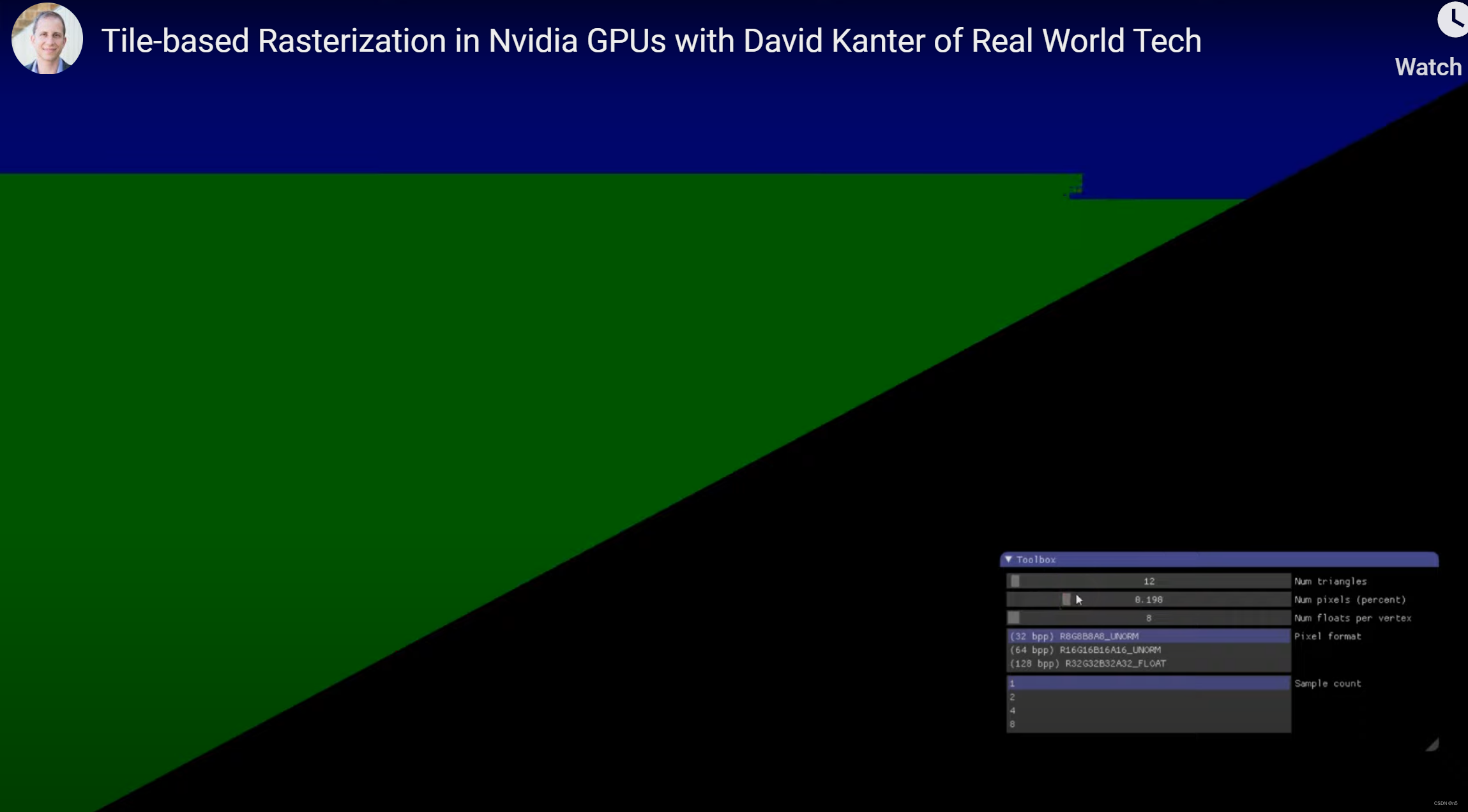
视频所描述的实验,使用一个特定的shader去绘制一组三角形,这些三角形在shader中被设置顶点位置为屏幕的左上角,右上角和左下角。并且可以在Shader中设置三角形数量,全局可绘制的像素的百分比,每个三角形的顶点属性的floats数量,像素格式和采样数。即上图截图中,右下角的从上到下的选项。三角形的颜色是从7个设定好的颜色中选择,相邻三角形是不同的颜色。具体的shader在这儿:triangles.hlsl
上图中,是使用了AMD的某个桌面GPU,是传统的立即渲染模式(IMR)。整个实验都绘制12个三角形。IMR的情况下,这12个三角形是整个屏幕范围内从上到下,从右向左光栅化的,并且是首先光栅化完成一个完整的三角形才会继续光栅化下一个三角形。