




这篇笔记用来描述2025年发表在arxiv上的一篇有关VLN领域的论文,我个人觉得其应用场景比较有意思所以写下这篇读书笔记。该论文由多伦多大学团队发布,其主要创新点在于:
- 使用手绘地图来控制实体机器人完成运动指令;
- 对手绘地图语意解析的鲁棒性提升;
【注意】:作者全篇使用了大量倒装,直接阅读会比较吃力,建议先跟着我的翻译过一遍然后再尝试自己阅读全文;
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基础的LLM与导航知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:Mobile Robot Navigation Using Hand-Drawn Maps: A Vision Language Model Approach
- 原文链接:https://arxiv.org/abs/2502.00114
- 发表时间:2025年01月31日
- 发表平台:arxiv
- 预印版本号:[v1] Fri, 31 Jan 2025 19:03:33 UTC (5,956 KB)
- 作者团队:Aaron Hao Tan、Angus Fung、Haitong Wang、Goldie Nejat
- 院校机构:University of Toronto
- GitHub仓库:【暂无】
- 项目视频:https://www.youtube.com/watch?v=2NOgwqPeIm8;
Abstract
手绘地图可以自然且高效地传达人类与机器人之间的导航指令。然而这类地图通常包含 比例失真 和 地标缺失 等不准确信息,这给导航任务带来了挑战。本文介绍了一种新颖的手绘地图导航架构 HAM-Nav,该架构利用预训练的VLMs在各种环境、手绘风格、机器人形态中进行导航,即使在存在绘制地图不准确性的情况下也能有效工作。HAM-Nav集成了一种独特的选择性视觉关联提示(Selective Visual Association Prompting)方法,用于基于拓扑地图的位置估计导航规划,以及一个预测性导航计划器(Predictive Navigation Plan Parser)来推断缺失的地标。在仿真环境中,使用轮式和足式机器人进行了广泛的实验,证明了HAM-Nav在导航成功率和路径长度加权成功率(Success weighted by Path Length)方面的有效性。此外,真实环境中的测试也证明了其实用性。
Introduction
移动机器人导航任务可能需要在动态的环境中执行,例如,搜索和救援场景中的结构不稳定性、翻新或新建过程中的施工进度、以及零售商店的重新布局。为了使机器人能够在这类环境中完成导航,可以使用基于地图的方法或无地图方法。在基于地图的方法中,精确的地图是在导航之前通过人工遥操作或自主机器人探索生成的;然而,这类地图获取存在这两个问题:成本高且耗时、需要专家知识。另一方面,无地图方法可以使用实时传感数据来表示机器人的环境;然而,现有的无地图方法需要同时进行探索和导航才能到达机器人的目标位置,由探索初级阶段会影响导航效率,表现为机器人行驶的总距离过长。
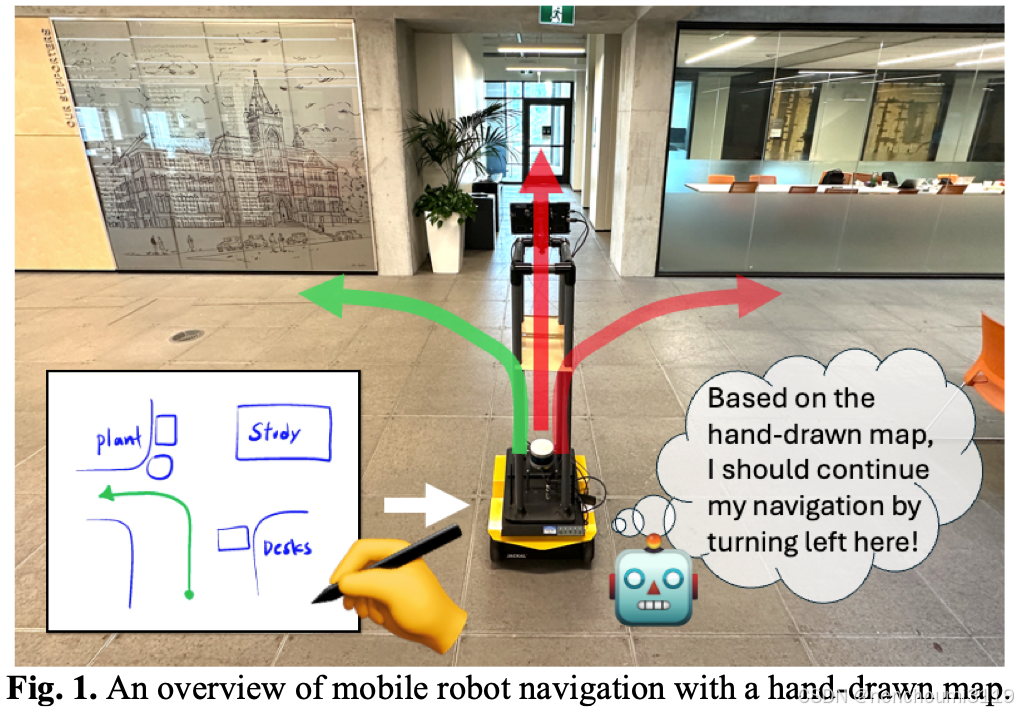
使用手绘地图进行机器人导航可以为基于地图和无地图导航方法提供一种替代方案。如图1所示。手绘地图是人们根据对环境布局记忆生成的草图,用于表示机器人环境中的空间关系。因此,手绘地图可以有效地用于机器人导航,而无需事先进行资源密集型的地图生成或在导航过程中进行同步探索。
目前为止,现有的手绘地图机器人导航方法可以分为两类:启发式方法(识别已知地标后执行预定义动作)和 概率方法(将传感数据与地图特征进行匹配后进行定位)。然而这些方法一直局限于简单环境中手绘地图的地标(如盒子和圆柱体),但该类地标不能表征真实地标(例如,家具)和多层楼层的复杂环境。同时,手绘地图还需要具有精确空间布局信息。由于人类在绘制草图时的记忆差异,这类信息在地图上很难表示出来。
在本文中,作者提出了一种新颖的手绘地图机器人导航架构 HAM-Nav,它使用预训练VLMs来解释手绘地图中的视觉和文本信息,以便在未知环境中进行机器人导航。HAM-Nav是第一个在无需特定任务训练的情况下,能够泛化到各种环境和不同手绘风格的导航方法。研究的主要贡献如下:
- 引入了一种新的自适应视觉提示方法,选择性视觉关联提示(SVAP),该方法将机器人视图与动态更新的拓扑地图并排放置,拓扑地图叠加在手绘地图之上。
- 通过使用 SVAP 能够以
zero-shot的方式估计机器人的位置并选择适当的导航动作; - 通过使用预训练的VLMs能够直接将环境特征与手绘地图中的相应元素相关联;
- 开发了一种预测性导航规划器(Predictive Navigation Plan Parser,PNPP),利用预训练VLMs的常识来推断缺失的地标信息(例如,类别和位置),以解决手绘地图中的人为错误。
Related Works
作者将手绘地图机器人导航方案分为两类:启发式方法 和 概率方法。
A. Heuristic Methods
启发式方法利用预定义的模式(例如空间邻近性)来解释手绘地图中地标的几何特征,并将它们转化为简单环境中机器人的导航命令。这些方法包括手工制作的 基于规则的方法、模糊控制方法、基于优化的方法。
- 基于规则的方法:通过结合图像分割和模糊c均值算法(fuzzy c-means algorithms)来计算客观得分,从而将手绘地图转化为导航命令。机器人在导航过程中使用这些客观得分和传感数据来更新其路径;
