







原理介绍
ByteTrack是字节跳动与2021年10月份公开的一个全新的多目标跟踪算法,原论文是《ByteTrack: Multi-Object Tracking by Associating Every Detection Box》。
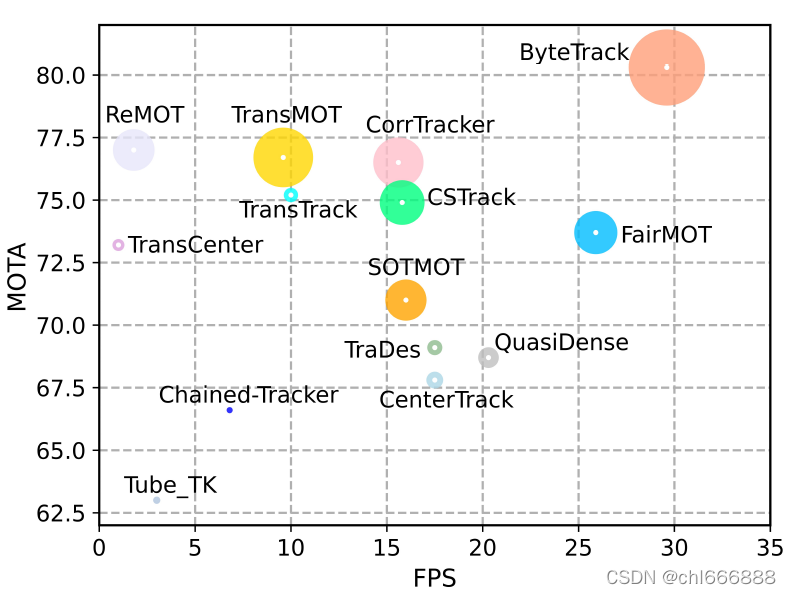
ByteTrak的MOTA和FPS等指标上都实现了较好的性能,要优于现有的大多数MOT(多目标追踪)算法。
github地址:https://github.com/ifzhang/ByteTrack
演示:
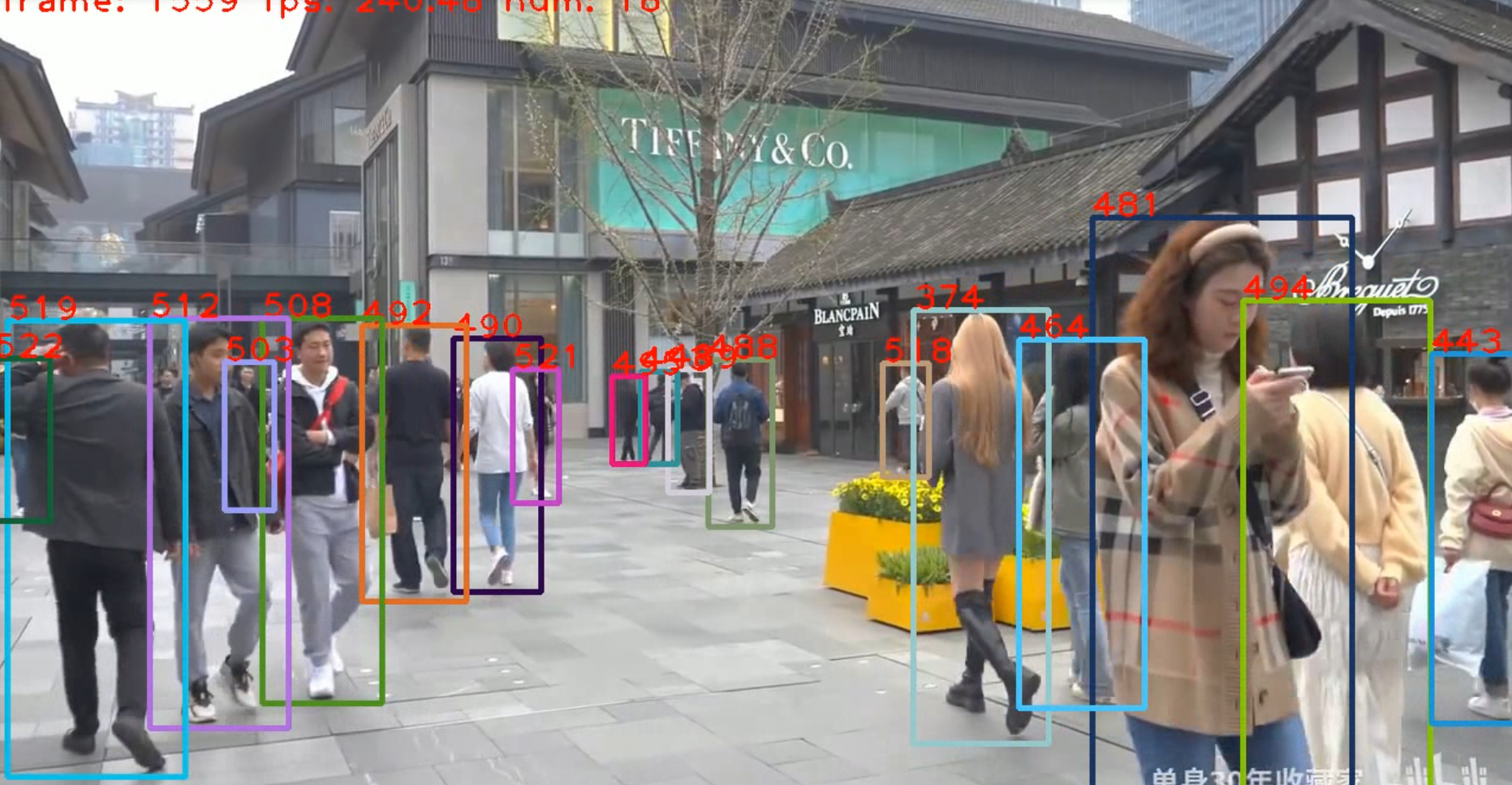

ByteTrack 算法demo
ByteTrack介绍
先前的多目标追踪算法一般在完成当前帧的目标检测后只会保留置信度比较大的检测框用于进行目标跟踪,比如图中置信度为0.9和0.8的目标框。
而在ByteTrack中,作者保留了所有的检测框并且通过阈值将它们分成了高置信度检测框和低置信度检测框。ByteTrack 可以有效解决一些遮挡,且能够保持较低的 ID Switch。因为目标会因为被遮挡检测置信度有所降低,当重新出现时,置信度会有所升高。算法特点在于:
- 当目标逐渐被遮挡时,跟踪目标与低置信度检测目标匹配。
- 当目标遮挡逐渐重现时,跟踪目标与高置信度检测目标匹配。
算法基本原理
ByteTrack 并不是连接所有检测框形成一个追踪轨迹,而是通过预测和验证的方法来确定追踪轨迹。对于每一个轨迹使用卡尔曼滤波来预测轨迹下一个位置(预测框),然后计算检测框和预测框的IOU,最后通过匈牙利算法匹配IOU,返回匹配成功和失败的轨迹。
追踪算法的详细步骤:
- 在开始追踪之前给每一目标创建追踪轨迹
- 通过卡尔曼滤波预测每一个追踪轨迹的下一帧边界框
- 通过检测器获得目标的检测框,根据置信度将检测框分为高分框和低分框
- 首先针对高分框,计算高分框和预测框的IOU ,使用匈牙利算法匹配IOU,获得3个结果:已匹配的轨迹与高分框,未成功匹配的轨迹,未成功匹配的高分框。匹配成功后将追踪轨迹中的框更新为高分检测框
- 然后针对低分框,计算低分框和上一步未匹配上的预测框的IOU,使用匈牙利算法匹配IOU,获得3个结果:已匹配的轨迹与低分框,未成功匹配的轨迹,未成功匹配的低分框。匹配成功后将追踪轨迹中的框更新为检测框
- 最后针对未匹配上的高分检测框,将其和状态未激活的轨迹匹配,获得3个结果:匹配、未匹配轨迹、未匹配检测框。对于匹配更新状态,对于未匹配轨迹标记为删除,对于未匹配检测框,置信度大于高阈值+0.1新建一个跟踪轨迹,小于则丢弃。
代码实现
在介绍代码之前首先要了解基础概念。ByteTrack 主要由两个类组成,一个是轨迹管理类STrack,一个轨迹匹配逻辑处理类BYTETracker。
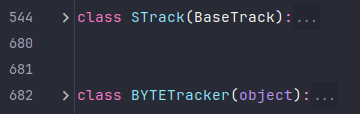
- STrack:轨迹的创建,更新,删除
- BYTETracker:匹配流程处理,置信度高低划分、轨迹匹配等
STrack
