







目录
前言
本课程来自深度之眼《多模态》训练营,部分截图来自课程视频。
文章标题:Learning Transferable Visual Models From Natural Language Supervision
从自然语言监督中学习可转移的视觉模型
作者:Alec Radford等
单位:Open AI
发表时间:2021 arxiv
背景
第一篇多模态带读论文,因此要把多模态的发展历史稍微带入一下。
多模态是有CV和NLP二者融合而来的,两个领域都卷到极致就是多模态。
CV重点关注如何用计算机代替人眼对目标完成识别、跟踪、测量等任务,对图像进行处理;NLP则研究计算机如何处理、运用自然语言,包括语言生成、问答、对话等任务。近年来,以深度神经网络为代表的机器学习和模式识别技术被广泛应用于CV和NLP领域,取得了目前最先进的效果。
人类可以同时使用视觉和语言这两方面的能力来完成一系列任务,CV与NLP的结合(V2L)也成为了人工智能研究领域的重要课题,可以拓展这两个方向的重要应用。从下图可以看到,常见的多模态任务有:图片标注/描述、看图说话/问答等
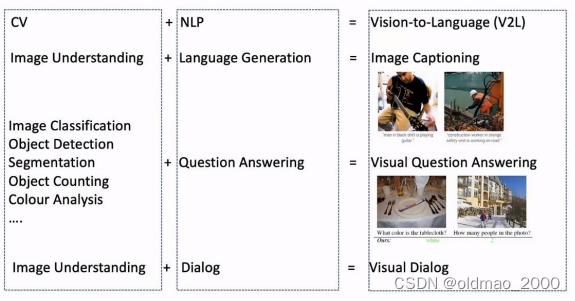
这些多模态任务其实结合了CV和NLP二者的特点,例如:图片标注/描述任务是将图像理解和语言生成任务结合起来;视觉问答任务是将图像分类、目标检测、图像分割、颜色分析等CV任务与NLP的条件生成任务结合起来。
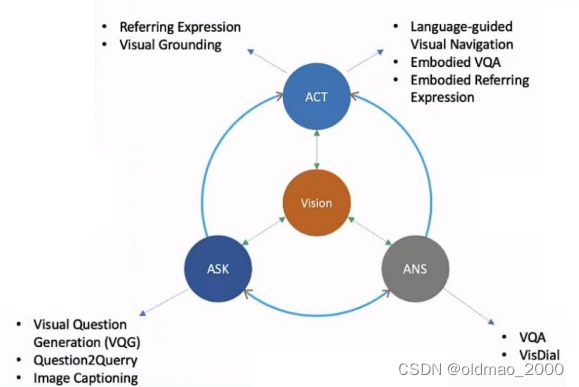
近年来,研究者们试图将动作控制也引入到「视觉-语言」任务的框架中。在给定视觉输入后,我们希望机器能够提出问题、回答问题、并通过和人以及机器之间的语言交流执行某些动作。
具身人工智能是目前的一个热点研究领域,它要求智能体能够感受周围的环境,并做出相应的决策,完成看、说、听、行动、推理等任务。
Embodied AI
See: perceive their environment through vision or other senses.
Talk: hold a natural language dialog grounded in their environment.
Listen: understand and react toaudio input anywhere in a scene.
Act: navigate and interact with their environment to accomplsh goals.
Reason:consider and plan for the long-term consequences of their actions.
Embodied AI isthe field for solving AI problems for virtual robots that can move, see speak, and interact in the virtual world and with other virtual robots-these simulated robot solutions are then transferred to real world robots.
<出自Luis Bermudez, Overview of Embodied Artificial Intellegence>
总体来说就是以视觉为中心,通过不同的交互就形成多模态要研究的问题(坑)
缘起/摘要
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task
of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on.
