






使用LangGraph构建多代理系统
0.完整工作流
1.开发代码
环境变量
# open ai的相关环境变量
OPENAI_API_KEY=xxx
OPENAI_BASE_URL=https://api.openai-hk.com/v1
# LangSmith的环境变量,方便去LangSmith看执行过程
LANGCHAIN_TRACING_V2=xxx
LANGCHAIN_ENDPOINT=xxx
LANGCHAIN_API_KEY=xxx
LANGCHAIN_PROJECT=xxx
# 搜索用的
TAVILY_API_KEY=xxx 环境变量
构建通用的agent
# 导入基本消息类、用户消息类和工具消息类
from langchain_core.messages import (
HumanMessage
)
# 导入聊天提示模板和消息占位符
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# 定义一个函数,用于创建代理
def create_agent(llm, tools, system_message: str):
"""创建一个代理。"""
# 创建一个聊天提示模板
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个有帮助的AI助手,与其他助手合作。"
" 使用提供的工具来推进问题的回答。"
" 如果你不能完全回答,没关系,另一个拥有不同工具的助手"
" 会接着你的位置继续帮助。执行你能做的以取得进展。"
" 如果你或其他助手有最终答案或交付物,"
" 在你的回答前加上FINAL ANSWER,以便团队知道停止。"
" 你可以使用以下工具: {tool_names}。\n{system_message}",
), # 系统消息
# 消息占位符
MessagesPlaceholder(variable_name="messages"),
]
)
# 传递系统消息参数
prompt = prompt.partial(system_message=system_message)
# 传递工具名称参数
prompt = prompt.partial(tool_names=", ".join([tool.name for tool in tools]))
# 返回RunnableSequence,先用消息messages填充提示词,再llm_with_tools进行调用 (类型是:langchain_core.runnables.base.RunnableSequence)
return prompt | llm.bind_tools(tools)
构建通用的agent节点
# 辅助函数,用于为给定的代理创建节点
from langchain_core.messages import ToolMessage, AIMessage
"""
图的agent节点。决定做什么操作(也就是调用下llm)
1.把历史消息放入提示词,然后让llm回答。(此时的state里就有历史消息,也就是messages,而sender再字典里,也无关紧要,虽然传入进去了,但是底层没用)
2.返回消息和发送方
"""
def agent_node(state, agent, name):
# 调用代理
result = agent.invoke(state)
# 将代理输出转换为适合附加到全局状态的格式
if isinstance(result, ToolMessage):
pass
else:
# 先result.dict(exclude={"type", "name"}) 返回一个去除type和name的字典,然后通过**变成关键字参数,最后把name传进去
# 相当于曲线救国,把消息的name改成了。
result = AIMessage(**result.dict(exclude={"type", "name"}), name=name)
return {
"messages": [result], # 会追加到消息后边
# 由于我们有一个严格的工作流程,我们可以
# 跟踪发送者,以便知道下一个传递给谁。
"sender": name,
}
构建tool
# 导入注解类型
from typing import Annotated
# 导入Tavily搜索工具
from langchain_community.tools.tavily_search import TavilySearchResults
# 导入工具装饰器
from langchain_core.tools import tool
# 导入Python REPL工具
from langchain_experimental.utilities import PythonREPL
# 创建Tavily搜索工具实例,设置最大结果数为5
tavily_tool = TavilySearchResults(max_results=5)
# 警告:这会在本地执行代码,未沙箱化时可能不安全
# 创建Python REPL实例
repl = PythonREPL()
# 定义一个工具函数,用于执行Python代码
@tool
def python_repl(
code: Annotated[str, "要执行以生成图表的Python代码。并保存到本地plt.png。"],
):
"""使用这个工具来执行Python代码。如果你想查看某个值的输出,
应该使用print(...)。这个输出对用户可见。"""
try:
# 尝试执行代码
result = repl.run(code)
except BaseException as e:
# 捕捉异常并返回错误信息
return f"执行失败。错误: {repr(e)}"
# 返回执行结果
result_str = f"成功执行:\n```python\n{code}\n```\nStdout: {result}"
return (
result_str + "\n\n如果你已完成所有任务,请回复FINAL ANSWER。"
)
构建agent路由
from typing import Literal
# 定义路由器函数
def router(state) -> Literal["call_tool", "__end__", "other_agent"]:
# 这是路由器
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