- 模糊控制方法:从手绘地图的像素坐标中提取空间描述,并将像素分类为多边形(地标)和线段(路径)。多边形边用于确定地标相对于机器人的位置,这些位置使用模糊规则转化为动作;
- 优化方法:通过分析地标和路径之间的空间关系,使用二次优化来计算机器人导航的路径点。手绘路径点通过虚拟弹簧连接,使用二次规划来最小化势能从而生成路径点。
B. Probabilistic Methods
概率方法利用统计模型来解释手绘地图并在其中定位机器人。这些方法包括隐马尔可夫模型、蒙特卡洛定位 MCL、贝叶斯滤波 BF、监督学习SL。
- 隐马尔可夫模型:使用手绘地图数据集训练了一个可变时长隐马尔可夫模型(VDHMM),用来识别线条线条之间的移动,从而生成机器人运动向量;
- 蒙特卡洛定位MCL:使用统计抽样技术(例如粒子滤波)来确定机器人在手绘地图中的位置,用来更新手绘地图与匹配环境的空间布局、估计地图形变;
- 贝叶斯滤波 BF:从机器人获取的全景RGB图像生成局部占用栅格地图。通过维护机器人位置的置信度,将预测的栅格地图与手绘地图对齐。预测与观察到的局部占用栅格地图之间相似度得分被用于更新机器人的估计位置。使用这个更新的置信度,通过网格搜索生成一个启发式向量以引导机器人的导航动作朝向目标;
- 一种监督学习 SL:使用基于高山的配准(alpine-based registration)来定位机器人在手绘地图中的位置。卷积神经网络来预测控制点,以引导机器人观测值与手绘地图的对齐。A*路径规划算法被用于引导机器人导航至指定目标;
C. Summary of Limitations
启发式方法使用反应式控制在受控环境中执行预定动作,这类方法无法适应环境变化,而是依赖于识别一组固定的原始地标。概率方法要求手绘地图准确地表示环境的几何形状和比例,手绘地图中的任何偏差都会导致定位错误和不精确的导航。这两种方法都已应用于单层环境,因为它们依赖于与机器人传感器读数直接相关的2D手绘地图进行定位。然而,在多层环境中,2D手绘草图无法表示垂直堆叠的楼层。此外,现有方法均假设所有基本地标都在手绘地图中正确表示,这在现实场景中是具有挑战性的,因为人为错误可能会直接将不准确性引入地图。
为了解决上述限制,作者提出了一种独特地利用VLMs的架构HAM-Nav,其具备以下功能:
- 通过使用自适应视觉提示将来自环境的视觉特征与手绘地图中的空间线索对齐,从而检测真实地标并在多层环境中实现零样本导航;
- 通过使用共现地标(co-occurrence landmark)模式预测缺失的地标,从而解决手绘地图中的人为错误;
Robot Navigation with Hand-Drawn Maps Problem Definition
使用手绘地图的机器人导航问题在于要求移动机器人利用草图传达的导航指令,在未知环境中从给定的起始位置自主导航到期望的位置。使用 M h = ( S h , L h , P h ) M_{h}=(S_{h},L_{h},P_{h}) Mh=(Sh,Lh,Ph) 表示人基于自身记忆的手绘的草图,其由三部分组成如 Fig.2 所示:
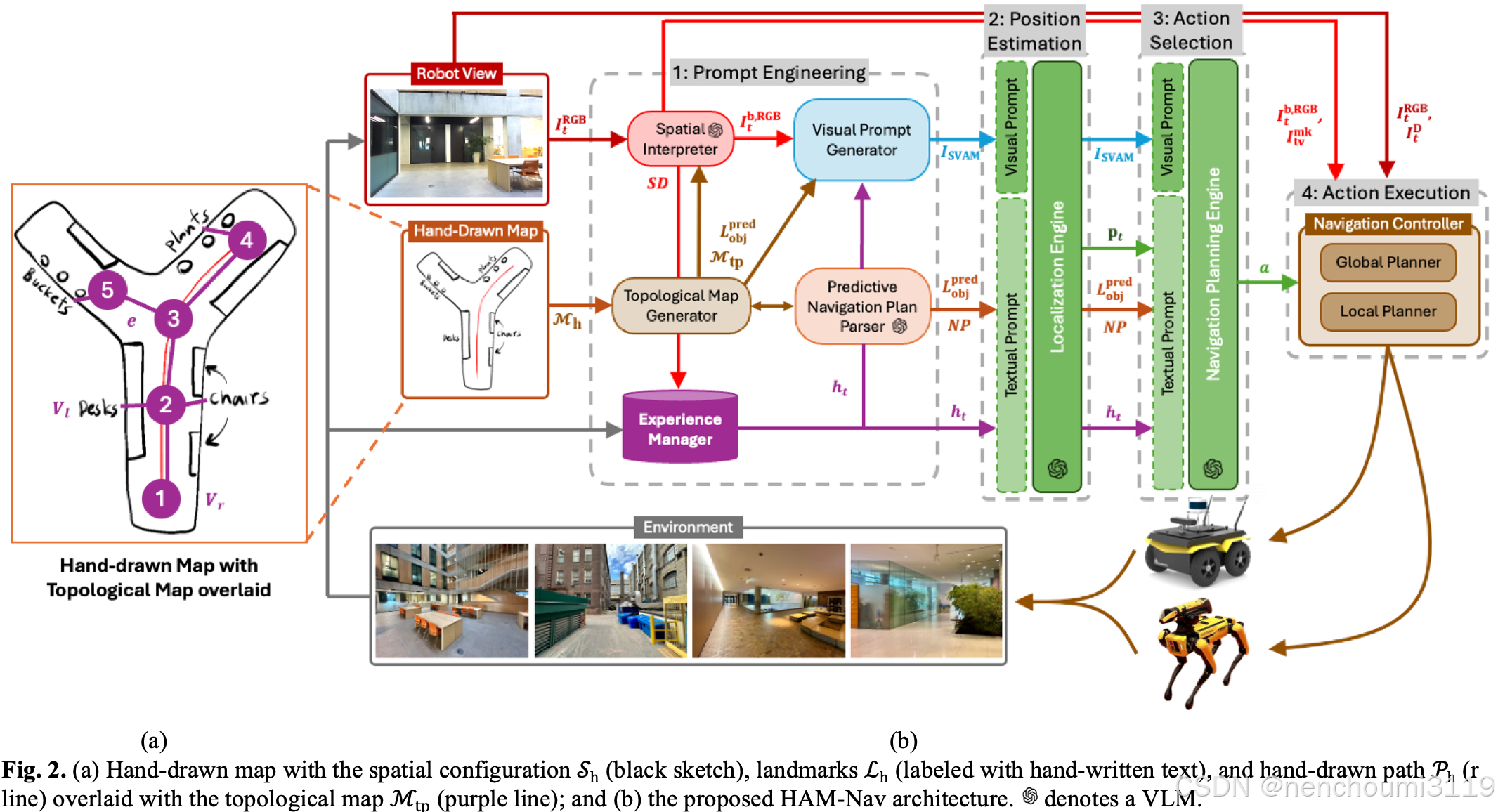
上图中(a)部分包含了以下几个信息:
- 空间关系 S h S_{h} Sh:表示机器人所处环境的边界与空间布局;
- 地标 L h = ( L h c , L h l ) L_{h}=(L_{h}^{c}, L_{h}^{l}) Lh=(Lhc,Lhl):描述地标类别的文本 L h c L_{h}^{c} Lhc 和 该地标在 M h M_{h} Mh 中的像素坐标 L h l L_{h}^{l} Lhl;
- 路径 P h P_{h} Ph:包含了机器人起始位置 p 0 = ( x 0 , y 0 ) p_{0}=(x_{0},y_{0}) p0=(x0,y0)、机器人期望的最终位置 p d = ( x d , y d ) p_{d}=(x_{d},y_{d}) pd=(xd,yd);
环境的真实布局用占据栅格地图 M e = ( S e , L e ) M_{e}=(S_{e},L_{e}) Me=(Se,Le) 表示,其由两部分构成:
- 空间关系 S e S_{e} Se ;
- 地标 L e = ( L e c , L e l ) L_{e}=(L_{e}^{c}, L_{e}^{l}) Le=(Lec,Lel):其中 L e c L_{e}^{c} Lec 用来描述地标的文本、 L e l L_{e}^{l} Lel 用来描述地标的位置;
由于人们对环境的记忆可能会引入地标位置、距离和比例方面的错误,所以 M h M_{h} Mh 与 M e M_{e} Me 可能会大相径庭。可能在 M h M_{h} Mh 中错放或遗漏地标,导致 L h L_{h} Lh 相对于 L e L_{e} Le 而言是不完整的。
机器人机载RGB-D相机
C
(
t
)
C(t)
C(t) 获得其周身的RGB图像
I
t
R
G
B
I_{t}^{RGB}
ItRGB 与深度
I
t
D
I_{t}^{D}
ItD。那么显然目标是在给定的
M
h
M_{h}
Mh 和
P
h
P_{h}
Ph 的前提下,机器人必须在
M
h
M_{h}
Mh 上完成自身定位,基于从相机
C
(
t
)
C(t)
C(t)获得的实时观测值
(
I
t
R
G
B
,
I
t
D
)
(I_{t}^{RGB},I_{t}^{D})
(ItRGB,ItD) 生成一系列的动作
a
(
t
)
a(t)
a(t) 导航至
p
d
p_{d}
pd。动作序列
a
(
t
)
a(t)
a(t)可以被表示为机器人的动作函数:
a
(
t
)
=
f
(
M
h
,
P
h
,
C
(
t
)
)
s
.