Strack 是轨迹的类,每一个实例都是一个轨迹。Strack拥有核心方法包括:
- multi_predict 卡尔曼滤波预测
- activate 轨迹创建
- re_activate 轨迹重新激活
- update 轨迹更新
# 这个类是用来存放轨迹的,每个轨迹都有一些自己的属性,例如id、边界框、预测框、状态等等
class STrack(BaseTrack):
# 单例模式
shared_kalman = KalmanFilter()
def __init__(self, tlwh, score):
self._tlwh = np.asarray(tlwh, dtype=np.float)
self.kalman_filter = None
# 保存卡尔曼滤波对这个轨迹的平均值和协方差
self.mean, self.covariance = None, None
# 是否是激活状态
self.is_activated = False
# 轨迹分数
self.score = score
# 轨迹追踪的帧数,每次追踪成功都会+1
self.tracklet_len = 0
def predict(self):
mean_state = self.mean.copy()
if self.state != TrackState.Tracked:
mean_state[7] = 0
self.mean, self.covariance = self.kalman_filter.predict(mean_state, self.covariance)
@staticmethod
def multi_predict(stracks):
if len(stracks) > 0:
multi_mean = np.asarray([st.mean.copy() for st in stracks])
multi_covariance = np.asarray([st.covariance for st in stracks])
for i, st in enumerate(stracks):
if st.state != TrackState.Tracked:
multi_mean[i][7] = 0
multi_mean, multi_covariance = STrack.shared_kalman.multi_predict(multi_mean, multi_covariance)
for i, (mean, cov) in enumerate(zip(multi_mean, multi_covariance)):
stracks[i].mean = mean
stracks[i].covariance = cov
def activate(self, kalman_filter, frame_id):
"""Start a new tracklet"""
self.kalman_filter = kalman_filter
self.track_id = self.next_id()
