







论文地址:
《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》
亮点:
- 同时探索输入分辨率、网络的深度和宽度的影响
深度和宽度是深度神经网络的两个基本维度,分辨率不仅取决于网络,也与输入图片的尺寸有关。深度——神经网络的层数,增加网络的深度(depth)能得到更加丰富、复杂的特征并能够很好地迁移到其他任务,但网络的深度过深会面临梯度消失、训练困难的问题;
宽度——每层的通道数(channel),增加网络的宽度(width)能够获得更高的细粒度的特征并且容易训练,但对于width很大但是深度较浅的网络往往很难学习到更深层次的特征;
分辨率——是指网络中特征图的分辨率,一般在没有必要对涉及像素的物理分辨率进行实际度量时,通常会称一幅大小为M*N的数字图像的空间分辨率为M*N像素,像素越小,单位长度所包含的像素数据就越多,分辨率也就越高,但同样物理大小范围内所对应的图像的尺寸也会越大,存储图像所需要的字节数也越多。增加输入网络的图像分辨率能够潜在获得更高细粒度的特征模块,但对于非常高的输入分辨率,准确率的增加率也会减少,并且大分辨率图像也会增加计算量。
1. 简介
不知你有没有思考一下的一些问题:
为什么输入图像分辨率要固定为224?
为什么卷积的个数要设置为某个值?
为什么网络的深度设为这么深?
在本文中,EfficientNetV1 使用 NAS(Neural Architecture Search)技术来搜索网络的图像输入分辨率 r,网络的深度 depth 以及 channel 的宽度 width 三个参数的合理化配置。