上图是其中一个情况,此时下面的绿色三角形其实已经完全光栅化(以及已经被覆盖的其他的三角形已经完全光栅化),而蓝色的三角形只是光栅化了一部分。这是因为shader限制了总体的渲染的像素数量,导致绿色三角形的一部分像素,以及后面其他三角形的所有像素都被丢弃了。而在实验中,通过逐渐向右拖动第二个条,即增大总体渲染的像素数百分比,就可以看到光栅化的大概的顺序。在IMR模式的GPU下,增大顶点的floats数量(即增大三角形顶点属性数据量)并不会对光栅化顺序产生影响;修改像素格式,增大每个像素的比特数也不会影响光栅化顺序;而修改Sample Count,即多重采样的采样数(如果为1就不使用多重采样),对于光栅化总体顺序也没什么影响。总之,对于IMR的GPU,光栅化模式是逐个三角形,对于整个屏幕的像素,从上往下,从右往左进行。当然这其中会有一些包围盒之内的检测优化,不至于检测太多不在三角形内部的像素,但这不是重点。
Nvidia Maxwell架构GPU的光栅化模式
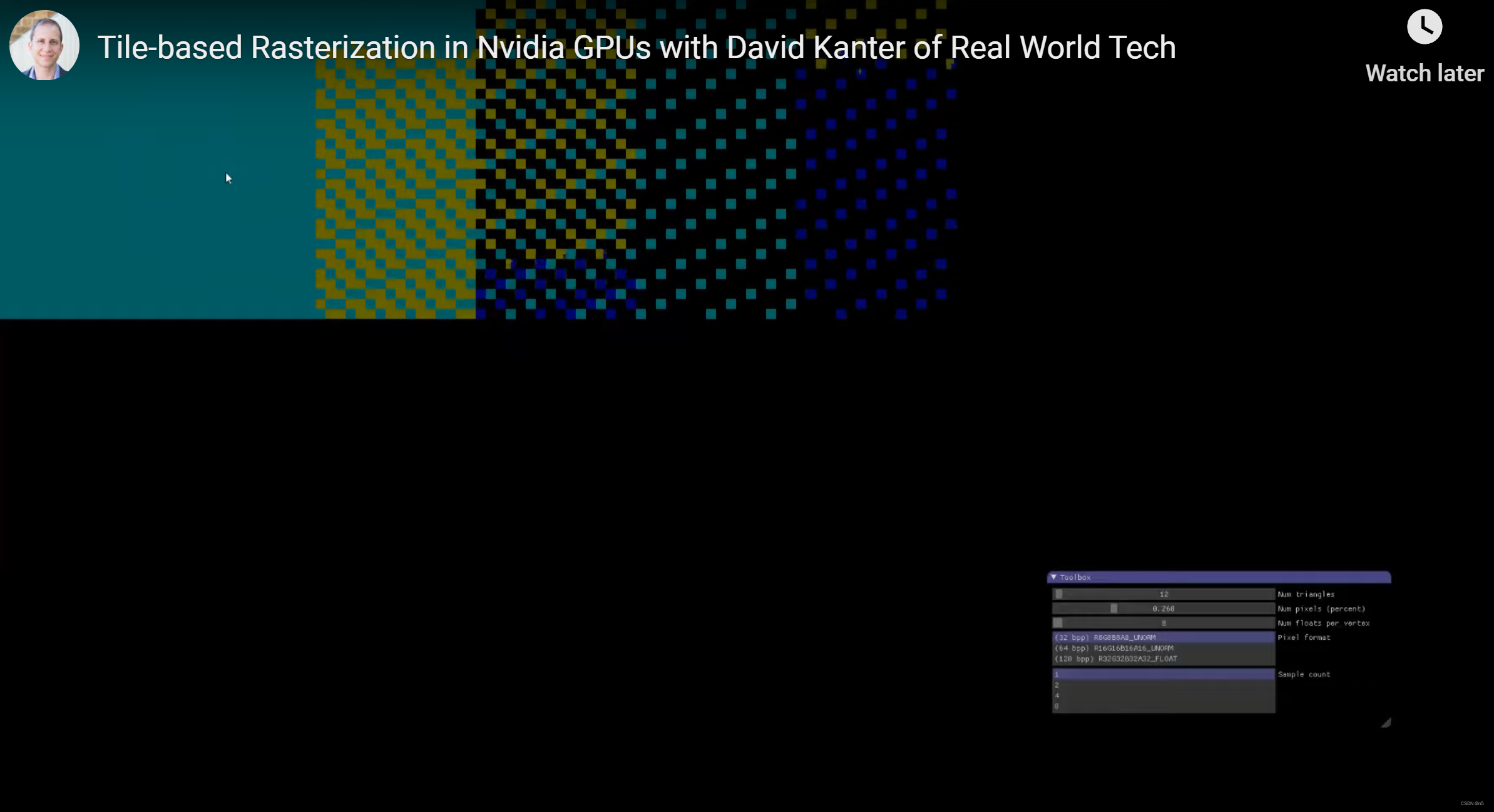
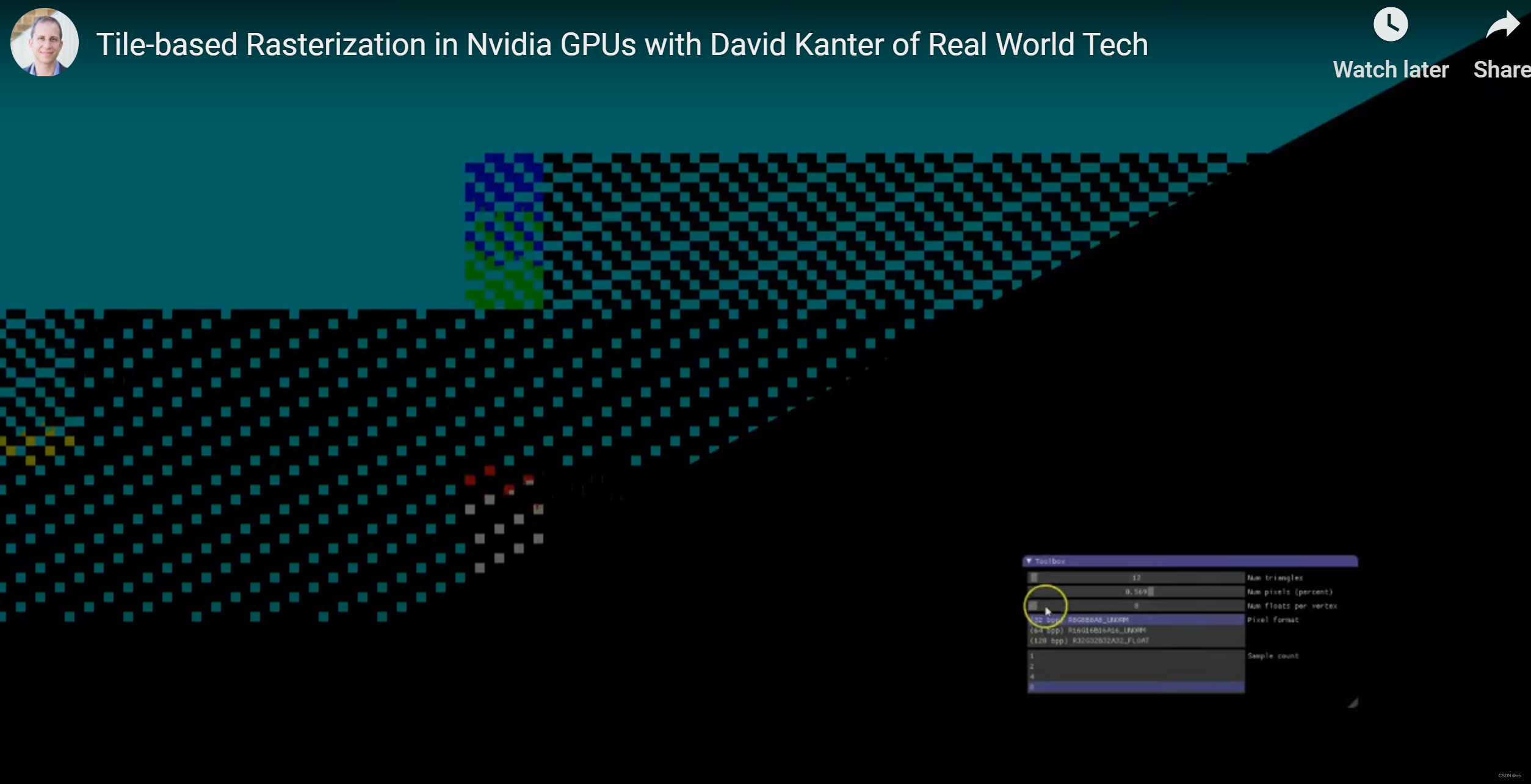
这两幅图是NVidia GeForce GTX970下面进行实验的截图,分别是较小和较大两个最大像素百分比参数。很明显,在GTX970中,光栅化是按Tile为单位进行的。先看第一个图,左上角蓝色部分是已经光栅化完毕的Tile,右边蓝黄相间的棋盘格部分的Tile正在光栅化黄色和蓝色的三角形,再右边出现了黑色的像素, 那是Tile中还没有进行光栅化后并渲染的像素,且黄色和蓝色棋盘格更稀疏,说明黄色和蓝色的三角形在Tile中光栅化了一小部分,右边还出现了深蓝色的像素,说明是深蓝色的三角形在这些Tile上正在光栅化。
