






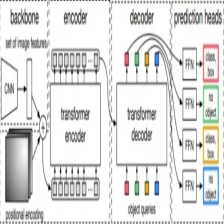
 文章展示了如何使用PyTorch实现DETR模型,该模型结合了ResNet-50的卷积层和Transformer架构,用于目标检测。代码简洁地构建了模型,并进行了推理操作,处理输入图像并输出类别和边界框。
文章展示了如何使用PyTorch实现DETR模型,该模型结合了ResNet-50的卷积层和Transformer架构,用于目标检测。代码简洁地构建了模型,并进行了推理操作,处理输入图像并输出类别和边界框。
DETR模型

Transformer模型

DETR简单实现
在DETR模型的论文的末尾,其给出了DETR模型的伪代码,严格意义上来讲其并非是伪代码,因为其是可以正常运行的代码。
我们先来看一下其源码:
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(source_image)
可以看出,代码非常简练,通过实验pytorch在封装的backbone,Transformer模型以及一些全连接层,卷积层的组合便实现了DETR模型的构造。
我们在上面源码的基础上修改,使其完成推理操作。
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
from PIL import Image
import numpy as np
from DETR_detect.tools.function import *
CLASSES = [
'car', 'truck', 'bus', 'person'
]
img_path= "../test.png"
image = Image.open(img_path)
source_image=image
source_image = np.expand_dims(np.array(source_image).transpose((2,0,1)),0)
source_image=torch.from_numpy((source_image)).float()
detr = DETR(num_classes=4, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
logits, bboxes = detr(source_image)
pre_class = logits.softmax(-1)[0, :, :-1].cpu()
bboxes_scaled = rescale_bboxes(bboxes[0,].cpu(), (source_image.shape[3], source_image.shape[2]))
score, pre_box = filter_boxes(pre_class, bboxes_scaled)
class_id = score.argmax()
label = CLASSES[class_id]
confidence = score.max()
text = f"{label} {confidence:.3f}"
print(text)

















 846
846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