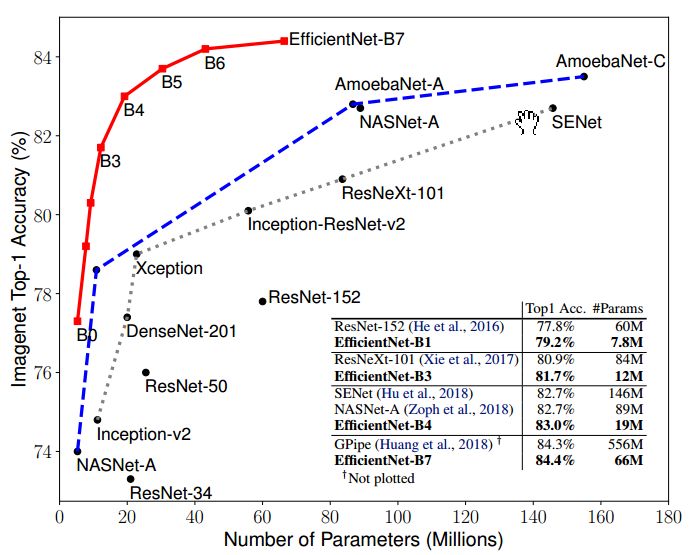
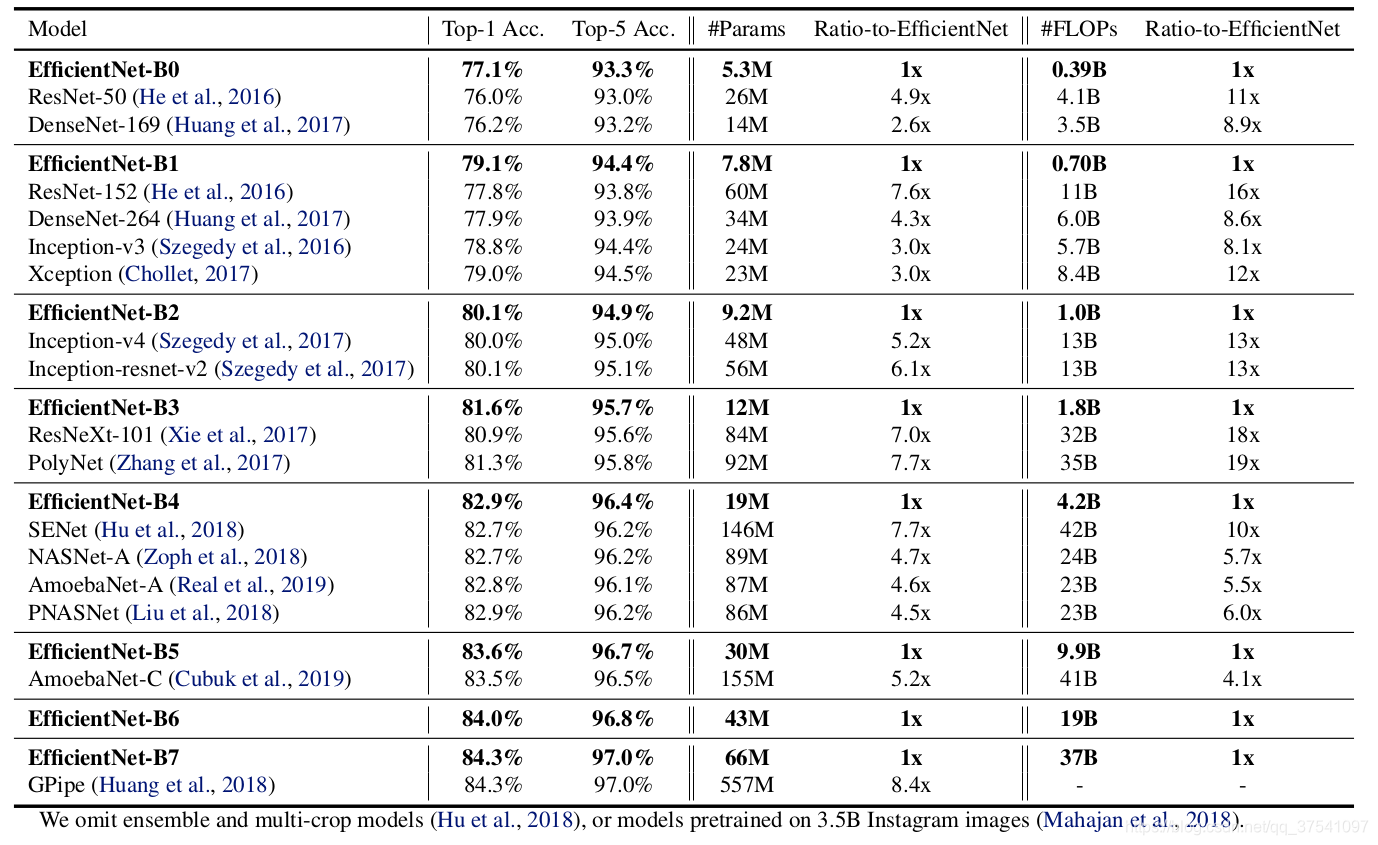
EfficientNet v1是由Google团队在2019年提出的,所提出的EfficientNet-B7在Imagenet top-1 上达到了当年最高准确率84.3%,与之前准确率最高的GPipe相比,参数量仅仅为其1/8.4,推理速度提升了6.1倍。
这篇论文最主要的创新点是Model Scaling. 论文提出了compound scaling,混合缩放,把网络缩放的三种方式:深度、宽度、分辨率,组合起来按照一定规则缩放,从而提高网络的效果。EfficientNet在网络变大时效果提升明显,把精度上限进一步提升。
EfficientNet的主要创新点并不是结构,不像ResNet、SENet发明了shortcut或attention机制,EfficientNet的base结构是利用结构搜索搜出来的,然后使用compound scaling规则放缩,得到一系列表现优异的网络:B0-B7。下面两幅图分别是ImageNet的Top-1 Accuracy随参数量和FLOPs变化关系图,可以看到EfficientNet饱和值高,并且到达速度快。

2. Model Scaling
直观上来讲,输入分辨率、网络的深度和宽度三种缩放方式并不独立。对于分辨率高的图像,应该用更深的网络,因为需要更大的感受野,同时也应该增加网络宽度来获得更细粒度的特征。之前增加网络参数都是单独放大这三种方式中的一种,并没有同时调整,也没有调整方式的研究。EfficientNet使用了compound scaling方法,统一缩放网络深度、宽度和分辨率。