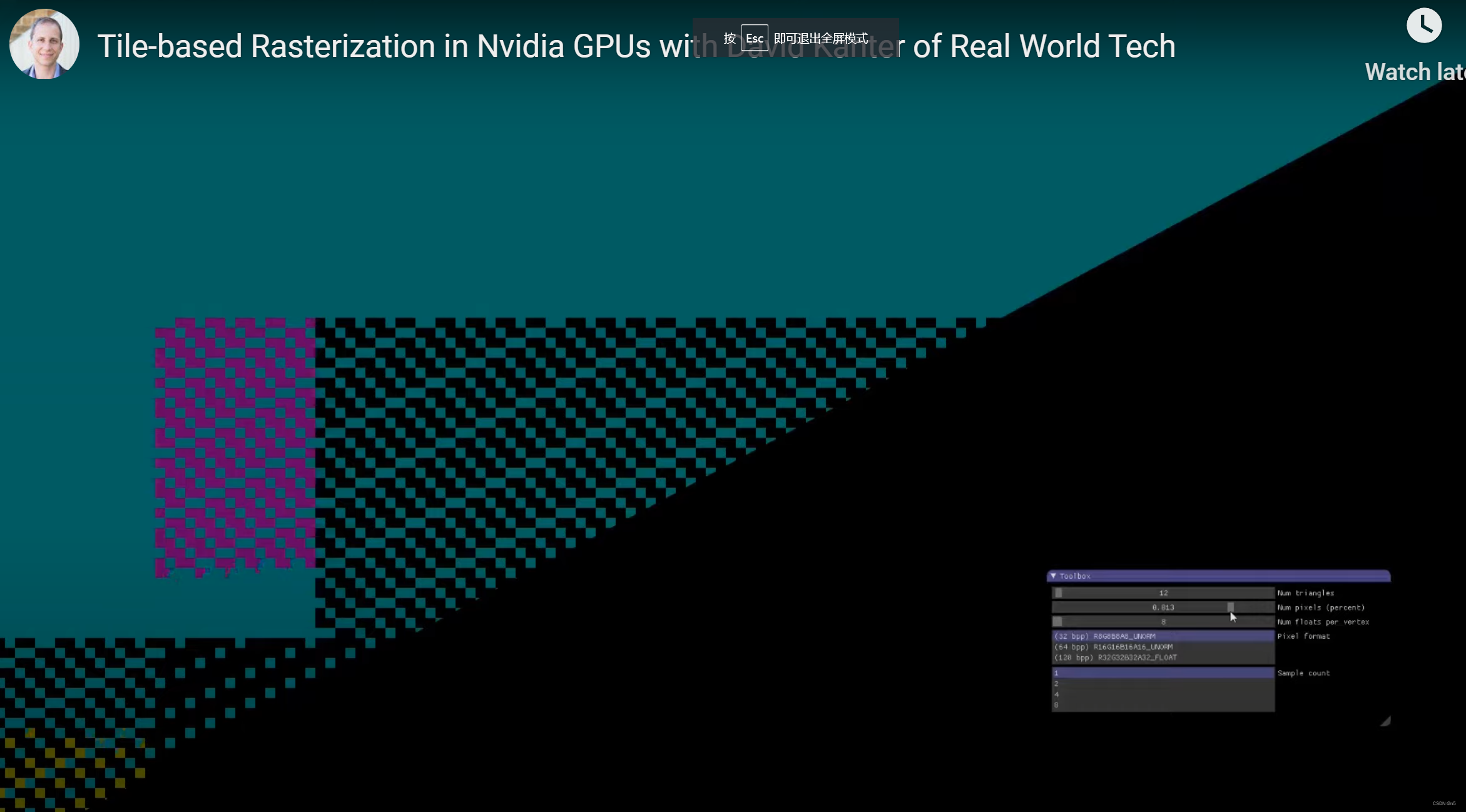
随着我们增大允许的最大像素数百分比,可以看到Tiles是按照从左往右,从上往下进行光栅化。例如上图的这个状态,前几行之前没有完全光栅化的Tile已经光栅化完毕,而下面有剩余的没有完全光栅化的Tile。而在Tile内部,是按照这种棋盘格的模式进行光栅化。这儿的核心观察是,GTX970是逐个Tile进行光栅化的,虽然不是严格的一个接一个光栅化,而是存在一定的并行性,但总体上是按照从左往右,从上往下的顺序,逐个光栅化Tile。
增大顶点数据量
上图中,每个顶点的Floats数为8,现在将Floats数增大到24,而其他参数不变,结果如下图:

可以看到,Tile的尺寸没变,但是同时进行光栅化的Tile数目减少了。
我们将像素上限调低,再对比一下Floats值小和大的情况:


很明显,增大顶点数据量后,对于相同数量的总像素数量,集中处理更少数的Tile,所以看上去,同时处理的Tile减少了,且部分光栅化的Tile中的像素密度增加了。这应该是因为由于每个顶点的数据变多,On-Chip Cache能同时容纳的Tile光栅化相关的数据减少,因此能同时处理的Tile数量减少。但是这个数据的改变并不改变Tile的尺寸。
增大像素比特数
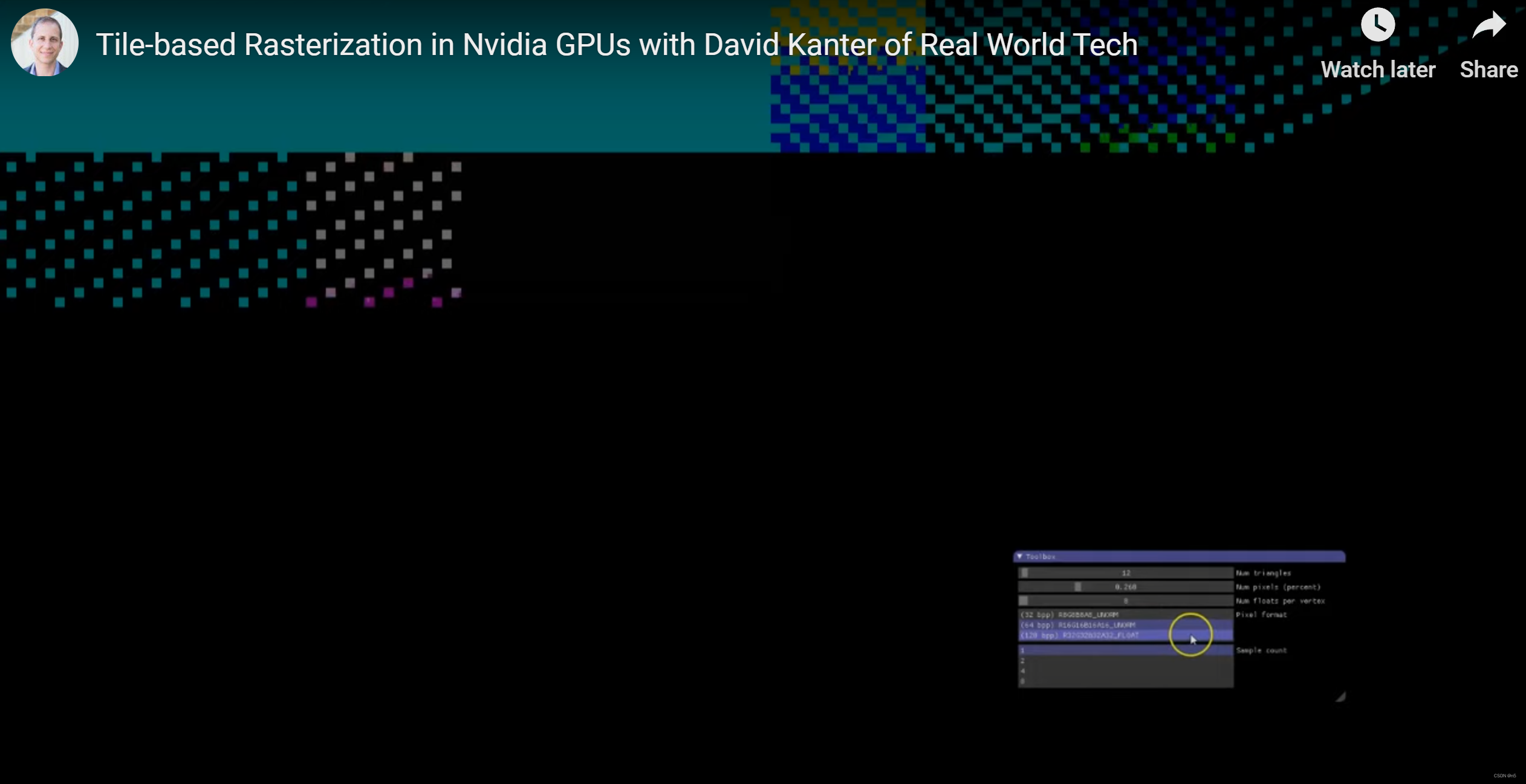
每个像素所占的比特数增加后,Tile的尺寸变小了,因此可以猜测这也是为了将Tile所需数据容纳在On-Chip cache中。
增大采样数
Tile同样会变小。
同时增大像素比特数和采样数
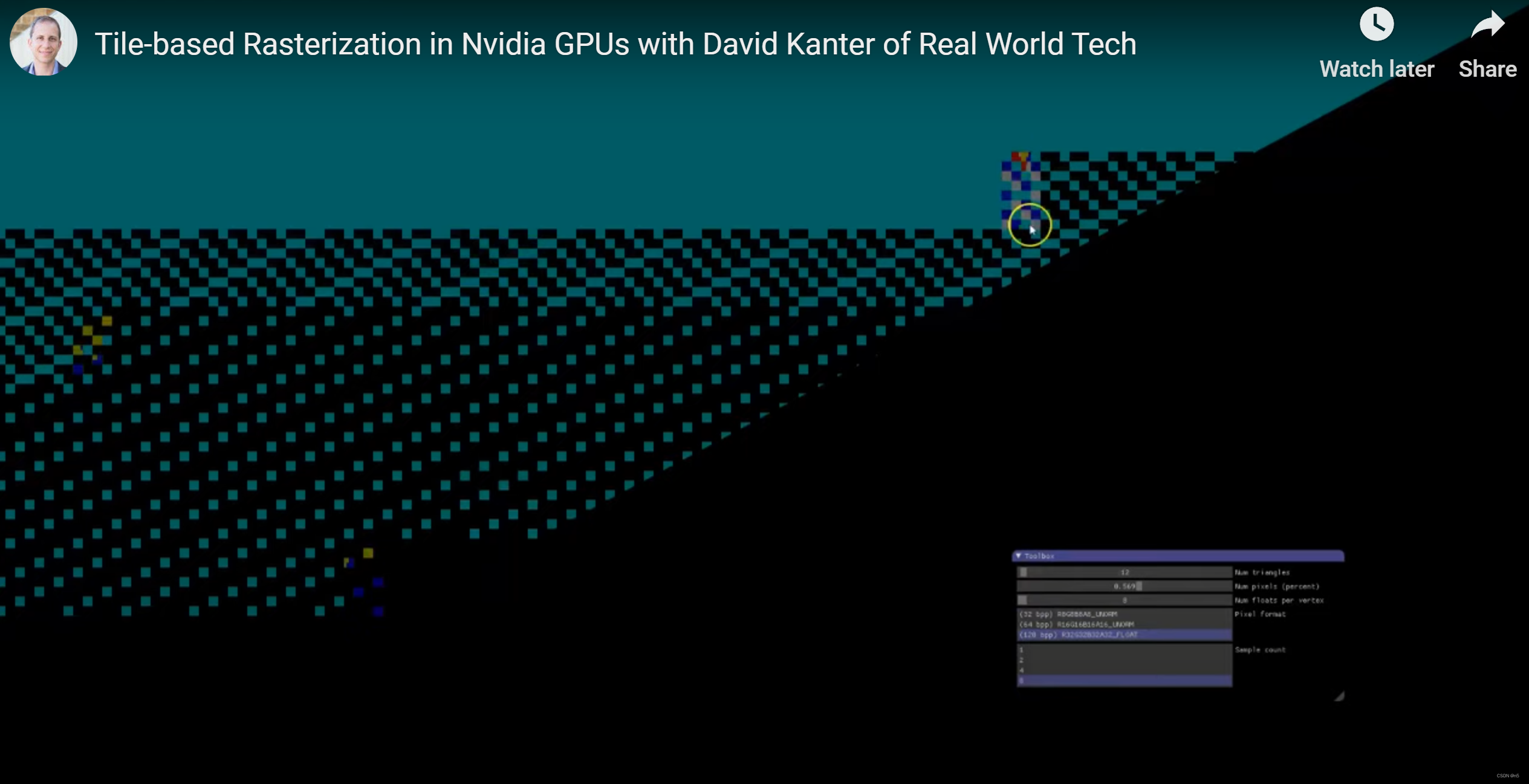
Tile变得更小了。所以,可以猜测还是为了能让数据容纳在固定的On-Chip cache中。
