







paper:LocalViT: Bringing Locality to Vision Transformers
official implementation:https://github.com/ofsoundof/LocalViT
存在的问题
视觉Transformer(Vision Transformers,ViT)源自于机器翻译任务,擅长建模序列中的长距离依赖关系。然而,ViT缺乏捕捉图像中局部结构的能力,而这是卷积神经网络(CNNs)的强项。这一缺陷限制了ViT在需要局部信息(如边缘、线条和形状)的视觉任务中的表现。
创新点
本文旨在将CNNs的局部性机制引入到ViT中,以在不显著增加模型复杂度的情况下提高其性能。具体如下
- 引入深度卷积:本文在视觉Transformer的FFN中引入了深度卷积(depth-wise convolutions),增加了一种局部性机制,能够有效聚合局部信息,从而解决了传统视觉Transformer缺乏局部性的不足。
- Locality组成部分分析:作者通过隔离每个组件的影响,如深度卷积、非线性激活函数、层的位置和隐藏维度扩展比率,分析了所引入的局部性机制的基本属性。
- 性能提升以及广泛的适用性:增强局部建模能力的Transformer在ImageNet2012分类等任务中表现出显著的性能提升,分别比基线模型(DeiT-T和PVT-T)提高了2.6%和3.1%,且仅增加了极少的参数和计算成本。所提出的局部性机制成功应用于多种视觉Transformer,包括DeiT、T2T-ViT、PVT和TNT,展示了该方法在不同Transformer架构中的普适性和有效性。