t
.
p
(
T
)
=
p
d
a(t)=f\left(M_{h},P_{h},C(t)\right) s.t. p(T)=p_{d}
a(t)=f(Mh,Ph,C(t))s.t.p(T)=pd
目标是在中止时间步长
T
T
T 时机器人能够导航至终点
p
d
p_{d}
pd。
Hand-Drawn Map Navigation Architecture
作者提出的手绘地图HAM-Nav框架如图2(b)所示:
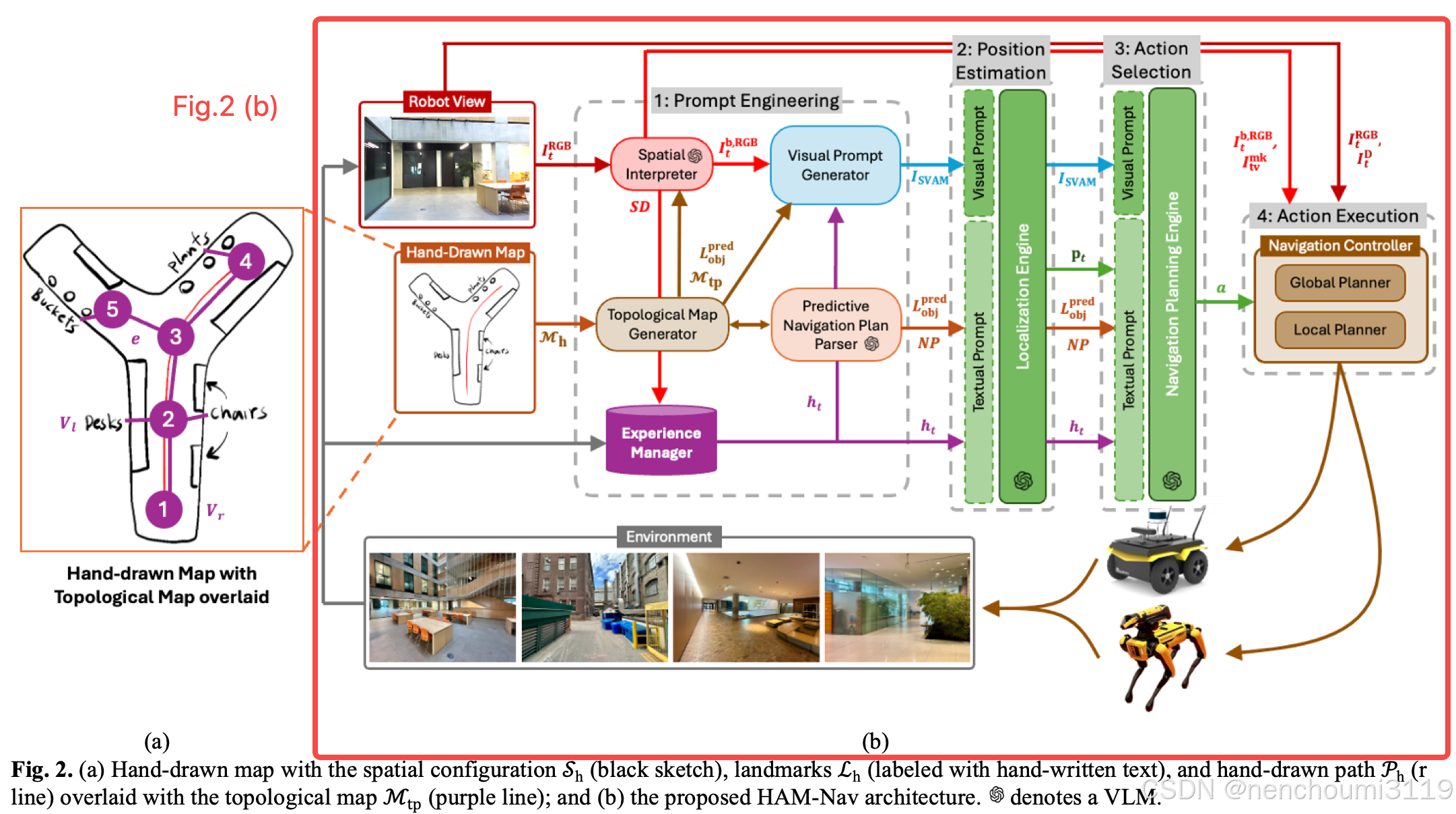
由以下四个阶段组成:
- 阶段一:提示工程(Prompt Engineering)包括 拓扑地图生成器(Topological Map Generator,TMG)、空间解释器(Spatial Interpreter,SI)、视觉提示生成器(Visual Prompt Generator,VPG)、预测性导航计划解析器(Predictive Navigation Plan Parser,PNPP)和 经验管理器(Experience Manager,EM),用于从 M h M_{h} Mh 中提取导航和环境特征,以生成视觉-文本提示词;
- 阶段二:位置估计(Position Estimation)使用定位引擎(Localization Engine,LE)基于阶段一中生成的视觉-文本提示词来估计机器人位置在 M h M_{h} Mh中的位置 p t p_{t} pt;
- 阶段三:动作选择(Action Selection)包括导航规划引擎(Navigation Planning Engine,NPE),使用基于位置 p t p_{t} pt 规划出与机器人形态无关的离散导航动作;
- 阶段四:动作执行(Action Execution)使用导航控制器(Navigation Controller,NC)将阶段三得到的导航动作转换为在环境中执行的机器人速度。
A. Topological Map Generator (TMG)
TMG基于 M h M_{h} Mh 创建一个用于机器人定位与导航的拓扑地图 M t p M_{tp} Mtp。具体而言,首先将 M h M_{h} Mh 离散化成一个由单元格 g i g_{i} gi 构成的占据栅格地图的 M g M_{g} Mg。拓扑地图 M t p = ( V , E ) M_{tp}=(V,E) Mtp=(V,E) 中 V = V r ∪ V l V=V_{r}\cup V_{l} V=Vr∪Vl 表示由机器人位置点 V r V_{r} Vr 、地标点 V t V_{t} Vt 、以及链接他们的边 E E E 构成的集合,如 Fig2. (a) 所示:
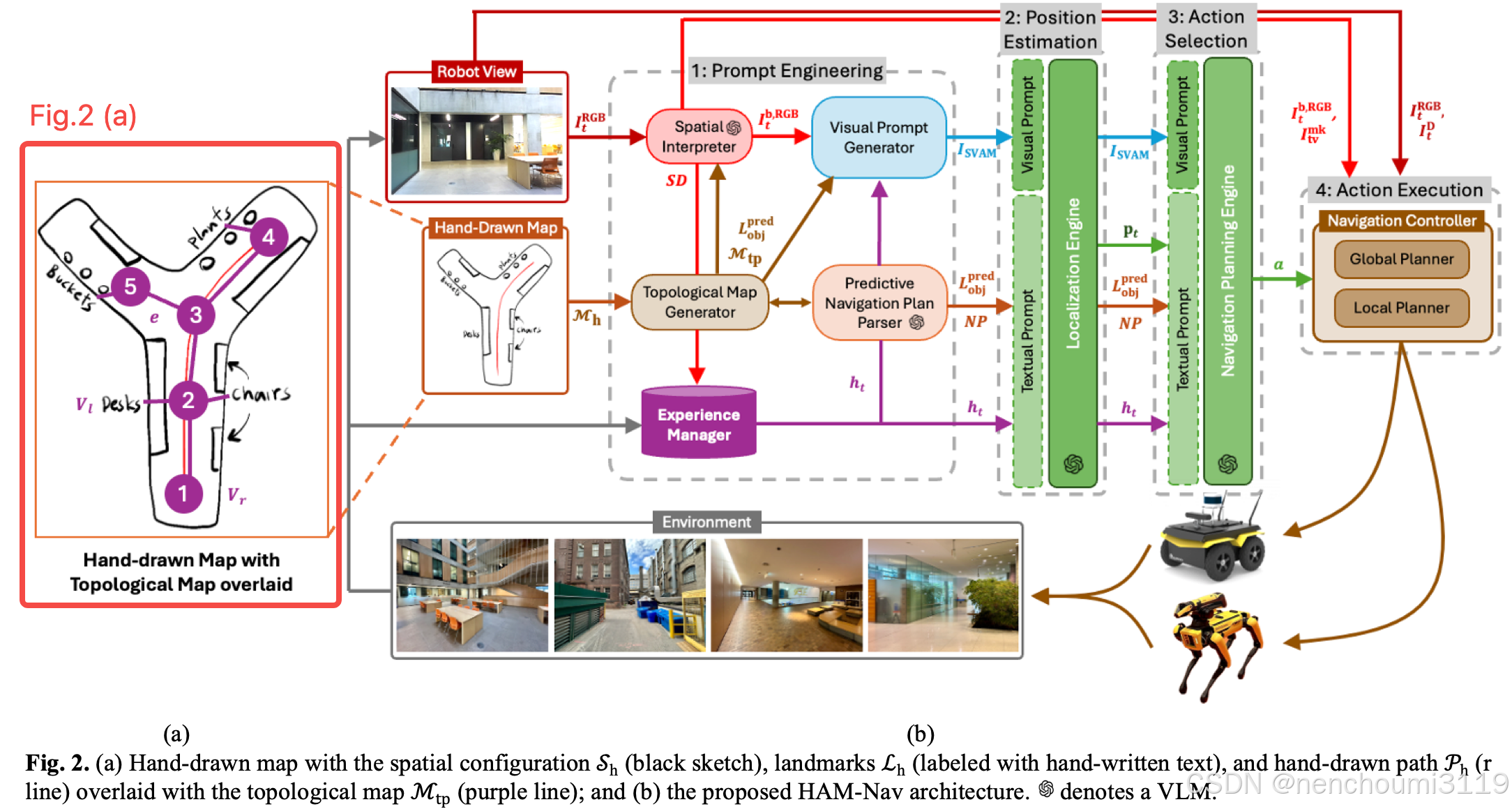
- V r V_{r} Vr 通过 M g M_{g} Mg 中空闲栅格集合中使用 K-Means 聚类获得的,用来表示不同的空闲空间簇,每一个簇对应一个潜在的机器人位置;
- 使用Google Vision API生成 V l V_{l} Vl 以来标识地图 M h M_{h} Mh 中的 L h c L_{h}^{c} Lhc 和 L h l L_{h}^{l} Lhl ;
- 边 e ∈ E e\in E e∈E 用来连接 V r V_{r} Vr 和 V l V_{l} Vl;
- M t p M_{tp} Mtp 提供给以下三个组件: S I SI SI 进行地标检测、 V P G VPG VPG 进行视觉提示词生成、 P N P P PNPP PNPP 进行路径规划;
B. Spatial Interpreter (SI)
对于每个 t t t 时刻包含以下两个信息:
- 被标记的图像 I t b , R G B I_{t}^{b,RGB} Itb,RGB 包含了每个对象的 bounding box 以及对应的标签;
- S D SD SD 表示对图像 I t R G B I_{t}^{RGB} ItRGB 的文本描述;
对于图像 I t R G B I_{t}^{RGB} ItRGB 而言包含两种类型的地标:
- 物品地标 L o b j L_{obj} Lobj:描述真实物理对象如家具、汽车等;
- 结构地标 L s t r L_{str} Lstr:描述地图中结构性信息,如交叉路口等;
其中
L
o
b
j
L_{obj}
Lobj 使用 Grounding DINO 开放词汇检测器获得;
L
s
t
r
L_{str}
Lstr 使用 Fig. 3 中 Stage3 自定义的结构获得:
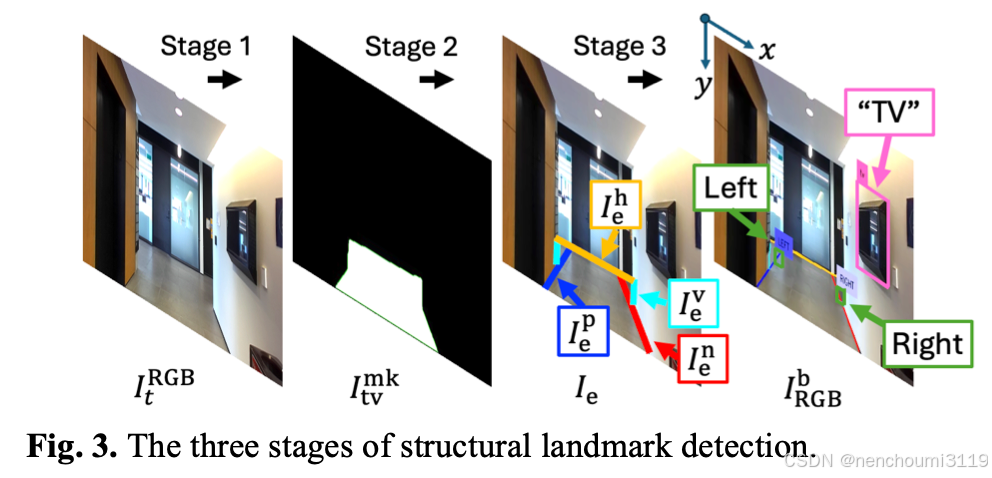