实验总结
- NVidia Maxwell GPU使用Tile-based的立即渲染模式(非TBR)
- 顶点属性数据量增大会导致同时处理的Tile减少
- 像素比特数增加,以及采样数增加,会导致Tile尺寸变小(并且Tile可能变成矩形)
关于本实验的争议
原文章(见参考资料1)的评论中,有一些争议,比如说Maxwell的Tiled-based不是光栅化而是一种按tile组织的缓存优化,以及有人说看到不同顺序的渲染是因为线程调度的顺序。但实际上,Maxwell架构确实是一种Tiled-based的光栅化渲染。NVidia在GDC上已经明说了,L2Cache中存储了Tile buffer,L2 Cache是作为后续渲染的输入的,所以原文评论里面有的争议和疑问已经得到解释了。
Maxwell架构中关于Tiled-base的简单说明
我后来是在NS的资料里面看到Maxwell的技术总览中,关于Tiled-base其实做了比较详细的说明。简单来说,所有三角形顶点被处理后,通过一个硬件单元就行Tile分块,然后分块后进行光栅化和渲染,这其中的数据都是直接使用L2Cache保存,而L2Cache中有一定比例的存储容量可以配置为Tilebuffer,比如1/3的容量,因此Tile的尺寸是根据这个总容量再除以Tile使用的数据量,比如上面测试的像素比特和采样数等,因此Tile尺寸是可变的。而光栅化本身又分为粗和精两部分,所谓粗光栅化是将Tile再细分为16x16像素的块进行Z-Cull。所谓Z-Cull是使用一个低分辨率的Zbuffer数据进行深度剔除。然后再进行精光栅化,大概是8x8的像素块为单位进行。这些操作都是直接在L2Cache上进行,所以节省了很多带宽,并且MSAA也是在L2上计算。