







文章目录
1. 为什么要做这个工作
在这篇工作提出之前,很少有工作在点集上应用深度学习。
本篇的前序工作PointNet算是第一个在点集上通过深度学习来进行点特征提取并进一步进行应用的。但是PointNet的缺陷在于:无法捕捉局部细节,无法捕捉那些由点之间距离导致的一些局部特性的改变。
2. 这篇工作做了件什么事
-
引入了一个分层神经网络,在输入点集的嵌套划分上迭代地运用PointNet。利用度量空间中的距离,网络能够随着上下文规模的增加来学习局部特征;
-
通常点集是以变化的密度进行采样的,有的地方的密度大,有的地方密度小,这容易导致在均匀密度上训练的网络出现性能下降的情况。这里进一步提出了新的集合学习层,来应对这种情况,并进一步连接多个层的集合特征。
通过这两种技术上的创新,使得PointNet++能够更加高效和鲁棒地学习点集的特征。
3. 介绍
这里进一步说一下Introduction提到的内容。
使用3D scanners扫描物体得到的点云,可能存在的问题是,距离空间上定义出所谓的“邻居”,可能会展现出不同的属性。这里我理解的是,比如铰接物体中的门框和门,门框和门部分那些点的距离很接近,但是实际上,它们具体所属的属性是不一致的,一些属于门框,属性应该是static part,一些属于门,属性是motion part。作者给出结论:不同位置点的密度和属性可能是有别的
PointNet做的事情是,学习了一个逐点的空间编码,并将所有独立点的特征进行聚集成一个全局的点云的属性。PointNet这样的设计没有办法捕捉局部结构,而局部结构式卷积结构成功的关键。CNN就是在规则的网格上在多个分辨率上捕捉信息,low level的神经元就捕捉较小的感受野,high level的神经元捕捉较大的感受野。通过hierarchy的形式来逐步捕捉一些局部细节,有利于泛化到那些未见过的case。因为未见过的case在局部细节上可能存在与训练集局部细节相同的地方,即使global不一样,细节上是一样的,也有助于对未见过case的理解。
PointNet++为了进一步捕捉局部特征,首先通过距离度量来将一组点划分成重叠的局部区域;接着,从这些比较接近的邻居中捕捉精细的几何结构,进一步提取局部特征;最后,局部特征被进一步聚合(grouped),从而形成大的单元,进一步产生high level的特征。重复上述三个步骤直至获得整个点集的特征。
PointNet解决了两个问题:如何生成点集的划分、如何通过一个局部特征学习器来提取一组点的特征。这两个问题相互影响,因为点集的划分产生跨划分的公共结构(这句话摘自原文,但是由于翻译问题没看懂),所以局部特征学习器的特征是共享的,类似于卷积的设定。这里的basic building block是PointNet,PointNet能够处理无序点集并进行语义特征提取,同时对输入数据的缺失是鲁棒的。PointNet提取局部点的特征并形成high level的表达,PointNet++在划分的输入点集中循环地运用PointNet。
如何生成重叠的点集划分?每一个划分都是在欧式空间中定义的,被定义为一个邻居球(neighborhood ball),参数化形式是使用中心位置和大小(centroid location and scale)表达的。为了完全覆盖点集,中心位置(centroids)的定义是通过最远点采样定义的。不同于体素CNN中使用固定步长来进行扫描,这里的局部感受野是独立于输入数据和度量,所以会更有效和高效。
本文假设输入数据的点云不是均匀的,这样比较符合结构传感器扫描的结果,在不同区域上点云的密度是不一样的。这可能导致的一个问题是,由过少的点组成的小的neighborhood可能会导致不足够让PointNet鲁棒地捕捉一些细节。