EfficientNet的设想就是能否设计一个标准化的卷积网络扩展方法,既可以实现较高的准确率,又可以充分的节省算力资源。因而问题可以描述成:如何平衡分辨率、深度和宽度这三个维度,来实现网络在效率和准确率上的优化。
在之前的一些论文中,通常会调整宽度width、深度depth、输入图像分辨率resolution其中的一个,来进行手工的调优。有些会在baseline网络如图(a)增加width即增减卷据核的个数(增加feature map的channel)来提升网络的性能如图(b)所示;有些会在baseline网络如图(a)增加depth即使用更多的层结构来提升网络的性能如图(c)所示;有些会在baseline网络如图(a)增加输入图片的分辨率resolution来提升网络的性能如图(d)所示;但是我们都知道深度、宽度和分辨率是绝对不可能是相互独立的关系,而是相互依赖的,所以本篇论文中会同时增加网络的width、网络的深度depth以及输入网络的分辨率resolution来提升网络的性能如图(e)所示:
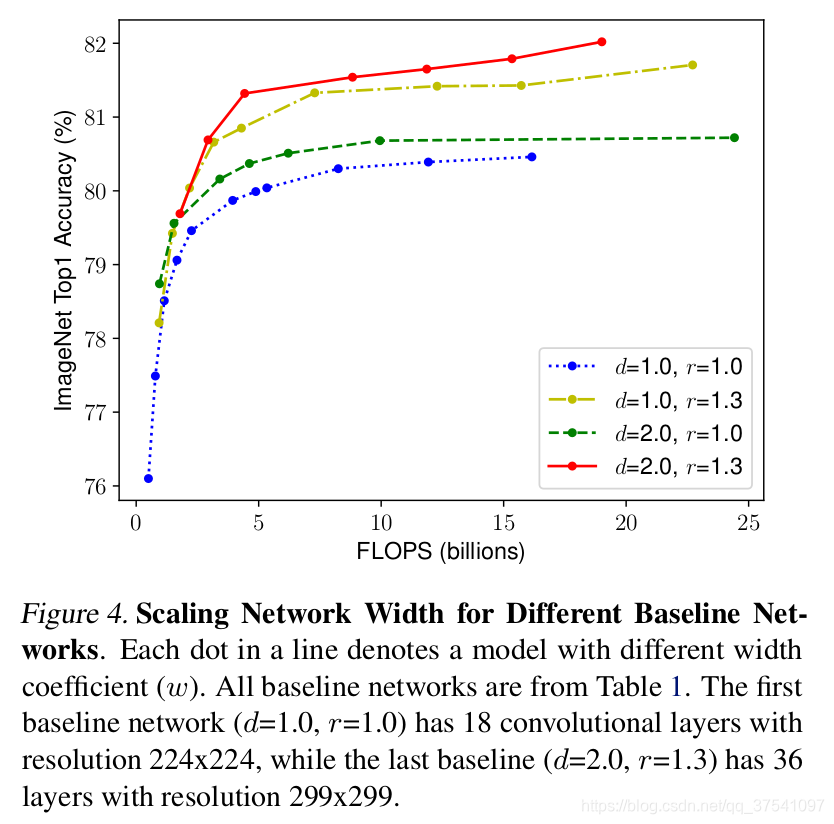
下图显示在基准baseline(EfficientNetB-0)上分别增加Width、Depth以及resolution后得到的统计结果。可以看出在增加单个元素的时候,Accuracy大约增加到80%就结束了。

接着作者又做了一个实验,采用不同的d,r组合,然后不断改变网络的width就得到了如下图所示的4条曲线,通过分析可以发现在相同的FLOPs下,同时增加d和r的效果最好。
- FLOPs 与
d的关系是:当d翻倍,FLOPs 也翻倍。 - FLOPs 与
