






简介
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务。
YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。在图像检测识别领域yolov8和yolov5是使用较多的两款框架,兼顾精度和速度。
本文讲解yolov8自带的一个实时目标检测页面的使用。页面如下,可以在页面上体验yolov8上所有的模型,包括目标检测、分类、分割、姿态、定向框。

安装
- 创建虚拟环境
conda create --name yolov8 python=3.10 -y
conda activate yolov8
- 安装pytorch
conda install pytorch2.2.0 torchvision0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
由于numpy版本会导致报错,需要降低numpy版本
conda install numpy==1.26.2
- 下载工程
git clone --branch v8.2.103 https://github.com/ultralytics/ultralytics.git
使用 --branch v8.2.103 选择yolov8版本
- 安装工程
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
- 测试推理
yolo predict model=yolov8n.pt source=‘ultralytics/assets/zidane.jpg’ device=0
yolo predict model=yolov8n.pt source='ultralytics/assets/zidane.jpg' device=0
Ultralytics YOLOv8.2.103 🚀 Python-3.10.16 torch-2.2.0 CUDA:0 (NVIDIA GeForce RTX 2080 Ti, 11004MiB)
YOLOv8n summary (fused): 168 layers, 3,151,904 parameters, 0 gradients, 8.7 GFLOPs
image 1/1 /nfs/user_home/lijinkui/projects/ultralytics/ultralytics/assets/zidane.jpg: 384x640 2 persons, 1 tie, 86.8ms
Speed: 7.0ms preprocess, 86.8ms inference, 209.4ms postprocess per image at shape (1, 3, 384, 640)
Results saved to runs/detect/predict
💡 Learn more at https://docs.ultralytics.com/modes/predict
推理结果在:Results saved to runs/detect/predict
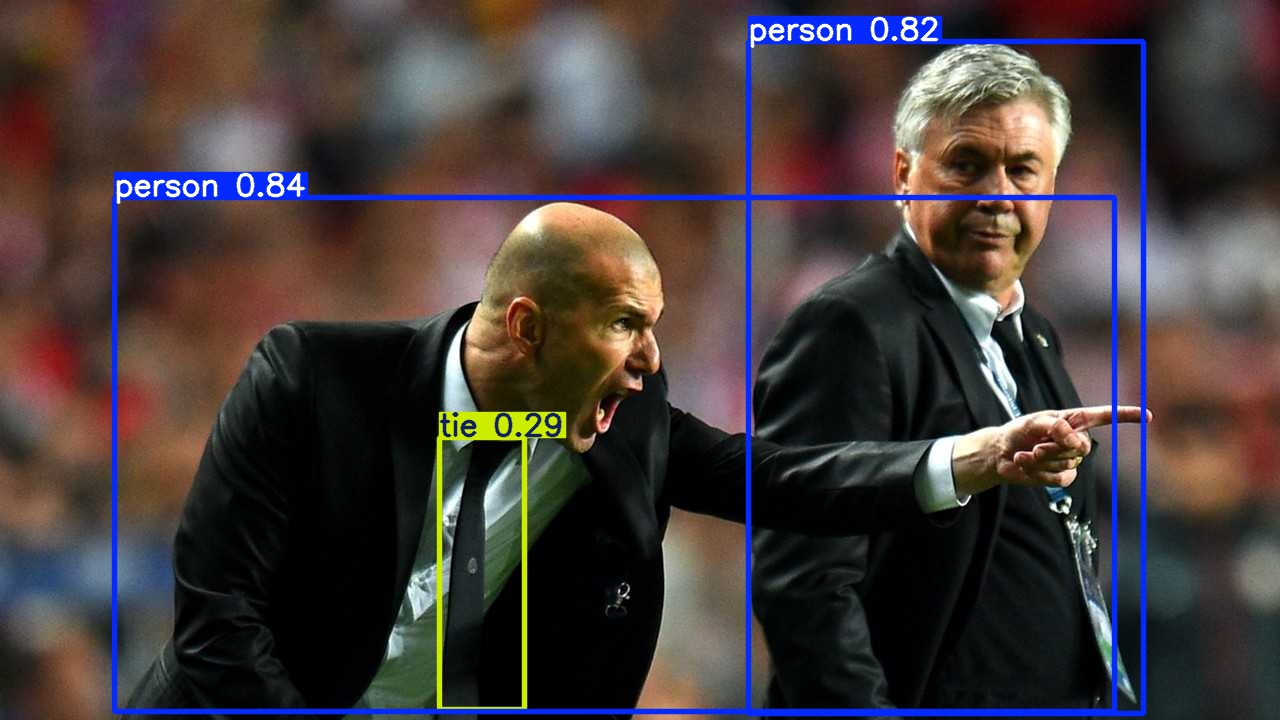
到此为止就说明yolov8安装没有问题了。
训练
使用官方数据测试训练:
yolo detect train data=coco8.yaml model=yolov8n.pt epochs=10 imgsz=640
页面展示
yolov8自带一个推理的前端页面,下面说明开启的步骤。
首先使用 yolo help 这个命令查看yolo的帮助信息
(yolov8) lijinkui@node07:~/$ yolo help
Arguments received: ['yolo', 'help']. Ultralytics 'yolo' commands use the following syntax:
yolo TASK MODE ARGS
