







引言
需求分析,技术可行性(目前的研究进度),主流怎么做?我要如何做?
随着互联网技术的飞速发展及联网的便捷,越来越多的人在网上表达自己的意见。其中,电影评论受到广泛关注。很多人选择在闲暇时间观看电影,选择哪一部电影则常常受到网上评论的影响。然而电影评论主观性较强,个体化倾向明显,单个评论不具备可参考性,因此需要对大量的影评进行综合性的情感分析。
情感分析是自然语言处理领域的一个重要分支。在社交媒体中,评论文本的数量呈指数级增长,必须采用智能处理方式。目前的情感分析主要是基于机器学习的方法,基于CNN(Convolutional Neural Network,卷积神经网络)、RNN(Recurrent Neural Network,循环神经网络)等神经网络的处理比传统的方法取得了更高的准确率。文本分析属于典型的时序数据处理问题,因此本文采用改进的RNN网络BiL-STM(Bidirectional Long-short Term Memory Network,双向长短时记忆网络)对电影评论进行情感分析。
模型介绍
LSTM及BiLSTM
指出RNN的缺陷:
RNN一般用来处理序列信息,在文本、语音、视频等具有上下文关联的应用场景中精度很高。其展开结构如图 1 所示。但是RNN会面临梯度消失和梯度爆炸的问题,这将导致长时依赖丢失。为解决这个问题,LSTM网络对RNN进行了改进。
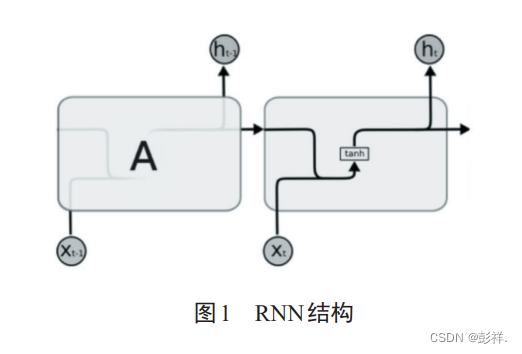
提出RNN变体LSTM
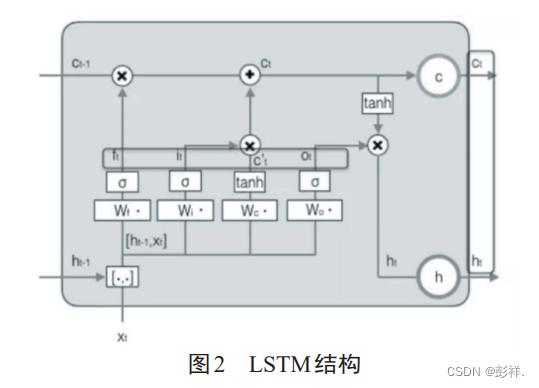
LSTM 由遗忘门、输入门和输出门三个控制门组成,如图2所示。遗忘门控制上一时刻的单元状态Ct-1有多少保留到当前状态Ct,输入门控制当前时刻的网络输入Xt有多少保存到单元状态Ct,输出门控制单元状态Ct有多少输出
到LSTM网络的当前输出ht。图2中σ表示sigmoid函数,其取值范围是[0-1],决定了门控制器能够通过信息的比例。sigmoid取值为1时,表示所有信息都能通过,完全保留这一分支的记忆,取值为0时,表示没有信息能够通过,即所有信息全部遗忘。LSTM网络的主要计算公式如下:
ft = σ ( wt ⋅[ ht - 1,xt] + bf ) (1)
it = σ ( wi ⋅[ ht - 1,xt] + bi) (2)
c’t = tanh( wc ⋅[ ht - 1,xt] + bc) (3)
ct = ft × ct - 1 + it × c’t (4)
ot = σ ( wo ⋅[ ht - 1,xt] + bo) (5)
