







前言
斯坦福大学研究人员近日推出了开源端侧大模型Octopus v2,引起了广泛关注。Octopus v2拥有20亿参数量,可以在智能手机、车载系统等终端设备上高效运行,在准确性和推理速度方面都超越了GPT-4。
-
Huggingface模型下载:https://huggingface.co/NexaAIDev/Octopus-v2
-
AI快站模型免费加速下载:https://aifasthub.com/models/NexaAIDev
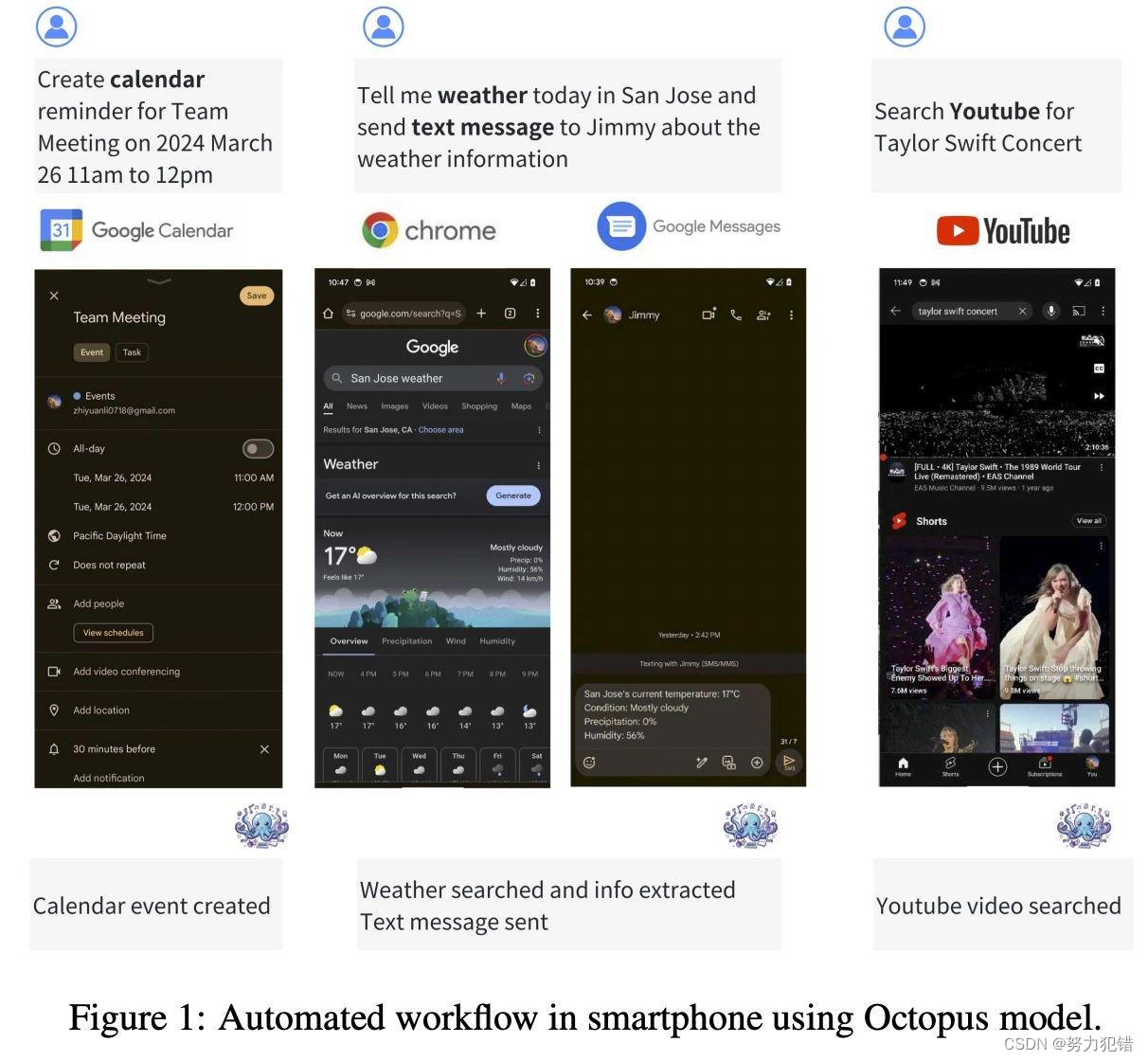
针对性设计与训练
Octopus v2针对自动化任务中的函数调用问题进行了优化设计。相比于传统的检索增强生成(RAG)方法,Octopus v2在训练和推理阶段采用了独特的函数token策略:
-
将常用函数名称标记化为特殊的函数token,使模型能够更准确地预测函数名称,提高了效率。
-
构建了包含相关查询、函数调用参数以及不相关查询的数据集,并引入了二进制验证机制,确保数据质量。
-
设计了三种不同风格的提示模板,包括单个函数调用、并行函数调用和嵌套函数调用,帮助模型学会将函数描述映射到对应的token。
这些针对性的设计使Octopus v2能够在各种复杂场景中生成准确的函数调用,无论是单独的、嵌套的还是并行的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









