






摘要
近年来使用单目视频作为输入的自监督算法在深度和姿态估计领域取得了不俗的进展,但是这种算法存在两个问题:1.场景中的运动物体违背了静态场景的假设,所以使性能受限。2. 由于单目视频的尺度不确定向,只能推理出相对深度,而不能推理出绝对深度。
引言
原文:To the best of our knowledge, no previous work (unsupervised learning from monocular videos) addresses the scale-inconsistency issue mentioned above. To this end, we propose a geometry consistency loss for tackling the challenge.
相关工作
略
尺度一致的深度估计和姿态估计的无监督学习
原文:Given two consecutive frames (
I
a
I_a
Ia,
I
b
I_b
Ib) sampled from an unlabeled video, we first estimate their depth maps (
D
a
D_a
Da,
D
b
D_b
Db) using the depth network, and then predict the relative 6D camera pose
P
a
b
P_{ab}
Pab between them using the pose network.
创新:
-
提出了几何一致性损失 : L G C :L_{GC} :LGC
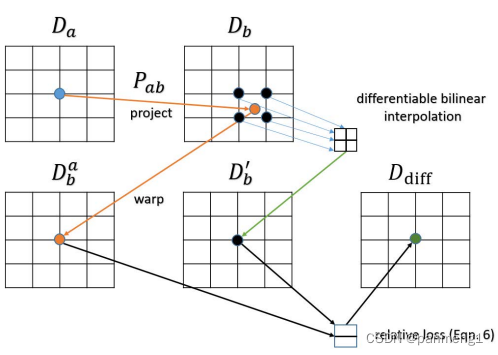
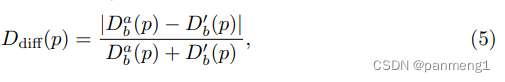

-
提出了动态物体掩码 M M M:
分为两部分,第一个部分是self-discovered mask:

第二个部分是Godard在ICCV2019提出来的:
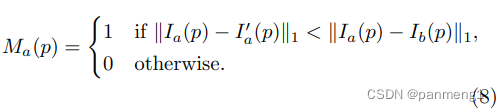















 964
964











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









