








本篇应该在模型训练模块讲解的,但在DETR中的多头注意力机制使用的是pytorch官方封装好的源码,因此就放到了这里。
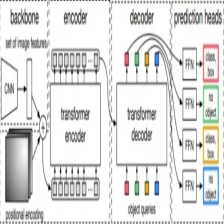
模型结构
首先,在学习该部分代码前我们需要将多头注意力的原理进行简单梳理。
由下图我们可以看到在encoder中是多头自注意力机制,而在decoder中,前面是多头自注意力,后面变成了多头注意力。

代码解析
获取backbone特征图
由于关于注意力的计算只在Transformer模型中,那么我们就不用再看backbone的执行过程了,只需要知道通过backbone后获取的信息即可:
送入backbone的samples为:torch.Size([2, 3, 608, 760])
features, pos = self.backbone(samples)
经过backbone转换后的特征图为:torch.Size([2, 2048, 19, 24]),注意其内还有掩码信息,其作用类似补全功能:padding,其维度为torch.Size([2, 19, 24])
位置编码信息为:torch.Size([2, 256, 19, 24])
随后需要将特征图信息与掩码信息分开:
src, mask = features[-1].decompose()#取-1是因为features保存了resnet每层的结果,取-1代表我只取最后一层的结果。
进入Transformer
hs = self.transformer(self.input_proj(src), mask, self.query_embed.weight, pos[-1])[0]
得到src即为输入transformer模型的特征图。当然在此之前还需要进行一个通道变换,将通道数由2048变为256。取【0】是只要第一个返回结果
随后便将其送入Transformer模型进行前向传播过程:
首先是一些维度转换与变量生成:
bs, c, h, w = src.shape
# 获取encoder输入
src = src.flatten(2).permute(2, 0, 1)#flatten先变为bs,c,h*w,随后通过perute变为h*w,bs,c
# 获取位置编码
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)#位置编码做相同变化
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)#unsequeeze表示再dim维度给加已维度
# 获取输入掩码
mask = mask.flatten(1)
src:torch.Size([456, 2, 256]) 456=19*24 这个意思是是将backbone输出特征图的像素展开成一维后当成了序列长度,而batch和channel的定义不变
pos_embed:torch.Size([456, 2, 256]) 456=19X24,256分别是128行编码与128列编码,这是设定好的。
query_embed:torch.Size([100, 2, 256]) ,其为decoder预测输入,即论文中反复提到的object queries,每帧预测num_queries个目标,这里预测100个。其最开始时是进行随机初始为0的,之后会加上位置编码信息。这个意思是想让query对位置较为敏感,或者说应该有自己所关注的范围,不能越界。因为encoder中好的特征就那么几个,一旦没有位置上的限定,其可能都会去学习那么几个特征,从而使多样性变差。
其中,num_queries是预定义的目标查询的个数,代码中默认为100。它的意义是:根据Encoder编码的特征,Decoder将100个查询转化成100个目标。通常100个查询已经足够了,很少有图像能包含超过100个目标(除非超密集的任务),相比之下,基于CNN的方法要预测的anchors数目动辄上万,计算代价实在是很大。
object queries在经过decoder的计算以后,会输出一个形状为TNE的数组,其中T是object queries的序列长度,即100,N是batch size,E是特征channel。
进入Encoder
根据送入的参数可知:encoder所需的只是特征图信息与位置编码信息等。
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
随后进入TransformerEncoderLayer,这里可以看到q,k的初始化:其为特征图信息加上位置编码信息作为初始化:
q = k = self.with_pos_embed(src, pos)
特征图+位置编码(经过先前的维度转换可以直接相加)
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
随后便是一个自注意力的计算了:
其传入q,k,vlaue即v,使用的是src,即backbone的特征图(没有进行位置编码,因为v只需要记住自己的特征信息即可,不需要位置编码)其返回结果有两个,一个是Attention的计算结果,即一个特征图,另一个是Attention的权重值,我们用不到,所以就使用【0】来只获取第一个即可。
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
pytorch中的注意力计算是通过forward中调用了F.multi_head_attention_forward进行计算,但是F.multi_headattentionforward的后端代码依然并非C++写好的融合算子(融合算子指的是将多个步骤合并在一起进行计算,而是由多个torch下的function组成。因此该段代码读起来有些晦涩难懂。
自注意力的代码实现
这里我们就不看pytorch封装的了,可以通过pytorch来自己实现:
from math import sqrt
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
dim_in: int
dim_k: int
dim_v: int
def __init__(self, dim_in, dim_k, dim_v):
super(SelfAttention, self).__init__()
self.dim_in = dim_in
self.dim_k = dim_k
self.dim_v = dim_v
self.linear_q = nn.Linear(dim_in, dim_k, bias=False) # Q、K的维度一致
self.linear_k = nn.Linear(dim_in, dim_k, bias=False)
self.linear_v = nn.Linear(dim_in, dim_v, bias=False)
self._norm_fact = 1 / sqrt(dim_k) # 为了规范Q@K的乘积的方差范围
def forward(self, x):
# x: (batch, n, dim_in) ——> (批量大小, 时序长度, 特征维度)
batch, n, dim_in = x.shape
assert dim_in == self.dim_in
q = self.linear_q(x) # batch, n, dim_k
k = self.linear_k(x) # batch, n, dim_k
v = self.linear_v(x) # batch, n, dim_v
dist = torch.bmm(q, k.transpose(1, 2)) * self._norm_fact # batch, n, n
dist = torch.softmax(dist, dim=-1) # batch, n, n
att = torch.bmm(dist, v)
return att
上述代码完成就是这个计算:

随后便是进行经过linear等操作即可,最终获得encoder的输出结果,这便是通过encoder提取到的特征,可以认为便是k,v
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
进入Decoder
前面的encoder的设计基本与先前的transformer没有什么不同,但decoder的设计上便有其自己的理解。
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
首先我们来看下其传入的参数
- tgt是一个学习的向量,可以认为是我们的要用来做预测的那100个预测框,在最开始时其初始化为0,随后经过学习会发生变化,是我们整个模型中最核心的要去学习的东西。
- memory即encoder提取到的特征信息,mask值用来告诉计算机哪些是被padding的向量,不需要计算。
- pos为位置编码信息
- query_pos即query的位置编码。
self.query_embed = nn.Embedding(num_queries, hidden_dim)也是通过编码进行初始化的。
DecoderLayer层计算
首先便是q,k的初始化了,即tgt(初始化为0)加上我们的query的位置编码
q = k = self.with_pos_embed(tgt, query_pos)
随后便是注意力的计算了,此时是自注意力。
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]#自注意力计算
根据传入的参数我们可以看出,这里的自注意力的q,k都是由decoder自己提供的,q,k实际上也只有位置编码信息罢了,tgt在第一次都是0,这也就说明在这里其是想学习位置特征。
注意是虽然方法名看似相同,但pytorch的实现是不同的。
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
进行残次连接归一化操作。
tgt = tgt + self.dropout1(tgt2)#残差连接
tgt = self.norm1(tgt)#层归一化
随后所得结果即学习了位置特征的tgt,随后会将其与encoder中的k,v来进行计算,使tgt能够得以学习。
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos), key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0]
根据此时传入的参数可知
query为tgt与位置编码的结合体 torch.Size([100, 2, 256])
key为encoder所学到的特征与位置编码的结合 torch.Size([456, 2, 256])
vlaue则为encoder的特征。torch.Size([456, 2, 256])
memory_mask与memory_key_padding_mask的值都为None,无用
此时的tgt经过计算也已经有值了。其shape为torch.Size([100, 2, 256])
memory的值永远是不会发生变化的,即其k,v的值不会变了,要学习的便是tgt。
最后我们将这个输出结果通过两个全连接层便可得出类别与预测框了。

















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