Where TASK (optional) is one of {'segment', 'detect', 'classify', 'pose', 'obb'}
MODE (required) is one of {'predict', 'val', 'train', 'export', 'track', 'benchmark'}
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
See all ARGS at https://docs.ultralytics.com/usage/cfg or with 'yolo cfg'
1. Train a detection model for 10 epochs with an initial learning_rate of 0.01
yolo train data=coco8.yaml model=yolov8n.pt epochs=10 lr0=0.01
2. Predict a YouTube video using a pretrained segmentation model at image size 320:
yolo predict model=yolov8n-seg.pt source='https://youtu.be/LNwODJXcvt4' imgsz=320
3. Val a pretrained detection model at batch-size 1 and image size 640:
yolo val model=yolov8n.pt data=coco8.yaml batch=1 imgsz=640
4. Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,128
5. Explore your datasets using semantic search and SQL with a simple GUI powered by Ultralytics Explorer API
yolo explorer data=data.yaml model=yolov8n.pt
6. Streamlit real-time webcam inference GUI
yolo streamlit-predict
7. Run special commands:
yolo help
yolo checks
yolo version
yolo settings
yolo copy-cfg
yolo cfg
Docs: https://docs.ultralytics.com
Community: https://community.ultralytics.com
GitHub: https://github.com/ultralytics/ultralytics
可以看到yolo出来训练,推理等任务之后还有两个功能,分别是5和6。其中6就是一个可以在前端推理的功能。
启动推理功能,这里需要魔法,从github下载推理模型。或者下载好放在跟目录下也行
yolo streamlit-predict
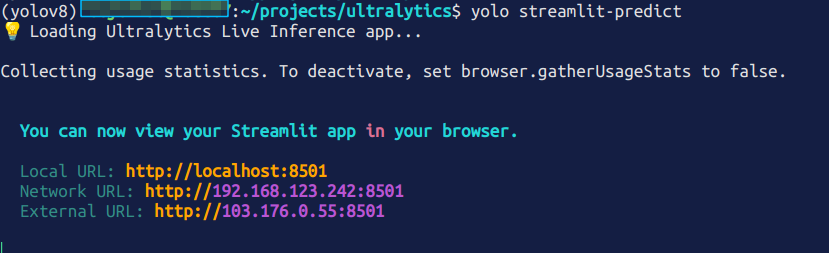
打开浏览器页面

参数包括:
- Video: 选择推理源摄像头或视频
- Model: 选择模型,yolov8的所有模型都能选择,包括检测、分类、分割、姿态、角度,甚至yolo-word
- Classes: 选择推理的类别
- 下面还有置信度控制。
点击Start就可以看到推理结果了。
演示视频
检测:
录屏_选择区域_20250418164111
分割:
录屏_选择区域_20250418164208
姿态:
录屏_选择区域_20250418164304
角度:
录屏_选择区域_20250418164359

















 3643
3643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