方法介绍
Input interpretation
Sequence perspective. 考虑一个输入图片 \(\mathbf{X}\in \mathbb{R}^{C\times H\times W}\),首先将其转换为一个token序列 \(\{\hat{\mathbf{X}_i}\in \mathbb{R}^{d}|i=1,...,N \}\),其中 \(d=C\times p^2\) 是embedding维度,\(N=\frac{HW}{p^2}\)。这些token可以聚合成一个矩阵 \(\hat{\mathbf{X}}\in \mathbb{R}^{N\times d}\)。
在self-attention中,token之间的关系是根据映射后的query-key对之间的相似性来建模的,从而得到attention score,然后对映射后的value根据注意力分数进行加权求和得到新的token
![]()
在self-attention层后,是一个前馈网络层feed-forward network,FFN由两个全连接层组成,两个全连接层之间的维度进行了扩展以学习更丰富的特征表示
![]()
其中 \(\mathbf{W_1}\in \mathbb{R}^{d\times \gamma d},\mathbf{W_2}\in \mathbb{R}^{\gamma d\times d}\),\(f(\cdot)\) 表示一个非线性激活函数。其中dimension expansion ratio \(\gamma\) 常设置为4。如图2(a)所示,FFN的输入是一组特征向量的序列。
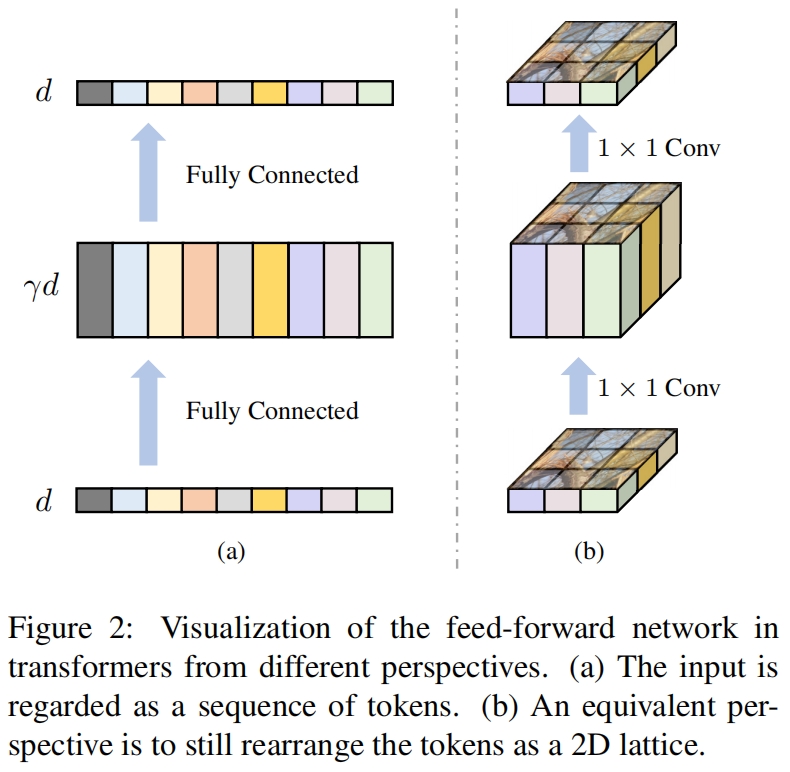
Lattice perspective. 由于FFN是通过point-wise的方式作用于token的序列 \(\mathbf{Z}\in \mathbb{R}^{N\times d}\),一种完全等价的表示是将token序列重新排列成一个二维栅格,如图2(b)所示。
![]()
其中 \(h=H/p,w=W/p\)。操作Seq2Img将一个序列转换成一个二维特征图。每个token被放到特征图上的一个像素位置处,这种表示方法的好处是恢复了token之间的proximity,为locality的引入提供了机会。全连接层可以用1x1卷积替代
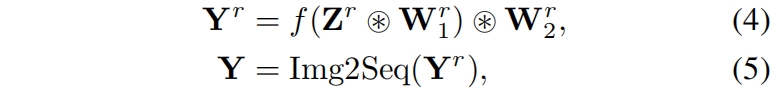
其中 \(\mathbf{W}^r_1 \in \mathbf{R}^{d\times \gamma d\times 1\times 1},\mathbf{W}^r_2 \in \mathbf{R}^{\gamma d\times d\times 1\times 1}\) 是从 \(\mathbf{W}_1,\mathbf{W}_2\) reshape的卷积核,操作Img2Seq将特征图再转换成token序列进入到下一个self-attention层。
Locality
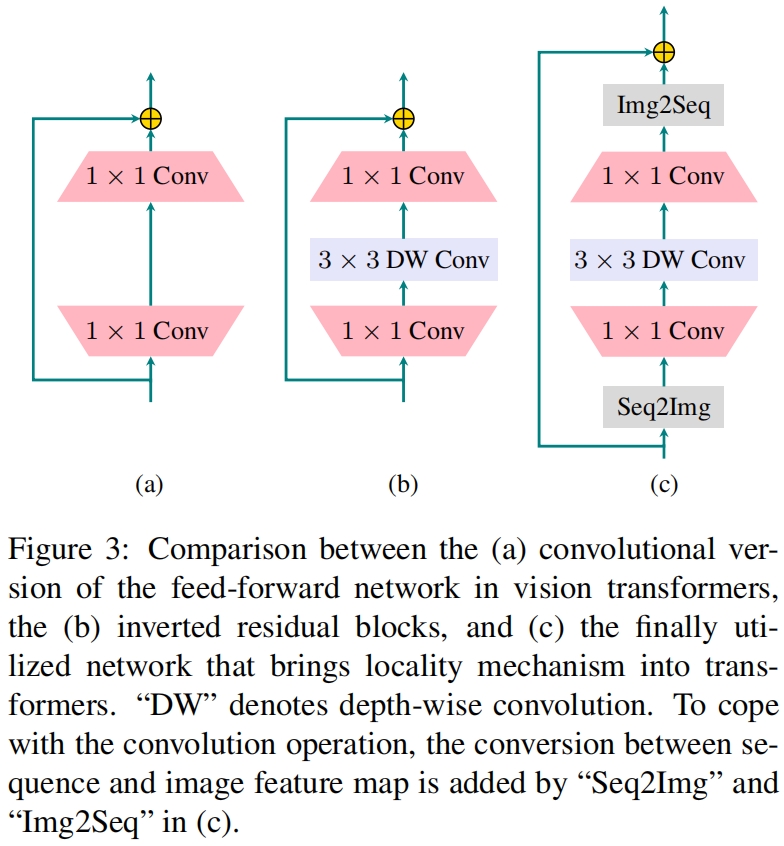