在构建计算机视觉模型时,只是为了某一个或某一组任务而构建数据集,往往需要大量的劳动力来进行数据标注,并且数据集的构建成本很高。
而且,这些标准的计算机视觉模型擅长一类任务,甚至只擅长这一类任务。若是想要让模型适应新的任务需要花费大量的精力和成本。
同时,一些训练时表现好的模型可能在测试中表现不佳。为了解决这些问题,CLP诞生了。
OpenAl从互联网收集了4亿(图像,文本)对的数据集,在预训练后,用自然语言描述所学习的视觉概念concept//ontology,类似于GPT的“zero-shot”功能(对标ResNet-50)。
数据集
现有的论文使用了三个数据集:MS-COCO,VisualGenome,和YFCC100M。
MS-COCO,VisualGenome是高质量的手工标注数据集,数量较小,约100000个。
YFCC100M有1亿张照片,每个图像质量不同,许多图像使用自动生成的文件名,例如e 20160716 113957.JPG作为名称或者描述。经过过滤后,只保留有正常标题或描述的图像,数据集缩小到1500万张照片。与ImageNet的数据集大小大致相同。
其中COCO是一个多功能的数据集:
拟解决问题
| 问题 | 解决方案 |
|---|---|
| 数据集成本巨大 | ImageNet中1400万张图片的标注工程量巨大。而CLIP使用Internet.上公开的文本图像对。 |
| 任务单一 | 适用于各种视觉分类任务,而不用额外训练。 |
| 实用型不强 | CLIP可以不用在数据集上训练,直接在基准上评估,而不是仅优化其在基准性上的性能。 |
精读
Introduction
前面两段很重要,是整个文章引入要解决问题的段落,提出问题,作者最后使用自问自答的方式进行结束。
在NLP中,预训练的方法目前其实已经被验证很成功了,像BERT和GPT系列之类的。其中,GPT-3从网上搜集了400 billion byte-pair-encoded tokens进行预训练然后可以在很多下游任务上实现SOTA性能和zero-shot learning。这其实说明从web-scale的数据中学习是可以超过高质量的人工标注的NLP数据集的。
然而,对于CV领域,目前预训练模型基本都是基于人工标注的ImageNett数据集(含有1400多万张图像)那么借鉴NLP领域的GPT-3从网上搜集大量数据的思路,我们能否从网上收集大量图像数据用于训练视觉表征模型呢? Prior work is encouraging.
最后那句回答相当妙,既自问自答,又引出了Prior work有哪些,作者接下来回顾并总结了Prior work中两条表征学习路线:
(1)构建image和text的联系,比如利用已有的(image,text)pair数据集,从text中学习image的表征;
(2)获取更多的数据(不要求高质量,也不要求full labeled)然后做弱监督预训练,就像谷歌使用的JFT-300M数据集进行预训练一样(在JFT数据集中,类别标签是有噪声的)。具体来说,JFT中一共有18291个类别,这个模型的类别比ImageNet的1000类要多得多,但尽管已经有上万类了,其最后的分类器其实还是静态的、有限的,因为你最后还是得固定到18291个类别上进行分类,那么这样的类别限制还是限制了模型的zero-shot能力。
然后基于这些Prior work,作者进行了分析:这两条路线其实都展现了相当的潜力,前者证明paired text-image可以用来训练视觉表征,后者证明扩充数据能极大提升性能,即使数据有noise。
于是high-level.上,作者考虑从网上爬取大量的(text,image)pair以扩充数据,同时这样的pairs是可以用来训练视觉表征的。作者随即在互联网上采集了4亿个(text,image)对,准备开始训练模型。
以上就初步形成了文章的core idea,并结合figure 1进行表示。
Model
2.1自然语言监督
CLIP方法的核心是从自然语言中的监督中学习感知的想法。正如引言中所讨论的,这不是一个新想法,但是用于描述该领域工作的术语是多种多样的,甚至看似矛盾,并且陈述的动机也多种多样。张等人(Conntrastive learning of medical visual representations from paired images and text. 2020)介绍了从与图像配对的文本中学习视觉表示的方法,但将它们的方法描述为无监督、自我监督、弱监督和分别监督。
本文强调,这一系列工作的共同点不是所使用的特定方法的任何细节,而是将自然语言作为训练信号( training signal,这里应该是想表达想要借鉴自然语言模型监督学习的思想)。所有这些方法都是从自然语言监督中学习的。尽管早期的工作在使用主题模模型和n-gram表示时与自然语言的复杂性作斗争,但深度上下文表示学习的改进表明我们现在拥有有效利用这种丰富监督来源的工具。
上面翻译的不是很通,大概就是作者把之前相关工作(把图像与文本进行匹配)做了引用并进行评价,指出不足,然后表示进一步的工作,引出下一段。
Although early work wrestled with the complexity of natural language when using topic model and n-gram representations, improvements in deep contextual representation learning suggest we now have the tools to effectively leverage this abundant source of supervision.