self.mean, self.covariance = self.kalman_filter.initiate(self.tlwh_to_xyah(self._tlwh))
self.tracklet_len = 0
self.state = TrackState.Tracked
if frame_id == 1:
self.is_activated = True
# self.is_activated = True
self.frame_id = frame_id
self.start_frame = frame_id
def re_activate(self, new_track, frame_id, new_id=False):
self.mean, self.covariance = self.kalman_filter.update(
self.mean, self.covariance, self.tlwh_to_xyah(new_track.tlwh)
)
self.tracklet_len = 0
self.state = TrackState.Tracked
self.is_activated = True
self.frame_id = frame_id
if new_id:
self.track_id = self.next_id()
self.score = new_track.score
def update(self, new_track, frame_id):
"""
Update a matched track
:type new_track: STrack
:type frame_id: int
:type update_feature: bool
:return:
"""
self.frame_id = frame_id
self.tracklet_len += 1
new_tlwh = new_track.tlwh
self.mean, self.covariance = self.kalman_filter.update(
self.mean, self.covariance, self.tlwh_to_xyah(new_tlwh))
self.state = TrackState.Tracked
self.is_activated = True
self.score = new_track.score
@property
# @jit(nopython=True)
def tlwh(self):
"""Get current position in bounding box format `(top left x, top left y,
width, height)`.
"""
if self.mean is None:
return self._tlwh.copy()
ret = self.mean[:4].copy()
ret 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2663
2663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