首先,Grounded-Segment Anything Model(G-SAM)模型将图像 I t R G B I_{t}^{RGB} ItRGB 用像素级的mask I t m k I_{t}^{mk} Itmk 对区域进行分割。在上图中的 Stage 2 ,边信息从 I t v m k I_{tv}^{mk} Itvmk 中抽取并使用霍夫变化(Hough Transform)生成 I e I_{e} Ie。基于图像 I e I_{e} Ie 中的线段长度和朝向将其分为四大类:水平线段 I e h I_{e}^{h} Ieh、垂直线段 l e v l_{e}^{v} lev、正斜线 l e p l_{e}^{p} lep、负斜线 l e n l_{e}^{n} len。
然后,在上图中的 Stage 3,通过使用决策函数 f S L ( I e ) f_{SL}(I_{e}) fSL(Ie) 基于上面的 I e h I_{e}^{h} Ieh、 l e v l_{e}^{v} lev、 l e p l_{e}^{p} lep、 l e n l_{e}^{n} len 几何关系来计算 L s t r L_{str} Lstr:
f S L ( I e ) = I I { L e f t i f d ( I e h ∩ v , I e v ∩ p , I e p ∩ h ) ≤ r R i g h t i f d ( I e h ∩ v , I e v ∩ n , I e n ∩ h ) ≤ r f_{SL}(I_{e})=II \begin{cases} Left\quad if\quad d(I_{e}^{h\cap v},I_{e}^{v\cap p}, I_{e}^{p\cap h})\leq r \\ Right\quad if \quad d(I_{e}^{h\cap v},I_{e}^{v\cap n}, I_{e}^{n\cap h})\leq r \end{cases} fSL(Ie)=II{Leftifd(Ieh∩v,Iev∩p,Iep∩h)≤rRightifd(Ieh∩v,Iev∩n,Ien∩h)≤r
其中 d d d 表示每个类型的边交叉点之间的欧式距离; I I II II 是一个 Bool 函数仅输出一个互斥值“左转”或“右转”;图 I t b , R G B I_{t}^{b,RGB} Itb,RGB 中包含了 L o b j L_{obj} Lobj 和 L s t r L_{str} Lstr 的bounding box。每个地标的bounding box坐标用 L c d L_{cd} Lcd 表示;
对于每个时刻
t
t
t 图像
I
t
R
G
B
I_{t}^{RGB}
ItRGB 的文本描述
S
D
SD
SD 用LLM获得,这个过程包含了视觉
σ
v
i
s
(
I
t
R
G
B
)
\sigma_{vis}(I^{RGB}_{t})
σvis(ItRGB) 与文本
σ
t
e
x
t
(
L
d
i
c
t
)
\sigma_{text}(L_{dict})
σtext(Ldict) 提示词。其中
L
d
i
c
t
L_{dict}
Ldict 用来描述图像
I
t
R
G
B
I_{t}^{RGB}
ItRGB 中机器人感知到的地标相对位置(前、左、右,因为看不到后面)。为了获取这个信息,作者首先将图像
I
t
R
G
B
I_{t}^{RGB}
ItRGB 按竖直方向分割成三个等宽的象限:左象限
Q
l
Q_{l}
Ql、前象限
Q
f
Q_{f}
Qf、又象限
Q
r
Q_{r}
Qr。每一个地标都会根据其bounding box中心点像素坐标系在x方向上的值
L
c
d
i
L_{cd}^{i}
Lcdi 分配到其中一个象限中。地标象限的集合构成一个字典
L
d
i
c
t
=
{
L
o
b
j
:
Q
}
L_{dict}=\{L_{obj}:Q\}
Ldict={Lobj:Q}。地标的提示词按照 <L_{obj}> on your <Q> 的格式传递给VLM模型用来生成对图像
I
t
R
G
B
I_{t}^{RGB}
ItRGB 最终的详细描述
S
D
SD
SD:
S
D
=
V
L
M
(
σ
v
i
s
(
I
t
R
G
B
,
σ
t
e
x
t
(
L
d
i
c
t
)
)
)
SD=VLM\left(\sigma_{vis}(I^{RGB}_{t}, \sigma_{text}(L_{dict}))\right)
SD=VLM(σvis(ItRGB,σtext(Ldict)))
图像 I t R G B I_{t}^{RGB} ItRGB 分别传递给 V P G VPG VPG 模块用来生成视觉提示词、NC模块生成导航,而 S D SD SD 给 E M EM EM 模块用于检索与导航相关的经验;