w的关系是:当w翻倍,FLOPs 会翻 4 倍。 - FLOPs与
r的关系是:当r翻倍,FLOPs 会翻4倍。
EfficientNet的规范化复合调参方法使用了一个复合系数ϕ,来对三个参数进行符合调整
作者在基准网络 EfficientNetB-0上使用 NAS 来搜索 α , β , γ这三个参数,对于不同的基准网络搜索出的 α , β , γ这三个参数不定相同。如果直接在大模型上去搜索 α , β , γ 这三个参数可能获得更好的结果,但是在较大的模型中搜索成本太大,所以这篇文章就在比较小的 EfficientNetB-0 模型上进行搜索的。计算成本太大了。
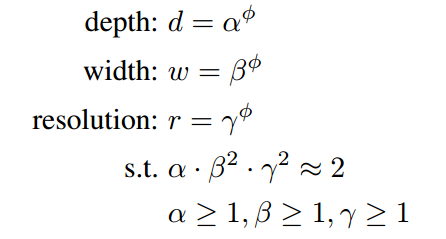
3. MBConv结构
MBConv其实就是MobileNet V3网络中的Inverted Residual Block,但也有些许区别。一个是采用的激活函数不一样(EfficientNet的MBConv中使用的都是Swish激活函数),另一个是在每个MBConv中都加入了SE(Squeeze-and-Excitation)模块。下图是我自己绘制的MBConv结构。
如图所示,MBConv结构主要由一个1x1的普通卷积(升维作用,包含BN和Swish),一个kxk的Depthwise Conv卷积(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的普通卷积(降维作用,包含BN),一个Droupout层构成。搭建过程中还需要注意几点:
第一个升维的1x1卷积层,它的卷积核个数是输入特征矩阵channel的n,n ∈ { 1 , 6 } }。