与其他训练方法相比,从自然语言中学习有几个潜在的优势。与用于图像分类的标准众包标签相比,扩展自然语言监督要容易得多,相反,适用于自然语言的方法可以从互联网上大量文本中包含的监督中被动学习。与大多数无监督或自监督学习方法相比,从自然语言中学习也有一个重要的优势,因为它不仅“只是”学习一种表示,而且还将该表示与语言联系起来,从而实现灵活的零样本迁移。
2.2 创建一个有效的大数据集
现有工作主要使用了三个数据集,MS-C0C0(Lin等人,2014)、Visual Genome(Krishna等人,2017年)和YFCC1000M(Thomee等人,2016年)。虽然MS-C0C0和Visual Genome是高质量的人群标记数据集,但按照现代标准,它们都很小,每个都有大约100,000张训练照片。相比之下,其他计算机视觉系统接受了多达35亿张Instagram照片的训练(Mahajan等,2018)。YFCC100M拥有1亿张照片,是一种可能的替代方案,但每张图像的元数据稀疏且质量参差不齐。许多图像使用自动生成的文件名,如20160716113957.JPG作为“标题”或包含相机曝光设置的“描述”。在过滤以仅保留带有自然语言标题和/或英文描述的图像后,数据集缩小了6倍,只有1500万张照片。这与ImageNet的大小大致相同。
自然语言监督的一个主要动机是互联网上公开的大量这种形式的数据。由于现有数据集并不能充分反映这种可能性,因此仅考虑它们的结果将低估这一研究领域的潜力。为了解决这个问题,我们构建了一个新的数据集,其中包含从Internet上的各种公开可用资源收集的4亿(图像、文本)对。为了尝试涵盖尽可能广泛的一组视觉概念,我们搜索(图像、文本)对作为构建过程的一部分其文本包括一组500,000个查询中的一个。我们通过包括多达每个查询20,000个(图像、文本)对。结果数据集的总字数与用于训练GPT-2的WebText数据集相似。我们将此数据集称为Web Image Text:WIT。
选择一个有效的预训练方法
先来一段点出模型的关键在于训练的效率是否够高。然后围绕这个点展开:
我们最初的方法类似于VirTex,从头开始联合训练图像CNN和文本转换器来预测图像的标题。然而,我们在有效地扩展这种方法时遇到了困难。在图2中,我们展示了一个6300万参数的转换器语言模型,它的计算量已经是其ResNet-50图像编码器的两倍,相同的文字情况下,它学习识别ImageNet类的速度比预测词袋编码的更简单的基线慢三倍。