C. Experience Manager (EM)
EM模块使用 Retrieval Augmented Generation (RAG) 用来收集并回溯过去导航经验以提供历史的导航上下文信息。完整的导航历史信息存储在机器人本地并用 H H H 表示,每一条经验 h t h_{t} ht 都代表在 t t t 时刻的导航数据,包含先前的观测值 S D t ′ SD^{'}_{t} SDt′、估计的机器人位置 p t ′ p^{'}_{t} pt′、实际执行的动作 a t ′ a^{'}_{t} at′。使用当前观测值 E c E_{c} Ec 与过去观测值 E p E_{p} Ep 嵌入的余弦相似度大小从 H H H 找到相关性最大的 h t h_{t} ht。与 h t h_{t} ht 余弦相似度最高的得分将被用于 L E LE LE 模块提示词估计机器人位置、 N P E NPE NPE 模块提示词规划导航。
D. Visual Prompt Generator (VPG)
作者开发了
V
P
G
VPG
VPG 模块如 Fig. 4 所示,通过生成视觉提示
I
S
V
A
M
I_{SVAM}
ISVAM 来实现选择性视觉关联提示,表示 $I_{t}^{RGB} $ 中的特征与
M
h
M_{h}
Mh 之间的关系:
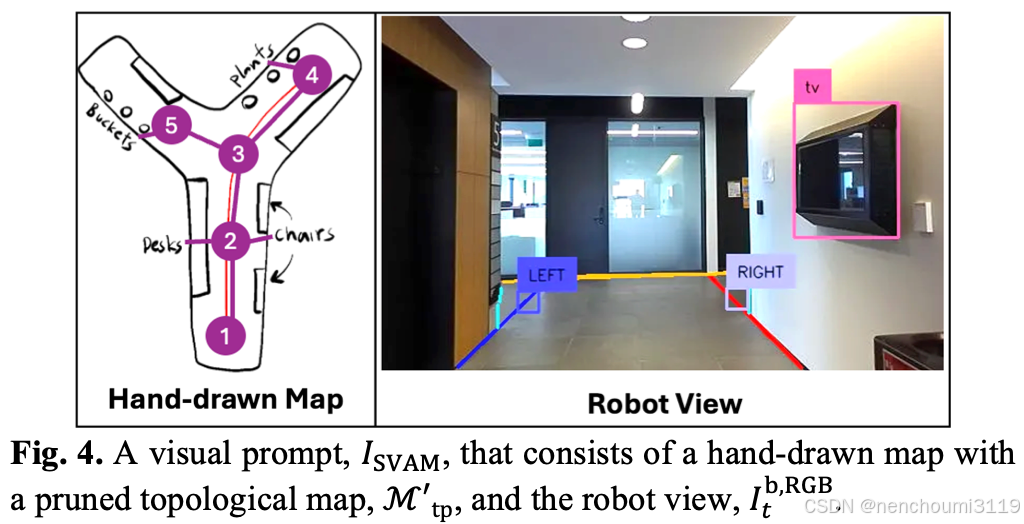
I
S
V
A
M
I_{SVAM}
ISVAM 由一个 RGB 图像 + 两个并列的元素
I
t
R
G
B
I_{t}^{RGB}
ItRGB、基于
M
h
M_{h}
Mh 的剪枝拓扑图
M
t
p
′
M^{'}_{tp}
Mtp′ 构成。
M
t
p
′
M^{'}_{tp}
Mtp′ 只包含机器人在环境中最有可能所在的候选节点位置,这个剪枝策略中的最低保留函数
ζ
(
v
i
)
,
v
i
∈
V
r
\zeta(v_{i}), v_{i}\in V_{r}
ζ(vi),vi∈Vr 表示如下;
ζ
(
v
i
)
=
1
1
+
e
α
⋅
(
d
(
v
i
,
p
′
)
−
β
)
+
γ
⋅
δ
(
v
i
,
p
′
,
a
′
)
\zeta(v_{i})=\frac{1}{1+e^{\alpha\cdot(d(v_{i},p^{'})-\beta)+\gamma\cdot\delta(v_{i},p^{'},a^{'})}}
ζ(vi)=1+eα⋅(d(vi,p′)−β)+γ⋅δ(vi,p′,a′)1
其中 α \alpha α 是基于 d ( v i , p ′ ) d(v_{i},p^{'}) d(vi,p′) 的权重因子; β \beta β 是表示距离敏感度的参数;状态转移方程 δ ( v i , p ′ , a ′ ) \delta(v_{i},p^{'},a^{'}) δ(vi,p′,a′) 表示机器人到达节点 v i v_{i} vi 后执行的动作 a ′ a^{'} a′; γ \gamma γ 是基于 δ \delta δ 的权重因子。拓扑图 M t p ′ M^{'}_{tp} Mtp′ 仅包含 ζ ( v i ) > 0.5 \zeta(v_{i})>0.5 ζ(vi)>0.5 的节点。作者在这里设置 β = 2 , α = 0.5 , γ = 0.5 \beta=2, \alpha=0.5, \gamma=0.5 β=2,α=0.5,γ=0.5 作为超参数,这三个值都是通过专家经验调出来的,以修剪代表机器人位置可能性较低的节点。 I S V A M I_{SVAM} ISVAM 分别被 L M LM LM和 N P E NPE NPE模块用于评估机器人位置和动作选择。
E. Predictive Navigation Plan Parser (PNPP)
作者在这里独创了一个
P
N
P
P
PNPP
PNPP 用来提供地标预测
L
o
b
j
p
r
e
d
L_{obj}^{pred}
Lobjpred 和导航规划的文本描述
N
P
NP
NP。
P
N
P
P
PNPP
PNPP 使用VLM来进行地标删除。传递给LLM的包含一个约束在
M
h
M_{h}
Mh 内的视觉提示词
σ
v
i
s
(
M
h
)
\sigma_{vis}(M_{h})
σvis(Mh) 和一个约束在
M
t
p
M_{tp}
Mtp 内的文本提示词
σ
t
e
x
t
(
V
)
\sigma_{text}(V)
σtext(V)。VLM使用这些信息基于空间相关性与最紧邻地标来推断潜在的关联地标,对于节点
v
i
∈
V
v_{i}\in V
vi∈V 地标预测如下:
L
o
b
j
p
r
e
d
=
V
L
M
(
σ
v
i
s
