









机器学习(6)——Logistic回归
一、Sigmoid函数
首先阐述一下回归的概念,假设现在有一些数据点,我们用一条直线对这些点进行拟合,这个过程就叫做回归。
利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界建立回归公式,以此进行分类。
我们想要的函数应该是,能接收所有的输入,然后预测出类别。在二分类的情况下上述函数输出0或1。最典型的函数就是单位阶跃函数:

图 1:单位阶跃函数
但阶跃函数有一个显然的问题是:不连续。因此我们引入了Sigmoid函数。Sigmoid函数的计算公式如下:
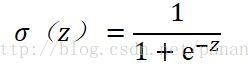
图 2:Sigmoid 函数
其函数曲线如下:
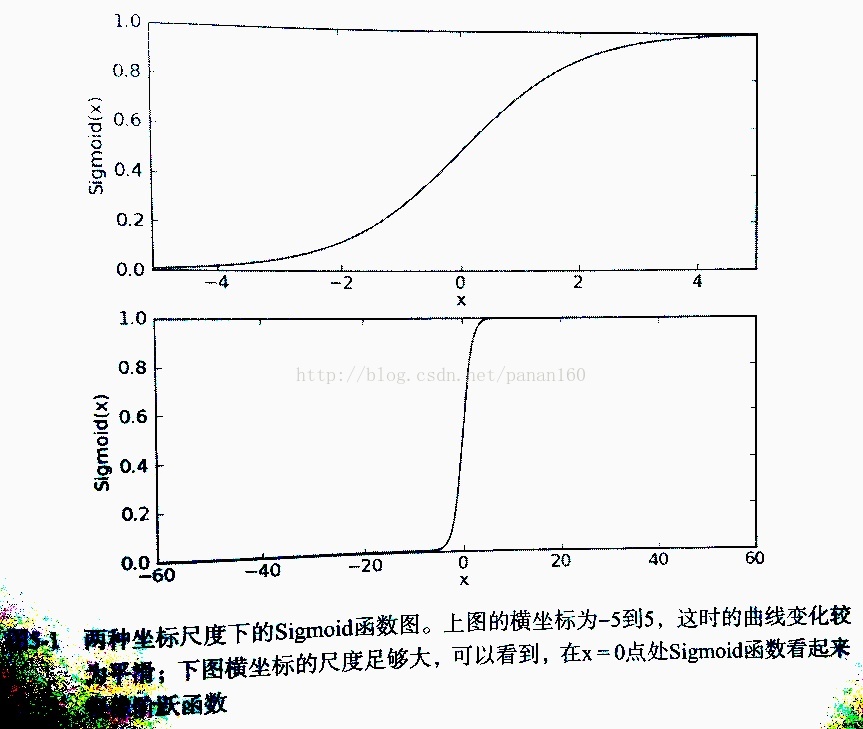
图 3:Sigmoid函数曲线
Sigmoid函数的输入记为z,由下面公式得出:
其中向量x是分类器的输入参数,向量w也就是我们要找到的最佳参数,为寻找最佳参数我们采取的梯度上升的最优化方法。
二、梯度上升
梯度上升(下降)的思想是:要找到某函数的最大值(最小),最好的方法是沿着该函数的地图方向探索。
推导过程公式较多,这里直接贴出手写版公式推导过程:
三、代码实现
至此我们理论部分介绍结束,现在给出一个实际的例子并利用C++代码实现。在下图中我们有class1和classe0两类点,分别用红色和蓝色表示。现在我们要利用Logistic回归的方法找出最佳的分隔线来对两类点分类。