针对这个问题,PointNet++提出的解决办法是:在训练过程中进行随机丢弃,网络能够自适应地在不同尺度上检测到的结果进行加权,根据输入数据来组合多尺度特征。
4. 问题描述
χ = ( M , d ) \chi=(M,d) χ=(M,d),其中 M ⊆ R n M\subseteq\mathbb{R}^n M⊆Rn是点集, d d d是距离度量。学习目标是函数 f f f,以 χ \chi χ为输入,产生符合 χ \chi χ的语义信息。在实践过程中,这样的 f f f可以被用于分类函数,给 χ \chi χ指配一个标签,并给 M M M中的每一个点分出一个标签。
5. 方法
论文的方法可以被视作加了分层结构的PointNet。在5.1中回顾PointNet,5.2中介绍引入分层结构的PointNet,5.3提出了能够在不均匀采样的点集中鲁棒学习特征PointNet++的方法。
5.1 PointNet回顾
给定无序点集 x 1 , x 2 , . . . , x n {x_1,x_2,...,x_n} x1,x2,...,xn,其中 x i ∈ R d x_i∈\mathbb{R}^d xi∈Rd,进一步定义一组函数 f : χ → R f: \chi→\mathbb{R} f:χ→R来将一组点匹配到一个向量中:
f ( x 1 , x 2 , . . . , x n ) = γ ( max i = 1 , . . . , n { h ( x i ) } ) f(x_1, x_2,...,x_n)=\gamma(\max_{i=1,...,n}\{h(x_i)\}) f(x1,x2,...,xn)=γ(i=1,...,nmax{h(xi)})
γ \gamma γ和 h h h都使用MLP实现。 h h h可以被视作点的空间编码。PointNet提取出的 f f f在输入点排列变换的情况下是不变的。但PointNet缺乏捕捉不同尺度局部细节的能力。所以引入分层特征学习框架来解决这个限制。
5.2 分层点集特征学习
通过分层来逐步聚集越来越大的局部区域特征。
分层结构由一系列的set abstraction组成,每一组点都被提取产生具有更少元素的新集合。set abstraction由三个部分组成:
-
Sampling layer:最远点采样FPS定义局部区域的中心点centroids;
-
Grouping layer:通过在中心点centroids周围寻找邻居点来构建局部区域集合;
-
PointNet layer:使用一个mini-PointNet来编码局部区域形成特征向量。
set abstraction的输入是 N × ( d + C ) N×(d+C) N×(d+C)的矩阵,代表点云具有 N N N个具有 d d d维坐标和 C C C维特征的点。输出是 N ′ × ( d + C ′ ) N'×(d+C') N′×(d+C′)的矩阵,具有 N ′ N' N′个具有 d d d维坐标和 C ′ C' C′维特征的点,输出的 C ′ C' C′维特征被视为局部上下文的特征。
Sampling layer
给定点 { x 1 , x 2 , . . . , x n } \{x_1,x_2,...,x_n\} {x1,x2,...,xn},在上面迭代执行最远点采样FPS获得一组点的子集 { x i 1 , x i 2 , . . . , x i m } \{x_{i_1},x_{i_2},...,x_{i_m}\} {xi1,xi2,...,xim},这样 x i j x_{i_j} xij代表相对于其余点到集合 { x i 1 , x i 2 , . . . , x i j − 1 } \{x_{i_1},x_{i_2},...,x_{i_{j-1}}\} {xi1,xi2,...,xij−1}的最远点。与随机采样比较,这种采样方式能够在给定同样数量中心点centroids的时候更好地覆盖点集。这种采样策略依赖于数据来生成对应的感受野。