ht = ot × tanh( ct) (6)
再次指出LSTM的缺陷,提出自己的想法:BiLSTM
从图2可以看到,LSTM网络只能利用前文信息。例如句子“我吃苹果”,处理分词“吃”时,LSTM只考虑前一个分词“我”,这显然是不够的,其后面的分词“苹果”对吃具有更重要的影响。双向LSTM应运而生,BiLSTM从两个方向同时读取文本,这样就可以充分利用当前时刻数据的所有上下文信息。
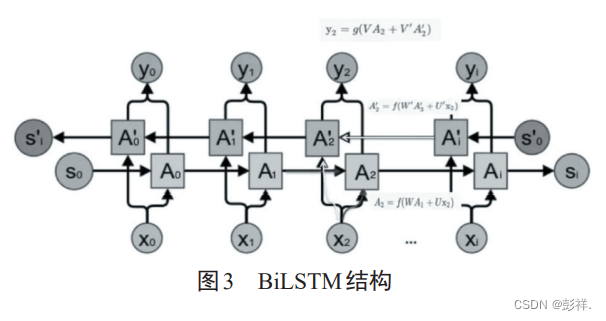
如图 3 所示 ,BiLSTM 构建了两个方向相反的LSTM层,正向计算时,t时刻的隐藏状态与t-1时刻有关,反向计算时,与t+1时刻有关,网络的最终隐藏状态向量由两个方向的隐藏状态组合生成。组合方式可拼接、加权求和或求平均。设X2为当前时刻的输入单元,A2为正向传播通道上该单元的隐藏状态,由前一时刻的隐藏状态 A1和当前输入 X2共同决定,A2'是反向传播通道上的隐藏状态,由下一时刻的隐藏状态A3'和X2共同决定,输出y2是A2和A2'加权和
的函数。
BiLSTM的实现方法非常简单[6]。**只需堆叠两层LSTM,其中一层将数据集原样输入,相当于按正向传递信息。另一层则将数据集翻转后输入,按反向传递信息。**例如处理数字序列“1、2、3、4”,正向传播层接收数据本身,反向传播层接收“4、3、2、1”,即可同时有效提取过去和未来的上下文信息。
Dropout机制
对于规模大、训练参数较多的神经网络来说,非常容易发生过拟合现象。过拟合是指模型在训练数据上损失函数小,预测准确率高,但是在测试数据上损失函数大,预测准确率低,也就是模型的泛化能力太差。最初解决过拟合问题的
方法是训练多个模型做组合,但这也带来了模型过于复杂和费时的问题。受此启发,Hinton 等人在 2012 年推出了 Standard Dropout 方法 ,之后 Dropout 又发展出了多个变种。Dropout是指在规模较大的神经网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,如图4所示。每轮迭代训练时,都按一定的概率抛弃不同的神经元,这就相当于在一个网络上同时训练了多个模型,提高了泛化能力,能够有效抑制过拟合。抛弃神经元的概率不宜过大,否则会造成重点特征丢失,一般设置在 0.3~0.5 之间。Dropout机制最初用在密集度较大的深度神经网络,但后来发现在卷积和循环神经网络中作用也很显著。

算法设计及实验结果
模型搭建
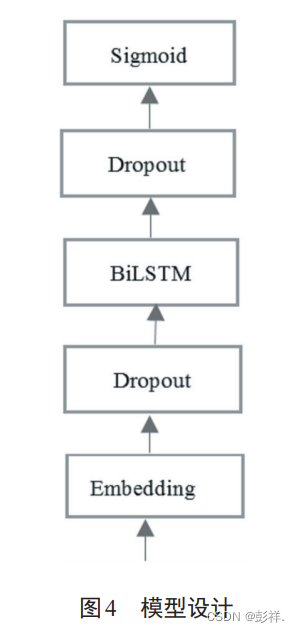