图 4:待分类数据点
1、sigmoid函数,该函数相当于我们公式推到中的H()函数。
Matrix<double> sigmoid(Matrix<double> inX)
{
inX = -1 * inX;
inX.m_exp();
return 1.0/(1 + inX);
}Matrix<double> grandAscent(Matrix<double>& dataMatIn, Matrix<double>& classLabels)
{
int m = dataMatIn.rows(); //行数 100
int n = dataMatIn.cols(); //列数 3
double alpha = 0.001; // 相当于步长 [3/14/2015 pan]
int maxCycles = 500;
Matrix<double> weights(n, 1); // 3*1
weights.init(1.0);
for (int i = 0; i < maxCycles; i++){
Matrix<double> h = sigmoid(dataMatIn*weights); // 100*1
Matrix<double> error = classLabels - h; // 100*1
weights = weights + alpha*dataMatIn.trans()*error;
}
return weights;
}3、从文本文件加载数据
void loadDataSet(Matrix<double>& dataMat, Matrix<double>& labelMat)
{
fstream infile;
infile.open("testSet.txt", ios::in);
while (!infile.eof())
{
float x1 = .0, x2 = .0;
int i = 0;
infile >> x1 >> x2 >> i;
dataMat.push_row(1.0, x1, x2);
labelMat.push_row(i);
}
}其中Matrix是我自己设计的矩阵类,内部包含了一个vector<vector<>>来存储数据,实现了基本的矩阵操作。
最后经过计算,weights[0]=4.1241,weigths[1]=0.4801,weights[2]=0.6168
分类结果如下图:
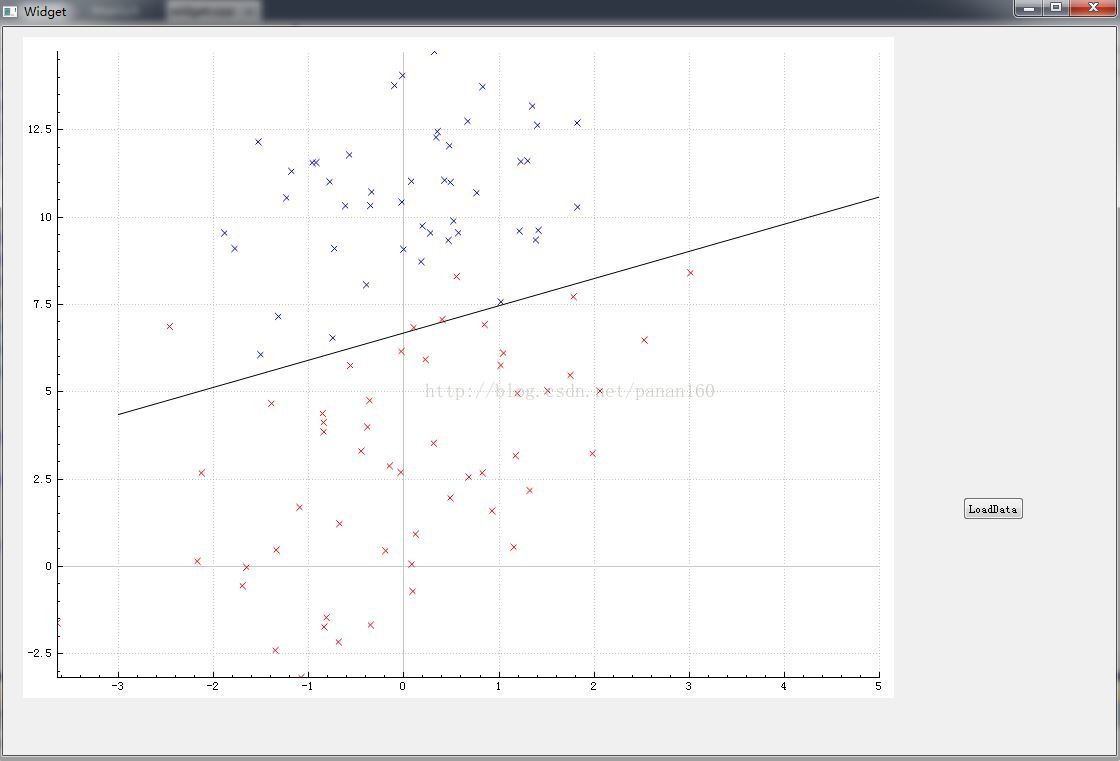
说明:绘图我是利用QT完成的,其中还用到了QCustomPlot库,由于对QT并不熟悉,这里我就不在介绍了。















 3103
3103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