Grouping layer
输入的点集大小 N × ( d + C ) N×(d+C) N×(d+C),中心点centroids大小 N ′ × d N'×d N′×d。输出点集大小 N ′ × K × ( d + C ) N'×K×(d+C) N′×K×(d+C), K K K是中心点centroid points周围邻居点的数量,且 K K K是随着groups而变化的,但PointNet layer能够将任意数量的点转化成定长的局部区域特征向量。
除了进行可变化 K K K的采样,还可以进行固定大小的采样(kNN),固定邻居点的数量。但比起kNN,原始的ball query能够根据需要来调整neighborhood points采样的多少,从而使得局部特征更具泛化性,更有利于需要局部特征识别的任务(如语义点的标注)
PointNet layer
这一层的输入是局部区域的点,大小为 N ′ × K × ( d + C ) N'×K×(d+C) N′×K×(d+C),每一局部区域都是从其中心点centroid和局部特征中编码了centroid邻居的局部特征来提取的,这一层的输出是 N ′ × ( d + C ′ ) N'×(d+C') N′×(d+C′)。
坐标首先转移到一个现对于centroid point的local canonical space中: x i ( j ) = x i ( j ) − x ^ ( j ) x^{(j)}_i=x^{(j)}_i-\hat{x}^{(j)} xi(j)=xi(j)−x^(j),其中 i = 1 , 2 , . . . , K i=1,2,...,K i=1,2,...,K,且 j = 1 , 2 , . . . , d j=1,2,...,d j=1,2,...,d。其中 x ^ \hat{x} x^是centroid中心点的坐标。也就是以这个中心点采样的周围所有的邻居点,减去中心点,得到一个局部的位置。
然后运用PointNet来处理相对坐标和点特征以捕捉局部区域内点和点的关系。
5.3 非均匀采样密度下鲁棒的特征学习
这一节的提出是为了解决一个问题:使用密集数据学习的特征学习方法无法泛化到稀疏采样区域,反之亦然。
针对低密度区域点较少而无法精准地捕获局部细节问题,提出密度自适应PointNet层来保证在输入采样密度变化时,学习不同尺度区域特征。
PointNet++中提出了两种局部区域特征聚合的方法。
Multi-scale grouping(MSG)
这种方法就是在不同的尺度中聚集特征。不同尺度下的特征被连接构成了多尺度特征。
训练网络来学习连接多尺度特征的优化策略。这种策略的学习是通过随机以某个概率来丢弃输入示例中的点实现的,PointNet++将这种做法成为随机输入丢弃。对于输入点集,选择从 [ 0 , p ] , p < 1 [0,p],p<1 [0,p],p<1中随机采样的丢弃率 θ \theta θ,每个点以 θ \theta θ的概率丢弃。真正训练时候设置 θ = 0.95 \theta=0.95 θ=0.95以避免空点集,在测试时候不随机丢弃点,保留所有的点
Multi-resolution grouping(MRG)
MRG相较MSG的问题在于比较computationally expensive,因为在low level的时候点比较多,要对每个区域都执行PointNet,就会花费比较多的时间。