本实验的算法设计基于Keras平台实现,模型搭建如图4所示。首先是Embedding层,该层负责将文本数据转化为单词向量,为防止过拟合,其上叠加Dropout层,然后是BiLSTM层,也叠加Dropout,最后通过Sigmoid层进行情感分类。
数据集划分
本文采用IMDB电影评论数据集,该数据集包含5万条电影评论,一半划分为训练数据,一半划分为测试数据。每条数据根据正、负面倾向标注“positive”和“negative”。由于每条评论的单词数量不等,统一预处理为400个单词,即超过
400个单词进行截断,不足400的填零补足。字典大小设置为 4000。Embedding 层的输出设置为 36,即每个单词通过Embedding转化为36维的密集向量。模型中各参数设置如表1所示。
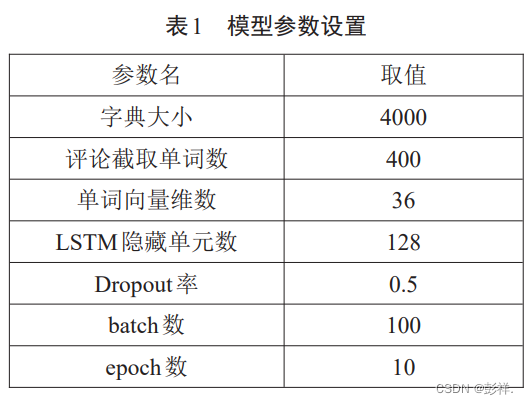
模型训练与对比实验
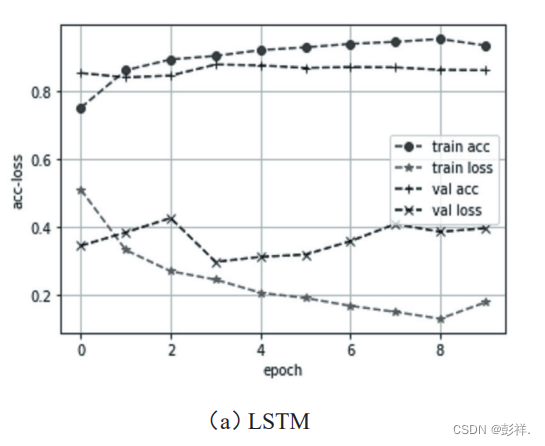
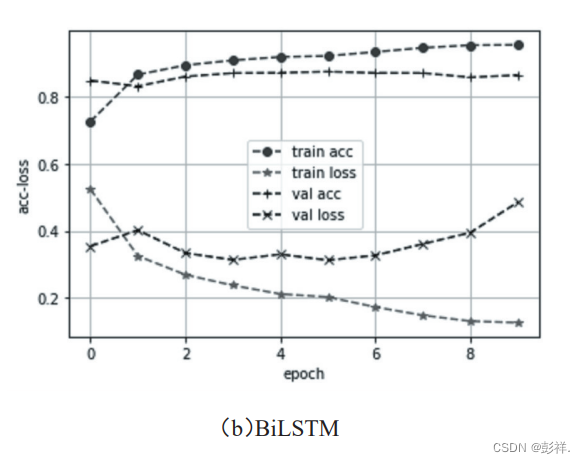
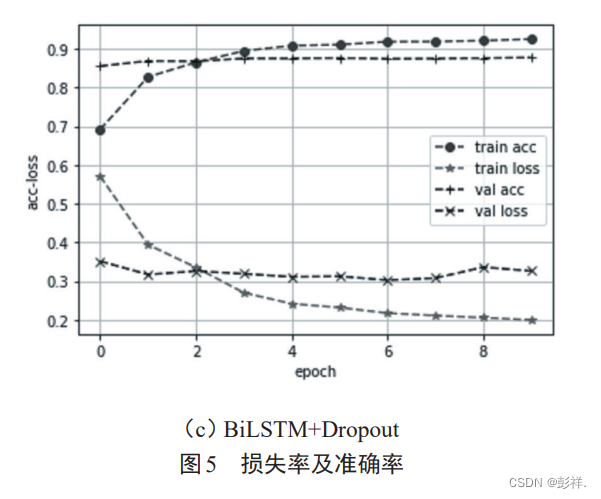
模型训练采用二进制交叉熵binary crossentropy作为损失函数,优化器选用Adam算法。为了对比,实验共进行了三次,第一次为上述模型 BiLSTM 加 Dropout,第二次仅使用BiLSTM,不采用 Dropout,第三次仅使用单向 LSTM。每个epoch 的损失率和准确率曲线如图 5 所示。最后一个 epoch
的具体数据如表 2 所示。另外,进行了基于单向LSTM 的 IMDB 数据集的分析实验并与其他算法进行了比较,如表3所示。从测试数据集的分析效果来看,本算法的BiLSTM加Dropout的效果是最好的。
结语
本文实验表明,BiLSTM 结合 Dropout 机制的算法在电影评论情感分析的应用中准确率很高。但来自各种网站的评论数据有表达不完善、不准确等复杂问题,本实验将进一步完善算法的先进性,提高分析准确率。IMDB数据集是较为标准的英文电影评论数据集,下一步工作可以分析中文数据集、在豆瓣等社交网络爬取数据,制作更加广泛和贴近真实的电影评论数据集,验证算法的实际应用效果。另外,本文也验证了BiLSTM处理时序数据的有效性,下一步工作也将探索该算法在复杂文本、语音、视频处理等领域的应用。


















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