这两种方法都有一个关键的相似之处。他们试图预测每张图像附带的文本的确切词。由于与图像同时出现的描述、评论和相关文本多种多样,因此这是一项艰巨的任务。最近在图像对比表示学习方面的工作发现,对比目标可以比等效的预测目标学习更好的表示(Tian等,2019)
0其他工作发现,虽然图像的生成模型可以学习高质量的图像表示,但它们需要比具有相同性能的对比模型多一个数量级的计算(Chen等人,2020a)。注意到这些发现,我们探索了训练一个系统来解决可能更容易的代理任务,即仅预测哪个文本作为一个整体与哪个图像配对,而不是该文本的确切单词。从相同的词袋编码基线开始,我们将图2中的预测目标替换为对比目标,并观察到零样本传输到ImageNet的效率进一步提高了4倍。
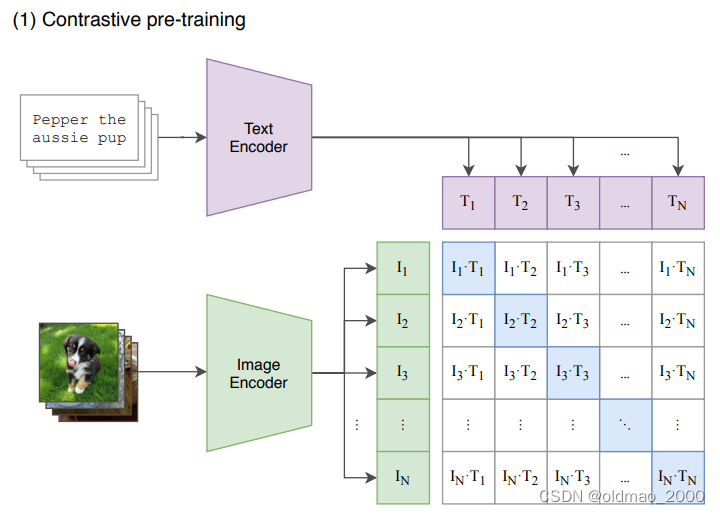
给定一批(图像,文本)对,CLIP被训练来预测一批中实际发生的N×N个可能(图像文本)对中的哪一个。为此,CLIP通过联合训练图像编码器和文本编码器来学习多模态嵌入空间,以最大化批次中的N个正样本对的图像和文本嵌入的余弦相似度,同时最小化(
N
2
−
N
N^2-N
N2−N)负样本对的余弦相似度。我们针对这些相似性分数优化了对称交叉熵损失。据我们所知,这种批量构建技术和目标首先作为多类N对损失Sohn(2016年)引入深度度量学习领域,Oord等人(2018年)作为InfoNCE推广用于对比表示学习损失,最近被Zhang等人(2020年)改编用于医学成像领域的对比(文本、图像)表示学习。
上面这段话与下面这张图结合理解会比较好,可以看到下面图片和文本各有N个,分别进行图像和文本的编码器得到两组N个向量表征,然后做交叉后有N×N个结果,只有对角线上的N是正样本(图像和文本匹配),剩下的是不匹配的情况。然后构造损失函数,使得正样本的图像和文本表征的余弦相似度越大越好,而不匹配的图像和文本表征的余弦相似度越小越好。
由于预训练数据集很大,过拟合不是主要问题,与Zhangetal.(2020)的实现相比,训练CLIP的细节得到了简化。我们从头开始训练CLIP,没有用ImageNet权重初始化图像编码器或用预训练权重初始化文本编码器。我们不使用表示和对比嵌入空间之间的非线性投影,这是由Bach-man等人(2019)引入并由Chen等人(2020b)推广的变化。相反,我们仅使用线性投影将每个编码器的表示映射到多模态嵌入空间。我们没有注意到两个版本之间的训练效率差异,并推测非线性投影可能与细节共同适应当前图像仅在自监督表示学习方法中。我们还从Zhang等人中删除了文本转换函数