当n = 1时,不要第一个升维的1x1卷积层,即Stage2中的MBConv结构都没有第一个升维的1x1卷积层(这和MobileNetV3网络类似)。
关于shortcut连接,仅当输入MBConv结构的特征矩阵与输出的特征矩阵shape相同时才存在(代码中可通过stride==1 and inputc_channels==output_channels条件来判断)。
SE模块如下所示,由一个全局平均池化、两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数。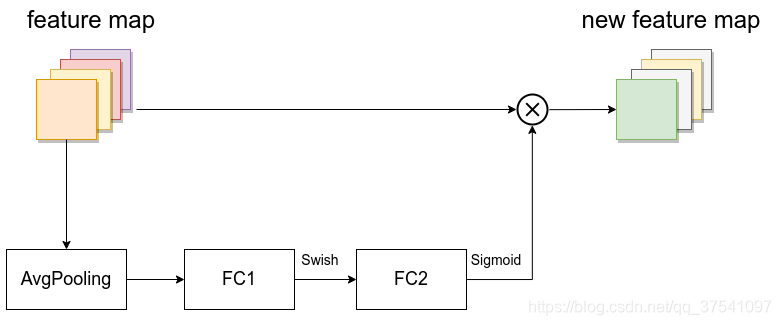
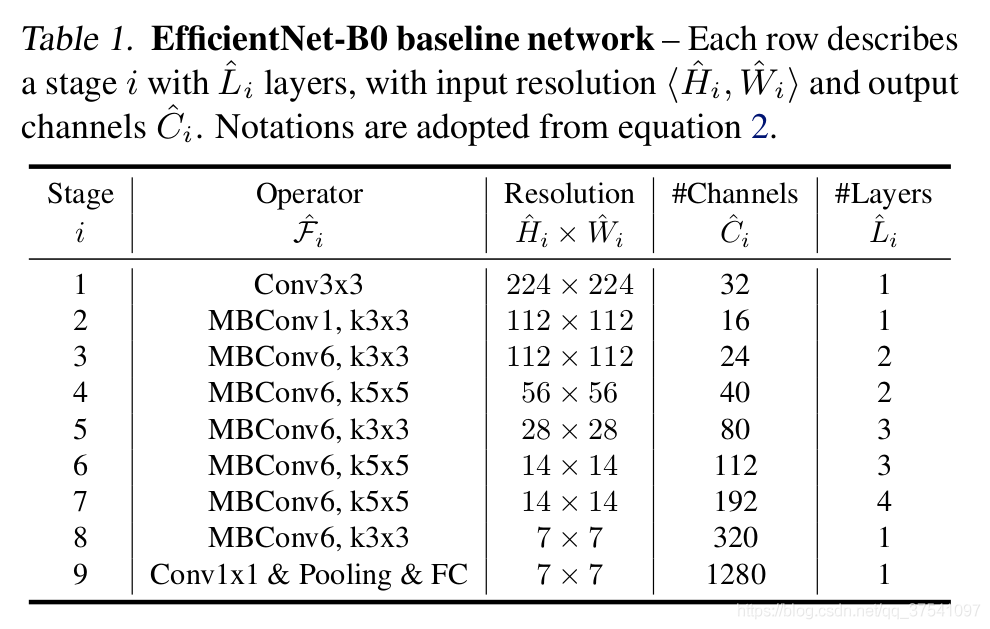
4. EfficentNet v1网络结构
B0:
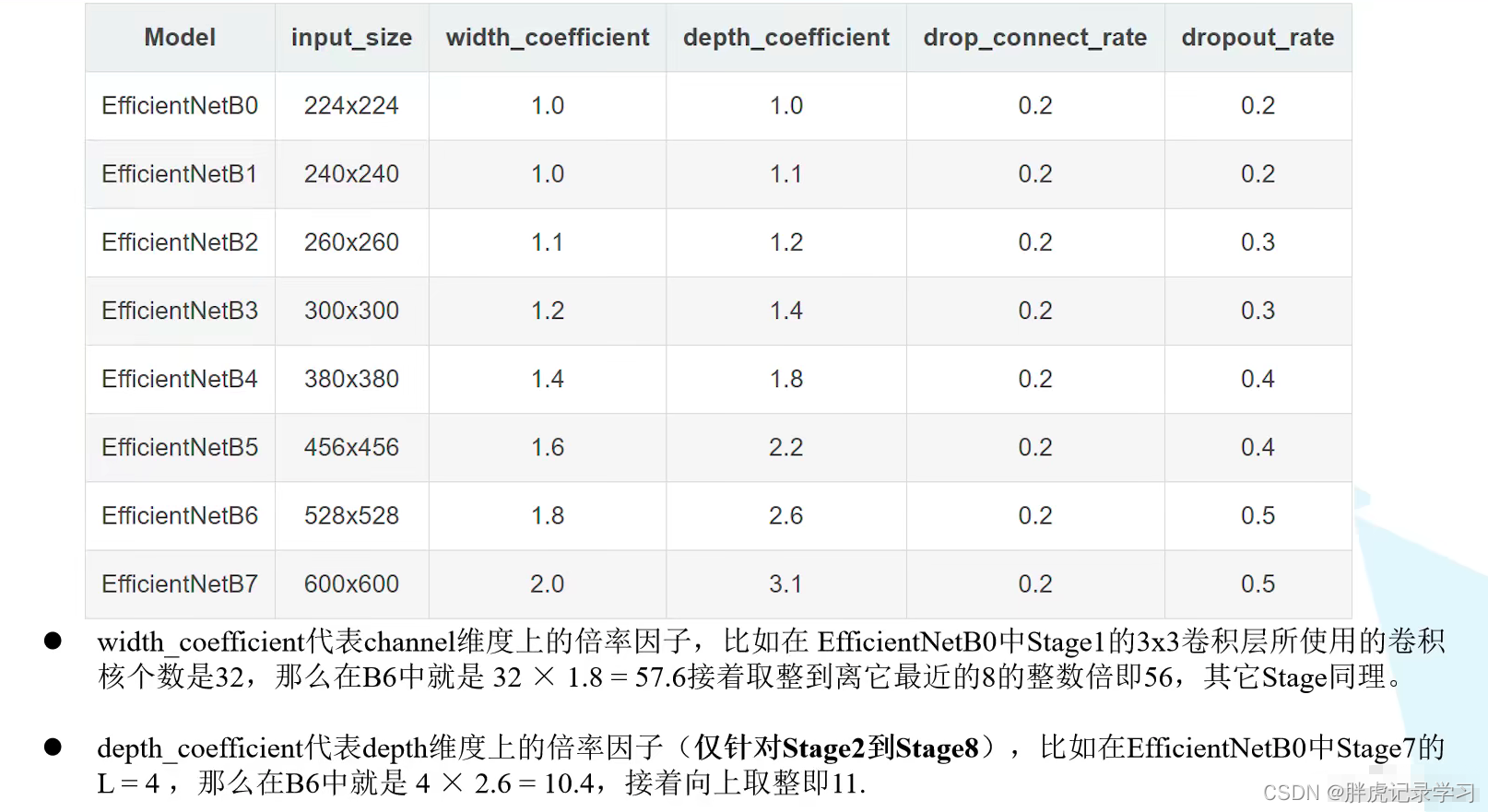
其他:
性能对比:
5. 感想
- 论文展示了谷歌各种l厉害的调参能力,在各个参数量级上精度都超过了之前的SOTA,但是并没有告诉我们尝试的准则,仅仅展示了结果而已;
- 实际部署算法的时候往往不太追求极限精度,反而更多的要考虑模型大小和资源消耗,而EfficientNet用复合scaling的方法从精度低的小网络放缩到精度高的大网络 ,精度和资源消耗能呈现出正相关的效果。更改
就行了。
- 调参
参考文献:
仅为学习记录,侵删!
















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