更详细的细节我并没有在NVidia的公开资料上找到(GDC也没去找),而NS的资料不方便公开,所以就不细写了。总之,Maxwell的Tiled-base是和移动端的TBR/TBDR不太一样的,看上去还是比较直接的,还是属于IMR的范围,只是会使用一个比较大的L2Cache(从Maxwell开始,L2Cache的尺寸增大了不少)分块进行光栅化和渲染,可能移动端不会有那么大的On-Chip cache吧,所以两边的流程不太一样。如果找到Maxwell的公开资料,我希望能写一篇文章和移动端进行详细的对比。
ps: 从网上找到一张图:
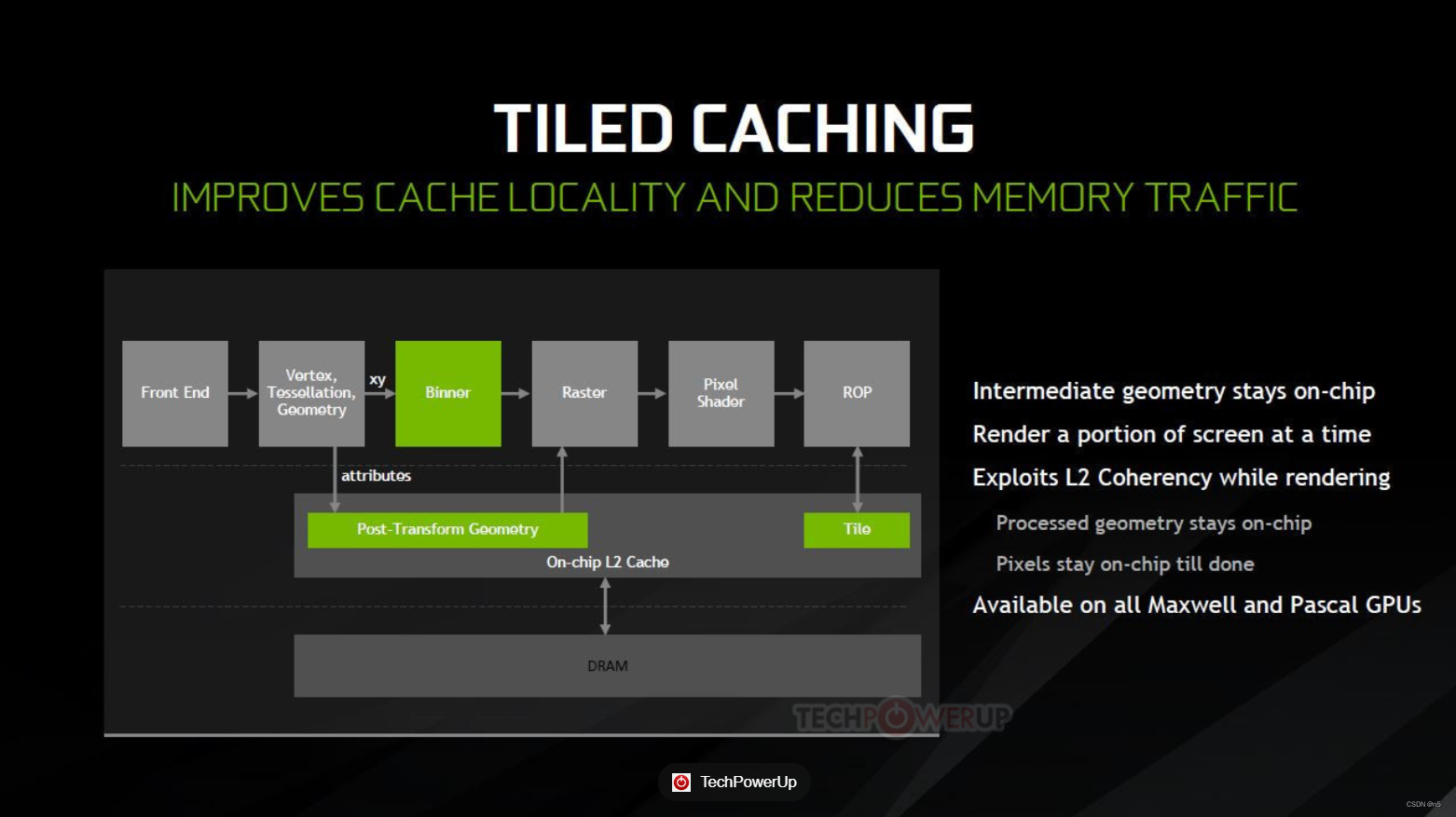


















 4841
4841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