t
u
t_u
tu。(2020)从文本中统一采样单个句子,因为CLIP预训练数据集中的许多(图像、文本)对只是一个句子。我们还简化了图像变换函数
t
v
t_v
tv。来自调整大小的图像的随机方形裁剪是训练期间使用的唯一数据增强。最后,控制softmax中logits范围的温度参数(temperature parameter):
τ
\tau
τ,在训练期间直接优化为对数参数化的乘法标量,以避免变成超参数。
关于temperature parameter,可以看这里:
https://zhuanlan.zhihu.com/p/544432496
2.4 选择模型(选择Encoder)
我们考虑图像编码器的两种不同架构。首先,我们使用ResNet-50(He et al.,2016a)作为图像编码器的基础架构,因为它被广泛采用且性能得到验证。我们使用He et al.(2019)的ResNet-D改进和Zhang(2019)的抗锯齿rect-2模糊池对原始版本进行了一些修改。我们还用注意力池机制替换了全局平均池化层。注意力池被实现为“转换器式”多头QKV注意力的单层,其中查询以全局平均池化为条件。对于第二种架构,我们试验了最近推出的Vision Transformer(ViT)(Dosovitskiy等人,2020年)。我们密切关注他们的实现,只是在变换器之前向组合的补丁和位置嵌入添加了一个额外的层归一化,并使用了稍微不同的初始化方案。
文本Encoder部分:采用的是一个Transformer(Vaswani et al.,20l7),其架构修改见Radford et al.(2019)。作为基本大小,我们使用63M参数的12层512宽模型和8个注意力头。
转换器对文本的小写字节对编码(BPE)表示进行操作,词汇大小为49,152(Sen-nrich et al.,2015)。为了计算效率,最大序列长度上限为76。文本序列用【SOS】和【EOS】标记括起来,并且在【EOS】标记处的转换器最高层的激活被视为特征层归一化,然后线性投影到多模态嵌入空间中的文本表示。在文本编码器中使用了掩码自注意力,以保留使用预训练语言模型进行初始化或添加语言建模作为辅助目标的能力,尽管对此的探索留待未来工作。
2.5训练