由于只有1x1卷积,缺少相邻像素间的信息交互,而self-attention部分只能捕获token之间的全局依赖关系。因此transformer block没有一种机制来建模相邻像素之间的局部依赖关系。全连接层之间隐藏维度的expansion和FFN中的二维栅格视角让我们联想到MobileNet中的inverted residual block。如图3所示,FFN和inverted residual block的唯一区别就是后者中间多了一层深度卷积,深度卷积在每个通道应用一个 \(k\times k\) 的卷积核,卷积核内的特征聚合起来得到一个新的特征。因此,深度卷积是将局部性引入网络的一种有效的方法。因此作者将深度卷积引入到transformer的FFN中
![]()
其中 \(\mathbf{W}_d\in \mathbb{R}^{\gamma d\times 1\times k\times k}\) 是深度卷积核,最终的网络如图3(c)所示。输入的token序列首先reshape回2D特征图的形式,然后两个1x1卷积和一个深度卷积作用于特征图,最后特征图再resahpe回token序列的形式,进入下一个self-attention layer。
Class token
为了将vision transformer应用于图像分类,一个可训练的class token被添加到token embedding中,即
![]()
当使用深度卷积时需要将token序列reshape成一个二维特征图,但class token多出的一维使得精确的reshape无法得到,因此我们把class token先分离出来
![]()
剩余的embedding token \(\mathbf{Z}\) 先reshape成二维特征图,经过FFN后再reshape回token序列的形式得到 \(\mathbf{Y}\),然后再将class token加回去
![]()