这里提出了一个替代的方法:每一个level L i L_i Li的特征由两个向量连接而成。一个向量由低一层的 L i − 1 L_{i-1} Li−1上执行set abstraction获得,另一个向量由直接使用单个PointNet来处理局部区域内的所有点获得。
当当前局部区域的密度很低的时候,第一个向量会比第二个向量更不可靠,因为更低一层的点可能会非常稀疏,suffers from采样不足的问题,在这种情况下,第二个向量应该被赋予更高的权重。另一方面,如果一个局部区域的密度很高,那么第一个向量提供了更丰富的信息,因为它是在更高的分辨率下求解的,被递归到第二个向量低分辨率中。
这种方法会更高效,避免了在低维度下neighborhood涵盖范围较大时特征提取耗时的问题。
5.4 用于集合分割的点特征传播
对于一些集合分割任务如给点打语义标签的任务,需要获得所有原始点的特征。一个可能的解法是将所有的点作为centroid points中心点,但是这会导致非常高的计算消耗。另外一个方法是从下采样的点集中将特征传播回原始点中。
基于插值采用分层传播策略。在特征传播层中,我们从 N l × ( d + C ) N_l×(d+C) Nl×(d+C)中将特征传播到 N l − 1 N_{l-1} Nl−1的点中,其中 N l ≤ N l − 1 N_l\le N_{l-1} Nl≤Nl−1。通过插值 N l N_l Nl的特征值 f f f,来获得 N l − 1 N_{l-1} Nl−1点的特征。
在众多的插值选择中,这里选择了基于k个最近邻区域的反距离加权平均,即:
f ( j ) ( x ) = ∑ i = 1 k w i ( x ) f i j ∑ i = 1 k w i ( x ) ,其中 w i ( x ) = 1 d ( x , x i ) p , j = 1 , . . . , C f^{(j)}(x)=\frac{\sum^k_{i=1}w_i(x)f^{j}_i}{\sum^{k}_{i=1}w_i(x)},其中w_i(x)=\frac{1}{d(x,x_i)^p},j=1,...,C f(j)(x)=∑i=1kwi(x)∑i=1kwi(x)fij,其中wi(x)=d(x,xi)p1,j=1,...,C
在 N l − 1 N_{l-1} Nl−1上的点的特征通过跳跃连接来concat,接着这些concat的特征通过unit pointnet。重复这些步骤知道特征传播到了原始点集。
6. 实验与总结
从实验结果上来看,PointNet++相较PointNet表现更加,此处不赘述。
总而言之,PointNet++能够处理采样不均的点集,同时相较PointNet而言,进一步考虑了local features,在一些3D点云处理的任务上获得了最好的结果。
7. 补充
最远点采样
参考 (九) 最远点采样(Farthest Point Sampling)基本原理 - 知乎 (zhihu.com)
最远点采样的目标:在保证图形的拓扑结构不变约束条件下(约束),用少量数据点来表示图像/点云图形 (目标)。通常采用最远点采样(Farthest Point Sampling)方法来求解上述优化问题。
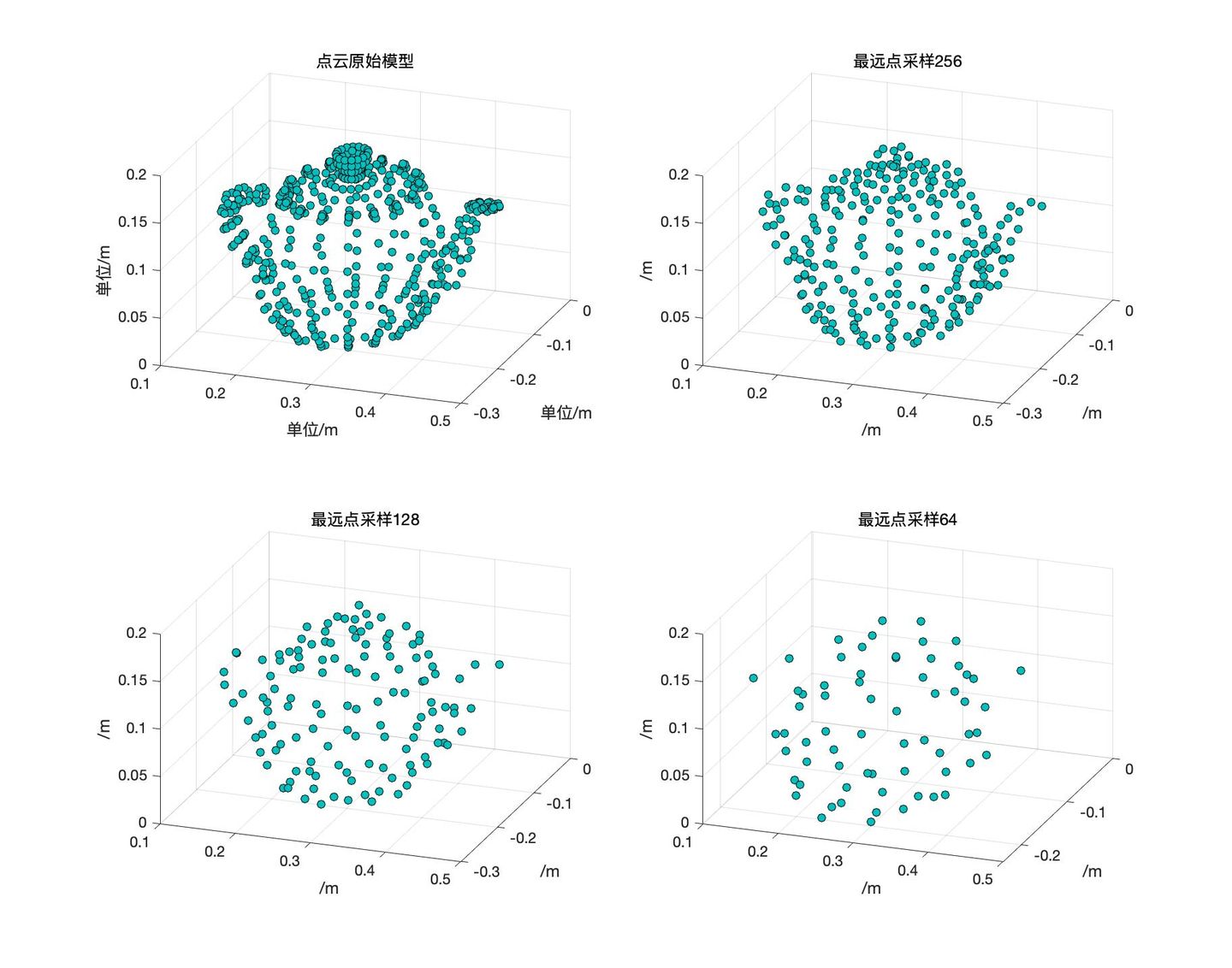
这个文章里说的可能还不够详细,实际上FPS的目标就是使得采样出来的点尽可能在空间上是均匀的,参考这两个链接来理解:
- 算法笔记 | 最远点采样 (FPS, Farthest Point Sampling) - 知乎 (zhihu.com)
- 3D点云专题—最远点采样(Farthest Point Sampling,FPS) - 哔哩哔哩 (bilibili.com)
















 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