(
M
h
)
,
σ
t
e
x
t
(
V
)
)
L_{obj}^{pred}=VLM(\sigma_{vis}(M_{h}),\sigma_{text}(V))
Lobjpred=VLM(σvis(Mh),σtext(V))
对于每个 v i v_{i} vi 而言 L o b j p r e d L_{obj}^{pred} Lobjpred 都包含在 M t p M_{tp} Mtp 中被 S I SI SI 模块用来进行地标检测。
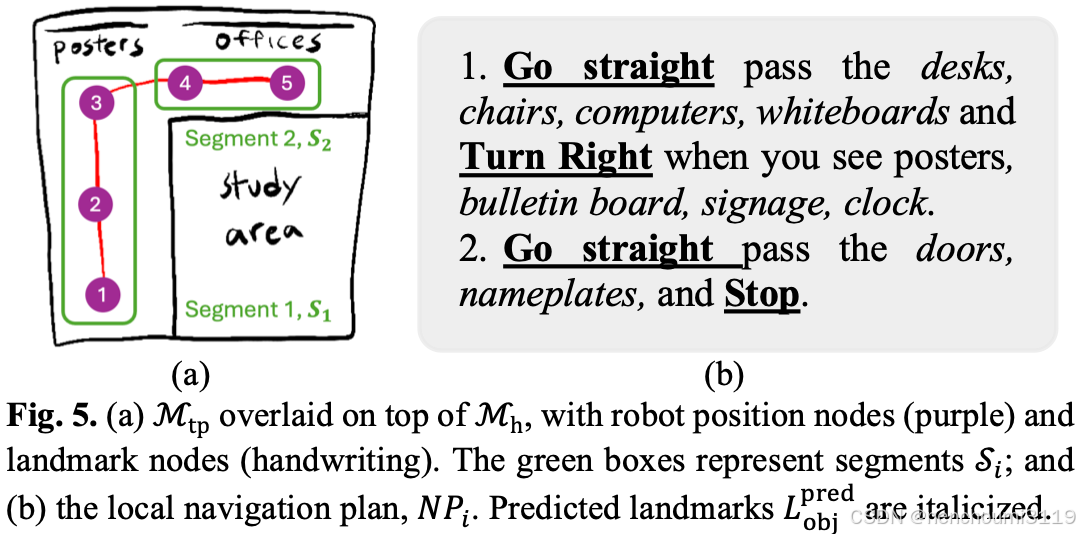
为了生成
N
P
NP
NP,
M
t
p
M_{tp}
Mtp 按照 Fig.5 (a) 所示的方式根据邻接点
V
j
u
n
c
⊆
V
V_{junc}\subseteq V
Vjunc⊆V 分割成局部的片段
S
i
S_{i}
Si。对于每个片段
S
i
S_{i}
Si 都关联着从
M
t
p
M_{tp}
Mtp 中获得的
L
s
t
r
,
L
o
b
j
,
L
o
b
j
p
r
e
d
L_{str}, L_{obj}, L_{obj}^{pred}
Lstr,Lobj,Lobjpred。用下面的函数生成一条针
S
i
S_{i}
Si 的可读描述:
N
P
i
=
f
n
p
(
S
i
,
L
s
t
r
,
L
o
b
j
,
L
o
b
j
p
r
e
d
)
NP_{i}=f_{np}\left(S_{i}, L_{str}, L_{obj}, L_{obj}^{pred}\right)
NPi=fnp(Si,Lstr,Lobj,Lobjpred)
f
n
p
f_{np}
fnp 函数如 Fig.5 (b) 所示将每个
S
i
S_{i}
Si 和其地标
(
L
s
t
r
,
L
o
b
j
,
L
o
b
j
p
r
e
d
)
(L_{str}, L_{obj}, L_{obj}^{pred})
(Lstr,Lobj,Lobjpred) 按照固定格式 <navigation action> pass the <landmarks>, and <navigation action> when you see <landmarks> 映射成局部导航规划
N
P
i
NP_{i}
NPi。所有的局部导航规划
{
N
P
i
}
\{NP_{i}\}
{NPi} 都按照全局规划
N
P
NP
NP 的格式以文本提示词的方式由
L
E
LE
LE 和
N
P
R
NPR
NPR 模块生成;
F. Localization Engine (LE)
L E LE LE 模块通过从 M t p ′ M_{tp}^{'} Mtp′ 中选择机器人坐标节点 v i v_{i} vi 使用VLM来评估机器人当前位置 p t p_{t} pt。VLM的输入包含了视觉提示词 σ v i s ( I S V A M ) \sigma_{vis}(I_{SVAM}) σvis(ISVAM) 和文本提示词 σ t e x t ( S D ′ , p ′ , a ′ , N P ) \sigma_{text}(SD^{'}, p^{'},a^{'},NP) σtext(SD′,p′,a′,NP)。作者使用了两个提示词技巧来提升位置估计 p t p_{t} pt 的效果:
- CoT :将机器人位置估计任务分解为更小的显式步骤,通过要求VLM执行逐步推理来实现的,首先识别视觉地标,然后在生成 p p p 之前将这些视觉地标与手绘地图相关联;
- 基于分数的提示(SB):通过要求VLM明确生成机器人位置估计概率,该过程表示如下:
p t = V L M ( σ v i s ( I S V A M , σ t e x t ( S D ′ , p ′ , a C o T , S B ′ ) ) ) p_{t}=VLM\left(\sigma_{vis}(I_{SVAM},\sigma_{text}(SD^{'},p^{'},a^{'}_{CoT,SB}))\right) pt=VLM(σvis(ISVAM,σtext(SD′,p′,aCoT,SB′)))
估计得到的位置 p t p_{t} pt 被 N P E NPE NPE 模块用与机器人导航动作选择。
G. Navigation Planning Engine (NPE)
N
P
E
NPE
NPE 的目标是使用VLM生成高层次的动作命令,如“move forward”、“turn right”、“turn left”、“stop”。
N
P
E
NPE
NPE 模块同
L
E
LE
LE 一样使用
σ
v
i
s
(
I
S
V
A
M
)
\sigma_{vis}(I_{SVAM})
σvis(ISVAM) 和
σ
t
e
x
t
