











GPT-4o mini发布,轻量级大模型如何颠覆AI的未来?
引言
随着人工智能技术的飞速发展,大型AI模型的发布已成常态。然而,庞大的计算资源和存储空间限制了它们在广泛场景中的应用。为满足市场需求,轻量级大模型应运而生,凭借高效的性能和低资源消耗,逐渐成为市场的新宠。
如今,AI大模型竞争的焦点已从“做大做强”转向“做小做精”,超越GPT-4o不再是唯一成功标准。在市场竞争新阶段,如何打动用户不仅依赖技术实力展示,更需证明在性能相当下,模型更小巧、经济、具性价比。
苹果自去年以来积极探索适用于手机的端侧模型,而OpenAI,以惊人扩张而著称,最近也加入了这一领域。OpenAI推出了轻量级小参数模型GPT-4o mini,顺应市场趋势,试图通过经济高效的模型拓展更广阔的市场。
一、轻量级大模型的定义与特点
1.与传统大模型的区别
轻量级大模型(LLMs)结合了高性能和广泛的应用潜力,同时拥有更小的参数量、低资源消耗以及更高的性价比。相较于传统大模型,它们的主要区别在于:
参数规模与挑战:传统大模型参数繁多,从数百亿到数万亿不等,训练和运行需大量计算资源且成本高昂。轻量级大模型通过架构优化、模型蒸馏等技术,在大幅度减小参数量的同时,仍保持或接近大模型性能。
训练与推理成本大幅降低:轻量级大模型GPT-4o mini以数亿参数实现接近千亿参数模型的性能,训练和推理成本仅数个数量级。
部署与应用场景:传统大模型适用于数据中心与云端,以满足高性能计算需求。轻量级大模型则更适合在边缘设备、移动端等环境中部署,实现低延时和高隐私性的数据处理,如智能手机、物联网设备等终端设备上的本地运行。
创新与技术:轻量级大模型需更高效的数据治理、优化训练策略和先进模型架构。MiniCPM系列通过高效稀疏架构和知识密度优化,实现小模型高性能。
2. 主要特征
小参数模型更容易融入热门领域的技术探索和商业化策略。面壁智能的刘知远教授认为,2023年ChatGPT和GPT-4的推出表明大模型技术路线已经基本确定,接下来的重点是探索其科学机理,并极致地优化效率。通过“以小博大”的理念,挑战了超大参数模型的效率。
轻量级大模型的主要特征如下:
- 模型大小更小,训练速度更快;
- 模型精度更高,泛化能力更强;
- 模型更加灵活,可适应不同领域的需求。
快速响应:在处理速度和响应时间上更具优势,适合需要实时处理的应用场景。
适应性强:无论设备资源如何受限,如智能手机、物联网设备或嵌入式系统,都能流畅运行,广泛适应性令人印象深刻。
二、市场需求分析
随着生成式AI技术的迅猛发展,大模型领域正经历从“做大做强”到“小而精”的显著转变。市场需求的变化,促使了技术发展的新方向。GPT-4o Mini 的发布进一步突显了轻量级大模型在当前市场中的重要性。
生成式人工智能有广阔的发展前景,包括预训练语言模型、ChatGPT上下文学习和基于人类反馈的强化学习三个关键技术,以及ChatGPT对相关人工智能研究的影响。
1、企业需求
优化后的文章:成本效益:传统大模型高昂训练及部署成本。轻量级大模型降低计算与存储需求,助企业控制开支,提高投资回报率。
许多企业面临硬件资源限制,轻量级模型能够在有限的资源条件下提供高效性能,从而优化资源配置。轻量级模型是指在保持较高准确性的前提下,采用更少的数据和更简单的模型结构,从而减少计算量和存储空间。这样可以更好地满足企业在有限硬件资源下的业务需求。
2、用户需求
除了企业,个人用户和开发者对轻量级大模型的需求也在增加:
移动便捷:用户期待在移动设备上体验AI助手如语音识别和实时翻译。轻量级模型让智能手机等设备高效运行,满足您的需求。
"用户个性化需求的提升,驱动了轻量级模型的发展。这种高效的处理方式和定制化能力,让其能够提供更贴合用户心意的个性化服务。"
三、轻量级大模型的应用场景
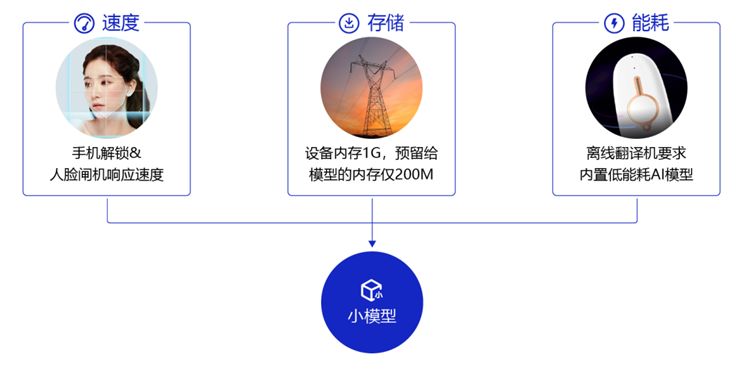
终端智能化:轻量级大模型驱动,智能手机、家居、车载等设备实现高效本地化AI处理,提升用户体验与数据隐私保护。