我们训练了一系列5个ResNets和3个Vision Transformers。.对于ResNets,我们训练了一个ResNet-50、一个ResNet-101,然后还有3个遵循EfficientNet风格的模型缩放并使用大约4倍、16倍和64倍的计算ResNet–50。它们分别表示为RN50x4、RN50x16和RN50x64。
对于Vision Transformers,我们训练了VT-B/32、ViT-B/16和ViT-L/14.我们训练所有模型32个epoch。
我们使用Adam优化器和解耦权重衰减正则化应用于所有非增益或偏差的权重,并使用余弦表衰减学习率。当训练1个epoch时,在基线ResNet-50模型上使用网格搜索、随机搜索和手动调整的组合来设置初始超参数。由于计算约束,超参数随后被启发式地调整为更大的模型。可学习的温度参数
τ
\tau
τ被初始化为0.07,并被剪裁以防止将logits缩放超过100,我们认为这是防止训练不稳定所必需的。我们使用非常大的minibatch:32,768。混合精度用于加速训练和节省内存。为了节省额外的内存,使用了梯度检查点、半精度Adam统计和半精度随机舍入文本编码器权重。嵌入相似度的计算也与单独的GPU分片,仅计算其本地批量嵌入所需的成对相似度的子集。最大的ResNet模型RN50x64在592V100GPU上训练需要18天,而最大的Vision Transformer在256
V100上训练需要12天GPU。对于VT-L/14,我们还以更高的336像素分辨率预训练一个额外的epoch,以提高类似以于FixRes的性能。我们将此模型表示为ViT-L/14@336px。
除非另有说明,本文中报告为“CLIP”的所有结果均使用我们发现性能最佳的模型。
小结
模型架构分为两部分,图像编码器和文本编码器,图像编码器可以是resnet50,文本编码器可以是transformer。训练数据是网络社交媒体上搜集的图像文本对。
在训练阶段,对于一个batch的数据,首先通过文本编码器和图像编码器,得到文本和图像的特征,接着将所有的文本和图像特征分别计算内积,就能得到一个矩阵,然后从图像的角度看,行方向就是一个分类器,从文本角度看,列方向也是一个分类器。
而由于我们已经知道一个batch中的文本和图像的匹配关系,所以目标函数就是最大化同一对图像和文本特征的内积,也就是矩阵对角线上的元素,而最小化与不相关特征的的内积。文章的作者从社交媒体上搜集了有大约4亿对的数据。
这里的Encoder最大特点就是没有固定的分类。