(
S
D
′
,
p
′
,
a
′
,
N
P
,
p
t
)
\sigma_{text}(SD^{'},p^{'},a^{'},NP,p_{t})
σtext(SD′,p′,a′,NP,pt) 以 zero-shot 的方式生成导航决策。CoT和SB提示工程被用于引导推理过程。其中CoT将导航任务分解成“首先理解
M
h
M_{h}
Mh 中的
p
t
p_{t}
pt,然后再将
p
t
p_{t}
pt 和
N
P
NP
NP关联起来”。CoT用于使推理过程清晰有序,而SB用于为每个可能的动作分配概率分数,表示动作成功完成导航计划的可能性。然后选择概率得分最高的动作
a
a
a ,并将其传递给
N
C
NC
NC 模块执行。动作选择过程如下:
a
=
V
L
M
(
σ
v
i
s
(
I
S
V
A
M
)
,
σ
t
e
x
t
(
S
D
′
,
p
′
,
a
′
,
N
P
,
p
t
)
C
o
T
,
S
B
)
a=VLM\left(\sigma_{vis}(I_{SVAM}),\sigma_{text}(SD^{'},p^{'},a^{'},NP,p_{t})_{CoT,SB}\right)
a=VLM(σvis(ISVAM),σtext(SD′,p′,a′,NP,pt)CoT,SB)
H. Navigation Controller (NC)
N C NC NC 模块将动作 a a a 转换成机器人实际制订的速度指令 ( v , w ) (v,w) (v,w),通过使用 I t R G B , I t D , L c d , I t v m k I^{RGB}_{t},I^{D}_{t},L_{cd},I^{mk}_{tv} ItRGB,ItD,Lcd,Itvmk信息分三个阶段获得:
- 在第一阶段:图像 I t v m k I^{mk}_{tv} Itvmk 质心的像素关联 ( h c e n t , w c e n t ) (h_{cent},w_{cent}) (hcent,wcent) 被用于 “move forward”命令。对于 “trun left” 和 ”turn right“命令由 L s t r L_{str} Lstr从 L c d L_{cd} Lcd中获取 ( h L , w L ) (h_{L},w_{L}) (hL,wL);
- 在第二阶段:使用相机模块将2D图像坐标 ζ = ( h , w ) \zeta=(h,w) ζ=(h,w) 投射到 3D 世界坐标上 ( x , y , z ) (x,y,z) (x,y,z) ;
- 在第三阶段:全局路径规划器 Φ g l o b a l \Phi_{global} Φglobal 用来生成一系列导航点 p w p_{w} pw,局部路径规划器 Φ l o c a l \Phi_{local} Φlocal 将这些导航点 p w p_{w} pw 转换成线速度与角速度 ( v , w ) (v,w) (v,w) 同时实现静态避障功能;
Experiments
作者进行了两组实验来评估我们新型HAM-Nav架构的性能:
- 消融实验:评估HAM-Nav每个模块的贡献;
- 用户调用,以调查HAM-Nav在现实环境中的可行性和可用性;
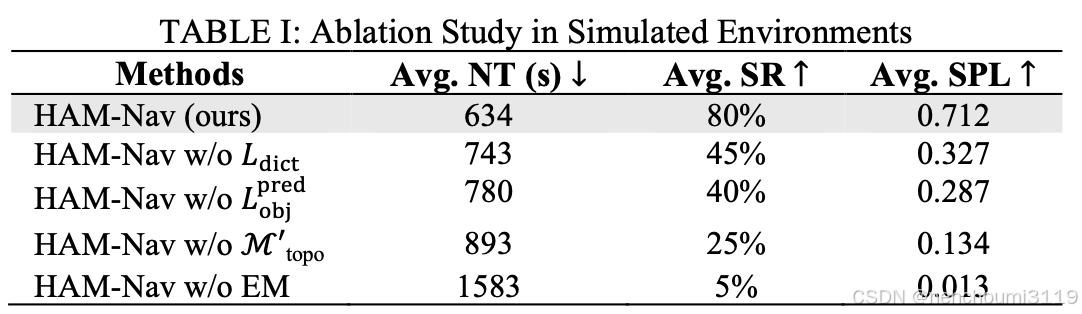
A. Ablation Study in Simulated Environments
使用三个指标来研究导航性能:
- 导航时间(NT):度量到达目标位置 p d p_{d} pd 所消耗的时间(以秒为单位);
- 按路径长度加权成功率(SPL):评估机器人的导航路径与人类手绘路径;
- 成功率(SR):表示成功试验的比例;
1. Simulated Environments
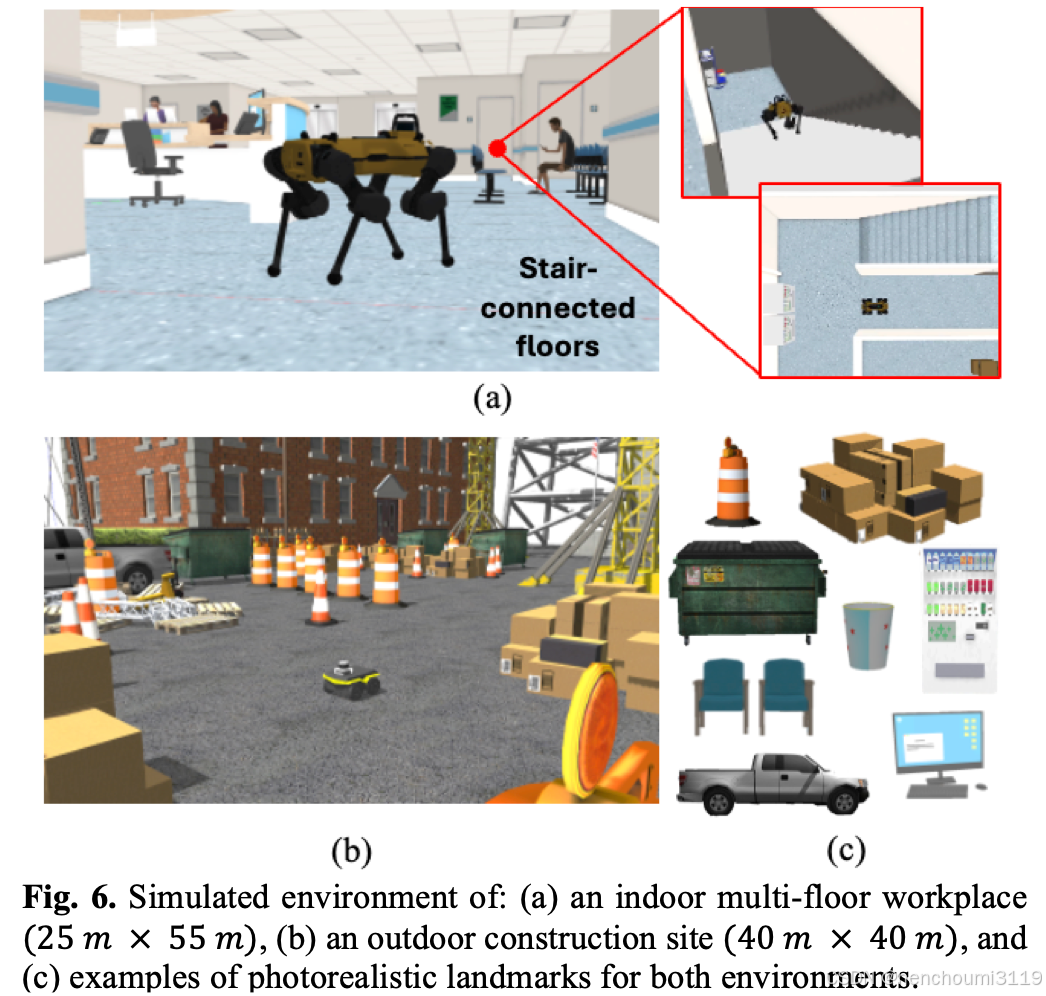
在Gazebo模拟器中生成了两个3D逼真的环境,如 Fig. 6所示。
- 第一个环境是一个结构化的室内多层工作场所,其特点是直线墙和楼梯连接的地板;
- 第二个环境是一个非结构化的室外建筑工地,由随机放置的地标形成不规则的导航路径。
这些环境中的地标包括塔架、箱子、垃圾箱、椅子和电脑。
2. Mobile Robots
使用带有差动驱动系统的Clearpath Jackal轮式机器人和Boston Dynamic Spot四足机器人。这两个机器人都有一个机载RGB-D传感器。
- 对于
Jackal机器人,使用了A*算法全局规划器[37]和定时弹性带规划器(TEB)局部规划器; - 对于
Spot机器人,使用了基于快速探索随机树的全局规划器(RRT)和非线性模型预测控制器(NMPC)局部规划器。
使用GPT-4o作为VLM。