轻量级大模型正逐渐成为各领域的翘楚,展现出广泛的应用前景。随着技术的持续精进与创新,2024年将是这一趋势的关键之年,预示着轻量级大模型将在更多领域释放其巨大的潜力和应用价值。
四、轻量级大模型的技术实现
轻量级大模型的技术实现方法包括但不限于以下几种:SWIFT(Scalable lightWeight Infrastructure for Fine-Tuning)、PEFT(Parameter-Efficient Fine-Tuning)、LLI(Large Language Model for Information Extraction)等。这些方法旨在降低计算资源和存储需求,同时保持模型的性能 。
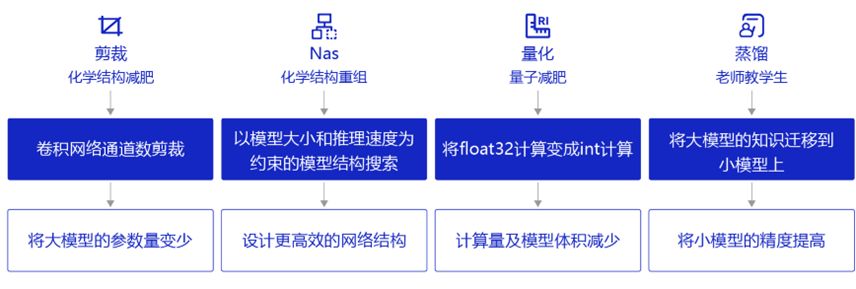
1、模型压缩
权重量化(Weight Quantization):通过使用较低位宽(如8位、4位)表示模型参数,大幅降低存储和计算成本。以二值化为例,权重压缩至+1或-1,实现极简存储需求。
权重剪枝是一种有效减少模型复杂度、计算量和存储需求的方法,通过移除冗余连接或神经元实现。尽管剪枝后可能需要重新训练以恢复性能,但它仍为优化模型提供了重要手段。
"简述模型蒸馏:一种方法,通过借鉴大型预训练模型的知识,训练出更小却保持高性能的模型。这个‘学徒’模型,通过模仿导师的行为来提升自身技能。"
2、轻量化网络结构
深度可分离卷积(Depthwise Separable Convolution)是一种将标准卷积分解为深度卷积和逐点卷积的技术,以减少计算量和参数数量。例如,MobileNet采用这种技术显著降低了计算复杂度。
深度可分离卷积是将一个完整的卷积运算分解为两步进行,即Depthwise卷积与Pointwise卷积。不同于常规卷积操作,Depthwise卷积的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。
同样是对于一幅128×128像素、三通道彩色输入图像(尺寸为128×128×3),Depthwise卷积首先经过第一次卷积运算,完全是在二维平面内进行。 卷积核的数量与上一层的通道数相同,即,通道和卷积核一一对应。 所以一个三通道的图像经过运算后生成了3个特征图。
分组卷积(Group Convolution)是一种将卷积操作分成多个组来减少计算量的技术,广泛应用于轻量化网络结构中,如ShuffleNet。
这种技术能够增加 filter之间的对角相关性,而且能够减少训练参数,不容易过拟合,这类似于正则的效果。
神经网络架构搜索(Neural Architecture Search, NAS)是一种自动化方法,旨在寻找最优的网络结构以降低计算复杂度和参数数量。借助NAS技术,我们能够设计出更具效率的网络结构。
3、硬件加速
优化后的文章:借助专用硬件(如NVIDIA Jetson和Google Coral TPU等),大幅提升模型推理速度,实现高效计算。这类硬件专为边缘设备设计,助力加速解决方案。
4、软件优化
优化推理引擎:借助诸如TensorFlow Lite和ONNX Runtime的高性能推理引擎,大幅提升端设备上的运行速度。这些引擎专为低功耗与资源受限环境量身打造。
提升计算效率的秘密武器:高性能计算库(如OpenBLAS、MKL-DNN),它们为数学运算带来卓越优化,助你轻松征服计算难题。
5、迁移学习和微调
"微调预训练,提速增效。大规模数据集上预训练的轻量级模型,迁移学习新趋势,让目标任务训练更迅速,性能更卓越。"
数据增强:通过数据增强技术扩充训练数据集,提高模型在小数据集上的泛化能力。
结论
轻量级大模型正成为AI发展新趋势,GPT-4o Mini发布展示其高效、低成本、易部署优势。技术进步与市场需求推动未来大模型朝更高效、轻量、亲民方向发展,为更多行业提供强大支持。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-

















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