在测试阶段,可以直接将训练好的CLIP用于其他数据集而不需要finetune。和训练阶段类似,首先将需要分类的图像经过编码器得到特征,然后对于目标任务数据集的每一个标签,或者你自己定义的标签,都构造一段对应的文本,如下图中的的dog会改造成A photo of a dog,以此类推。然后经过编码器得到文本和图像特征,接着将文本特征与图像特征做内积,内积最大对应的标签就是图像的分类结果。这就完成了目标任务上的zero-shot分类。
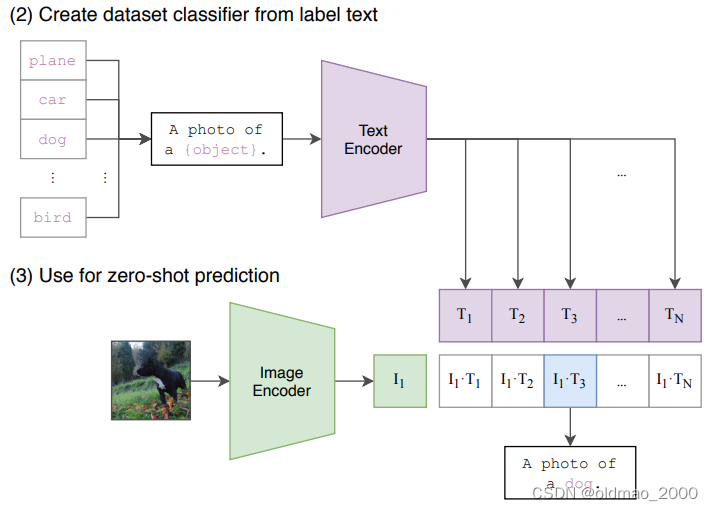
不足:
1.跟sota还差10几个点,性能不够强悍
2.不好做细分类任务
3.不能处理极度分布偏移的情况
4.还是从给定类别去分类
5.利用数据不高效,需要大量数据
6.用了imagenet数据集做调参
7.可能模型有数据偏见
8.fewshot可能更好,但不是本文目标
实验
迁移应用于ImageNet的分类任务的,可以看到,不仅达到ResNet101的效果,且泛化能力远远强于有标签监督学习:
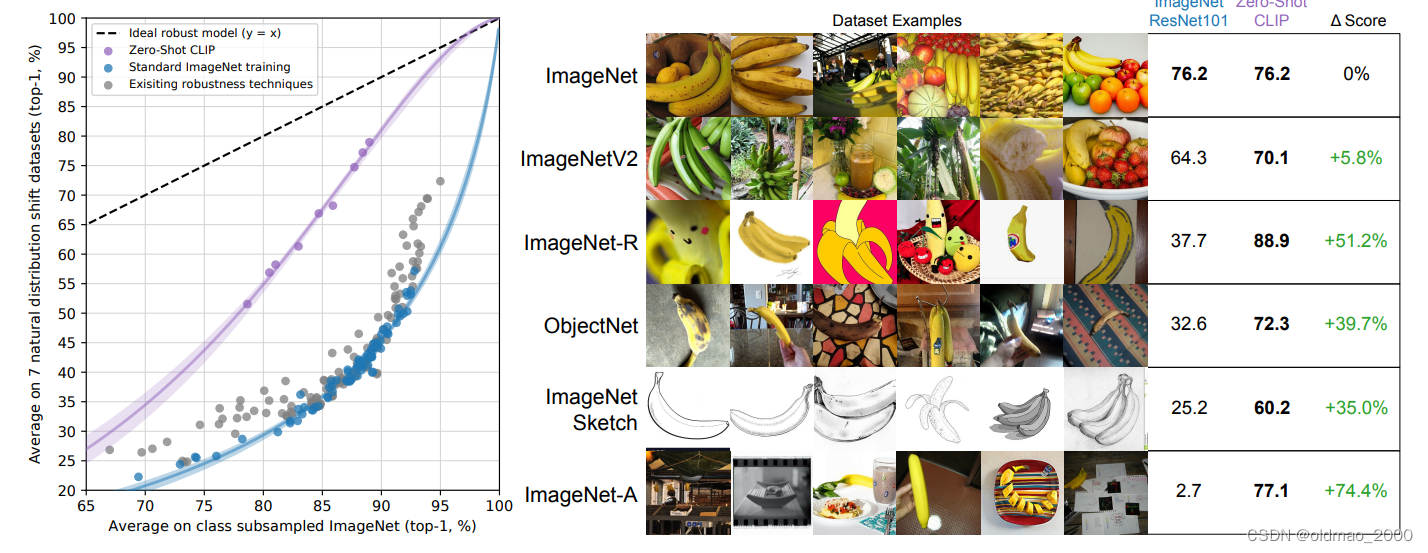
尤其对于第五行,非实物的图片ResNet101的识别率也非常低,CLIP就有60的识别率。
这个图看上去是非常漂亮的,这个实验将imagenet数据集经过重新的筛选,制作了几个变种的版本。
然后将Zero-Shot CLIP与在Imagenet上有监督训练的ResNet101在这些数据集上的分类精度做对比。可以看到随着变种版本的难度增大,ResNet101分类精度愈来愈差,而CLIP的表现则依然很坚挺。
CLIP更擅长于’general和fine-grained’的分类任务,对于一些专用的任务效果可能比较差。
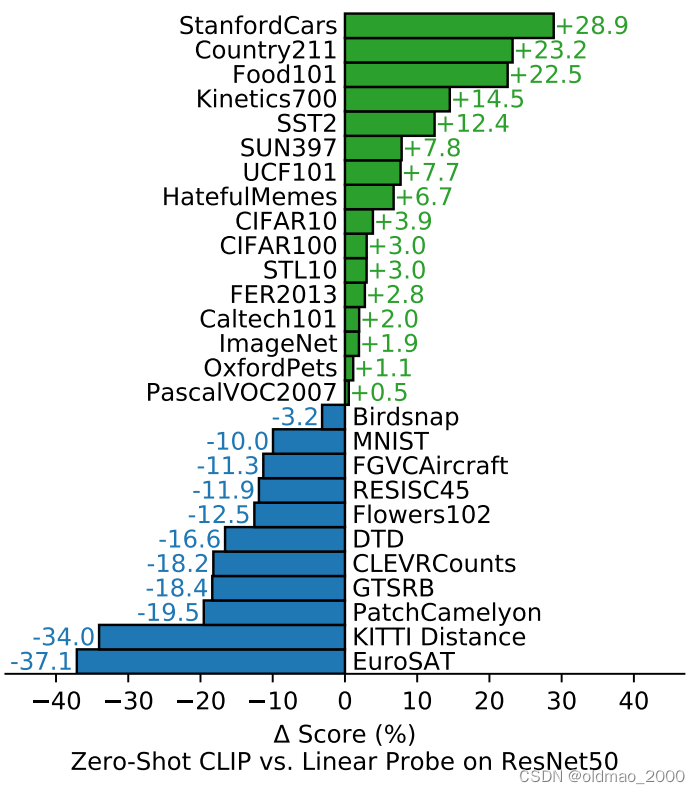
下图是在27个数据集上的对比实验结果,Linear Probe ResNet50是指首先将ResNet50在imagenet数据集上做预训练。接着扔掉最后一层全连接并固定网络参数,重新添加一层线性分类器,然后在这27个数据集上重新训练新增的这层分类器。从实验结果上看,Zero-Shot CLIP在其中16个数据集上都超过了Linear Probe ResNet50,甚至包括了imagenet。
















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