实验结果
locality的作用
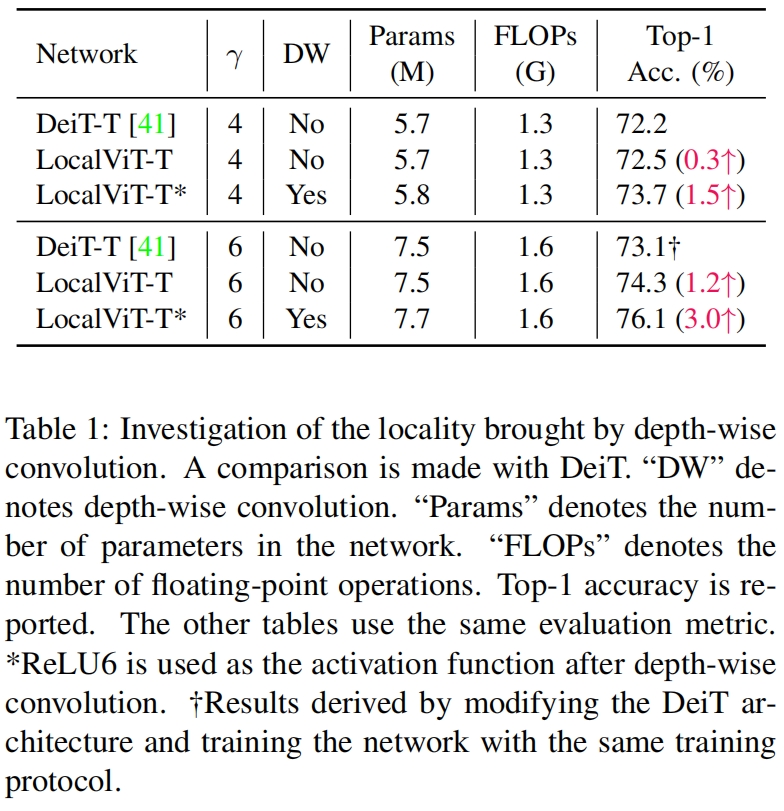
如表1所示,FFN中通过seq2img然后进行1x1卷积操作代替原本的全连接层带来的微小的提升,进一步添加3x3深度卷积带来了更显著的性能提升,表明通过将locality引入vision transformer可以显著提升模型的性能。
作者又研究了深度卷积后不同激活函数的差异,结果如表2所示,可以看到h-swish要比ReLU6的性能更好。在这一步结合不同的通道注意力模块,可以进一步提升性能,当采用SE且squeeze后只保留4个通道时的性能最好。
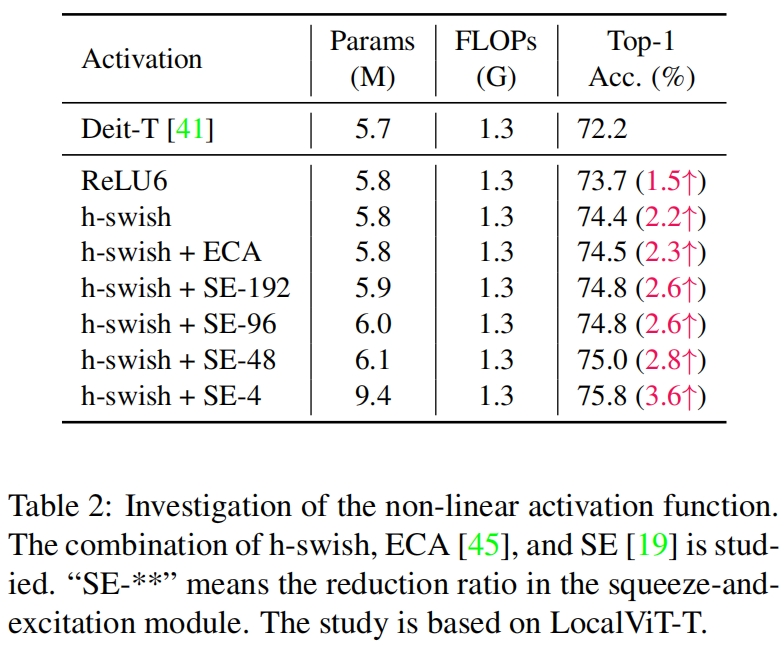
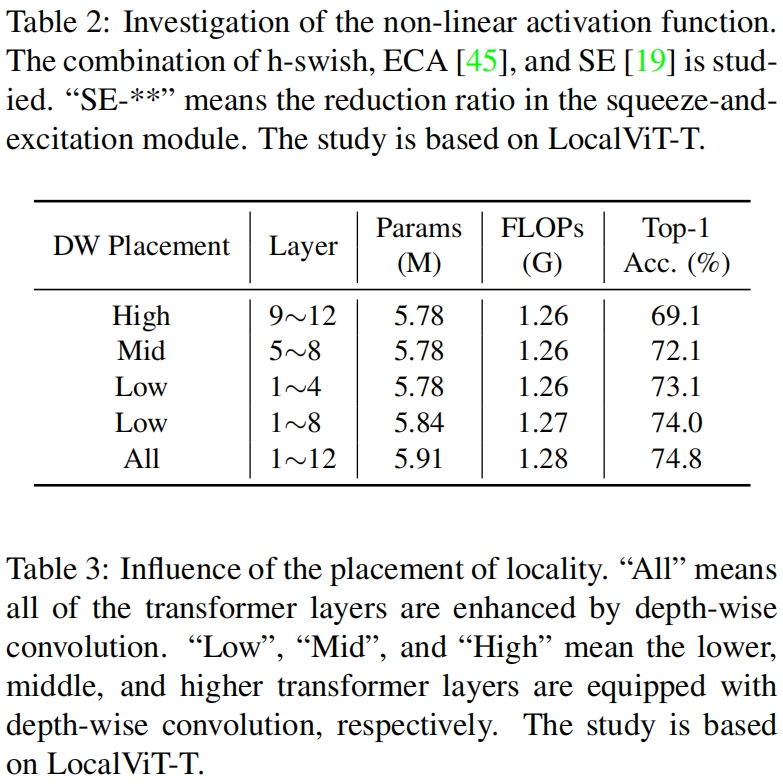
LocalViT-T总共包含12个transformer layer,作者将其每4层分为一组总共划分为3组分比为“Low”、“Mid”、“Hign”,通过在不同阶段的transformer中添加locality来研究locality位置对模型性能的影响。结果如表2所示,可以看到局部信息对lower layer更加重要,这样比较符合直觉,因为当在浅层聚合局部信息时,这种信息可以传播到深层。
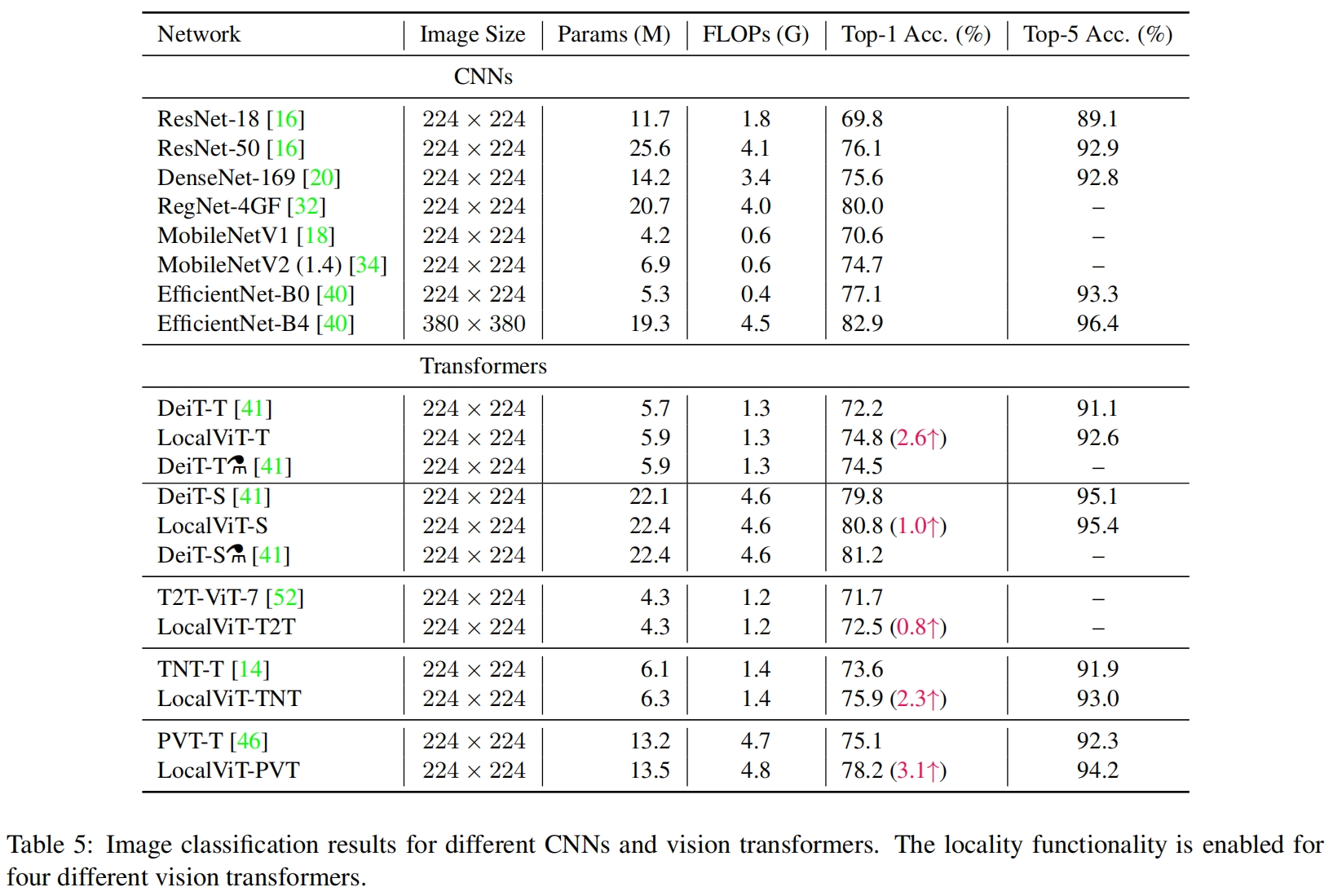
最后作者又将LocalViT和其它SOTA模型进行了对比,结果如下


















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