3. Ablation Study Methods
对比了 HAM-Nav 以下几个消融实验:
- 没有 L d i c t L_{dict} Ldict 在 S D SD SD 中提供地标位置;
- 没有 L o b j p r e d L_{obj}^{pred} Lobjpred 来预测地标;
- 没有 M t o p ′ M_{top}^{'} Mtop′ 对拓扑图进行修剪;
- 没有 E M EM EM 确定历史导航信息的重要性;
4. Procedure
对于每种环境,为每个机器人平台创建了两个不同的手绘地图,其中包含两个随机的起始位置和目标位置。对所有消融方法中的每张手绘图进行了五次试验。为了计算SPL, p h p_{h} ph 转换为度量图中的等效路径以代替最佳路径。并定义达到预期位置的测试为成功case。
5. Results
HAM-Nav及其变体的平均NT、SR和SPL如 Table 1 所示。与所有消融方法相比,完整的HAM-Nav架构在不同的模拟环境中具有更高的整体性能:HAM-Nav的NT最低(634s),SR最高(80%),SPL最高(0.712)。
B. User Study in Real-World Environments
作者进行了一项用户调研,以评估HAM Nav在现实环境中的可行性和可用性。使用了SR和SPL性能指标以及两个标准化指标评估了HAM Nav的感知可用性:
- 5-point Likert 系统可用性量表(SUS)以提供整体易用性评分;
- Net Promoter Score(NPS)以衡量用户根据自己的经验推荐HAM Navs的可能性。
1. Real-World Environments
在多伦多大学校园使用了两个结构化的室内和一个非结构化的室外环境,如 Fig.7 所示:
- Myhal工程中心大楼(MH);
- Sandford Fleming大楼(SF);
- Industrial Alley(IA);

2. Mobile Robot
部署了一个带ZED Mini立体摄像头的豺狼轮式机器人。A*算法和TEB规划器分别用于全局和局部规划,使用GPT-4o作为VLM。
3. Procedure
共计10名22-42岁的工科学生参加了这项研究。每位参与者对每个实验环境进行了5分钟的参观以记忆空间布局。参观结束后,随机选择了两个机器人启动和目标位置。参与者有3分钟的时间使用iPad和Apple Pencil绘制环境和机器人的路径,以模拟时间受限的场景。机器人在每个环境中执行了两次试验,在完成所有环境试验后,每位参与者将SUS问卷的评分从1(强烈不同意)到5(强烈同意),并回答NPS问题从1(完全不可能)到10(极有可能),以推荐HAM-Nav。
4. Results
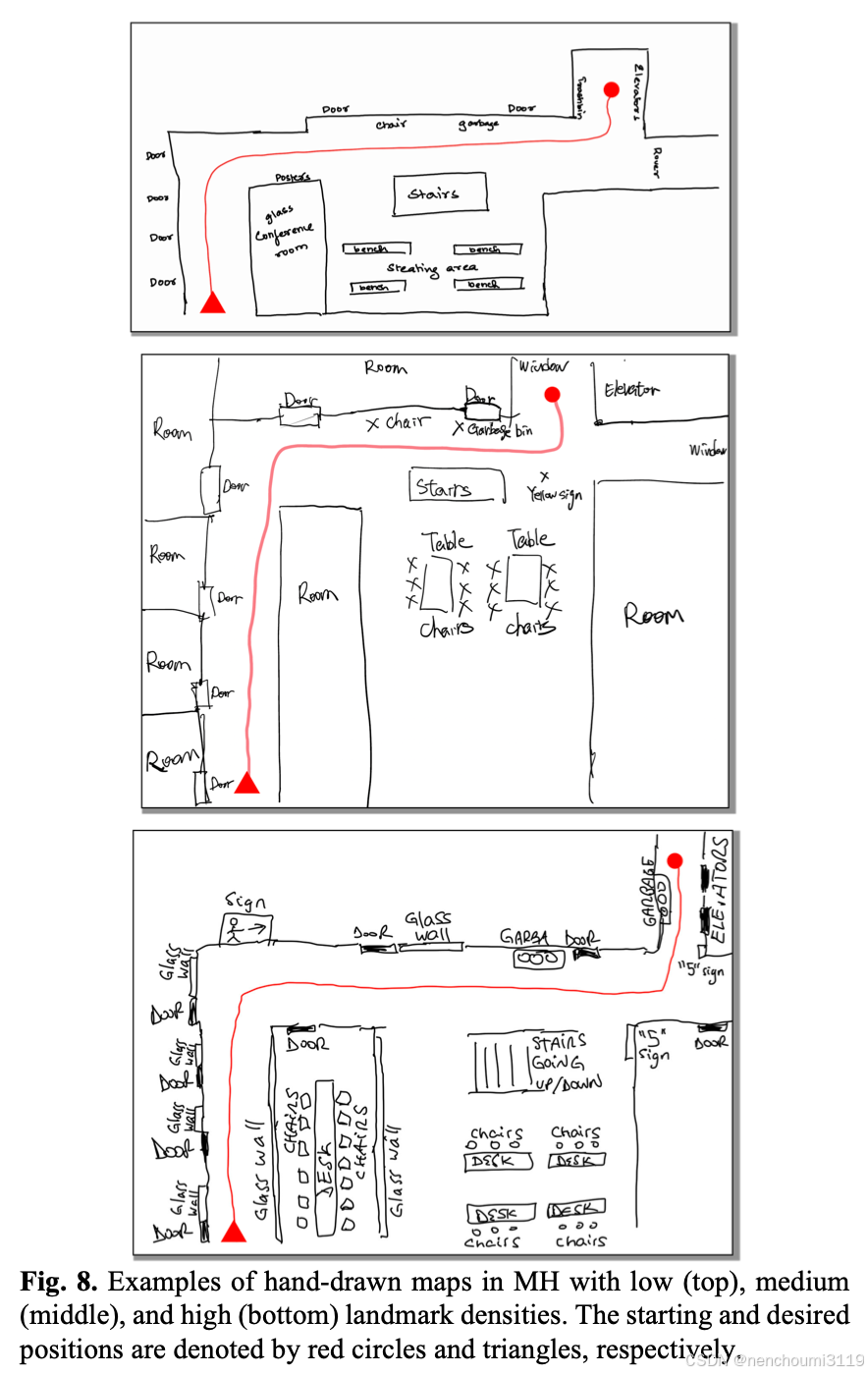
Table II 显示了该研究的SUS、NPS、SR和SPL评分。HAM-Nav的真实世界性能达到了78%的平均SR和0.714的SPL,这与第五章A节中的趋势相似。此外,HAM-Nav能够在不同地标密度的不同手绘风格中进行泛化,如图8所示,进一步证明了方法的稳健性。
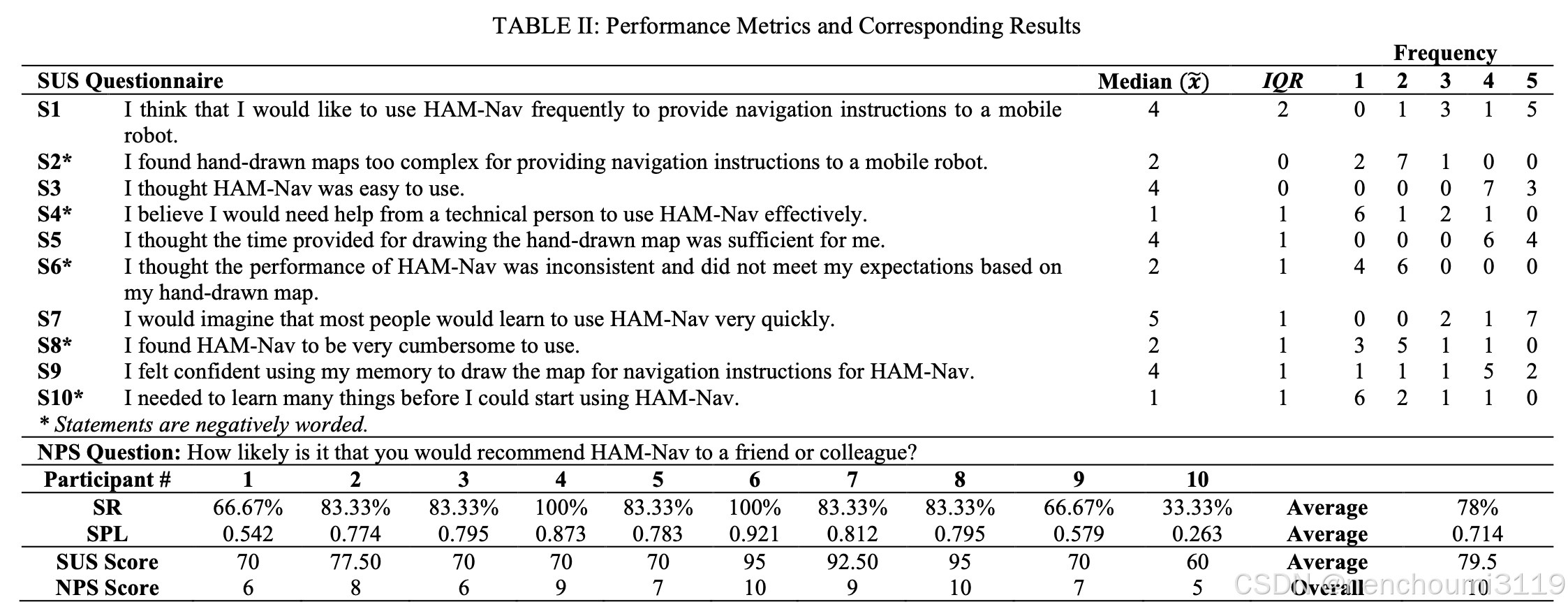
总体而言,HAM-Nav的平均SUS得分为79.5。该分数在形容词评分量表上被定义为“良好”和“优秀”之间。参与者对频繁使用HAM-Nav提供导航指令的强烈意愿进行了评分,他们表示HAM-Nav并不复杂也不麻烦。然而,有一位参与者认为他们需要专业的培训以使用这套系统。参与者认为,大多数人可以快速学会使用HAM-Nav,并且有信息认为他们记忆绘制地图是可用的。HAM-Nav的导航性能也达到了参与者的期望。
写在最后
这篇文章是有一定难度的:
- 首先是其任务本身的特殊性,即需要从一个高度抽象、关键信息缺失的手绘地图中提取关键信息映射到真实世界栅格地图上,这一步本身就非常有挑战;
- 其次是因为作者在文中定义了大量的名词,每次看到这些都需要向上翻页找到对应的解释,这对阅读起来不是很友好;
- 作者在文章使用了大量不必要的隐函数表示,如 V L M ( x x x ) VLM(xxx) VLM(xxx) 等,这其实就是把input输入给VLM,冗余函数的平铺很容易让人陷入理解函数的漩涡中,更加滞后了阅读的流畅性;
- 最后,作者全篇都在使用倒装,对于母语为中文的我们而言阅读起来确实又些吃力;
但总体来说还是非常有意思的一篇文章,主要是其与机器人的交互形式比较独特,有能力和兴趣的建议还是仔细阅读下;

















 3294
3294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