# 上一个代理正在调用工具
return "call_tool"
if "FINAL ANSWER" in last_message.content: # 刚开始的提示词里指定了以FINAL ANSWER为结束标志
# 任何代理决定工作完成
return "__end__"
return "other_agent"
核心代码
from dotenv import load_dotenv
# 先加载环境变量,默认是找当前目录下的.env文件
load_dotenv()
# 导入操作符和类型注解
import functools
import operator
from typing import Annotated, Sequence, TypedDict
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph
from build_agent import create_agent
from build_tool import tavily_tool, python_repl
from build_agent_node import agent_node
from build_router import router
from langgraph.prebuilt import ToolNode
from langgraph.graph import END, START
# 定义一个对象,用于在图的每个节点之间传递
# 我们将为每个代理和工具创建不同的节点
class AgentState(TypedDict):
# 添加operator.add注解,相当于每次把消息列表加起来。变相的追加而已。
messages: Annotated[Sequence[BaseMessage], operator.add]
sender: str
# 创建OpenAI聊天模型实例
llm = ChatOpenAI(model="gpt-4o-mini")
# 查询的agent,用的时候给他送入消息就行
research_agent = create_agent(
llm,
[tavily_tool],
system_message="你应该提供准确的数据供chart_generator使用。",
)
# 创建查询节点,指定对应的agent functools.partial是会生成一个函数,函数为agent_node,指定参数agent和name
research_node = functools.partial(agent_node, agent=research_agent, name="Researcher")
# 图表生成的agent
chart_agent = create_agent(
llm,
[python_repl],
system_message="你展示的任何图表都将对用户可见。",
)
# 创建图表生成节点,指定对应的agent
chart_node = functools.partial(agent_node, agent=chart_agent, name="chart_generator")
# 定义工具列表
tools = [tavily_tool, python_repl]
# 创建工具节点
tool_node = ToolNode(tools)
# -------------创建图---------------
# 创建状态图实例
workflow = StateGraph(AgentState)
# 添加搜索节点
workflow.add_node("Researcher", research_node)
# 添加图表生成器节点
workflow.add_node("chart_generator", chart_node)
# 添加工具调用节点
workflow.add_node("call_tool", tool_node)
# 添加起始边
workflow.add_edge(START, "Researcher")
# 添加条件边 (三种情况,结束,调用工具,调用其他代理)
workflow.add_conditional_edges(
"Researcher",
router,
{"other_agent": "chart_generator", "call_tool": "call_tool", "__end__": END},
)
workflow.add_conditional_edges(
"chart_generator",
router,
{"other_agent": "Researcher", "call_tool": "call_tool", "__end__": END},
)
# 添加条件边,工具调用结束后,需要返回到哪里。
workflow.add_conditional_edges(
source="call_tool",
# 每个代理节点更新'sender'字段
# 工具调用节点不更新,这意味着
# 该边将路由回调用工具的原始代理
path=lambda x: x["sender"], # 发送方是谁,就返回到哪里
path_map={ # 根据path进行路由,防止sender和具体的节点名字不一样的情况
"Researcher": "Researcher",
"chart_generator": "chart_generator",
},
)
# 编译工作流图
graph = workflow.compile()
# 将生成的图片保存到文件
graph_png = graph.get_graph().draw_mermaid_png()
with open("build_graph.png", "wb") as f:
f.write(graph_png)
# 事件流
events = graph.stream(
{
"messages": [
HumanMessage(
content="获取过去5年AI软件市场规模,"
" 然后绘制一条折线图。"
" 一旦你编写好代码,完成任务。"
)
],
},
# 图中最多执行的步骤数
{"recursion_limit": 150},
)
# 打印事件流中的每个状态
for s in events:
print(s)
print("----")
2.LangGraph执行图
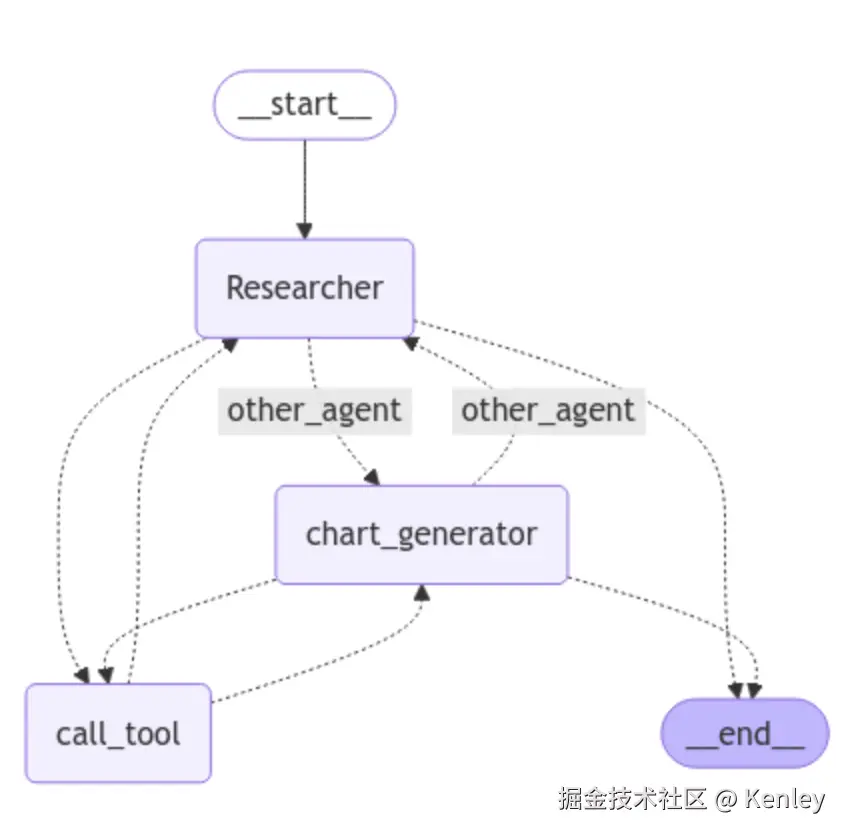
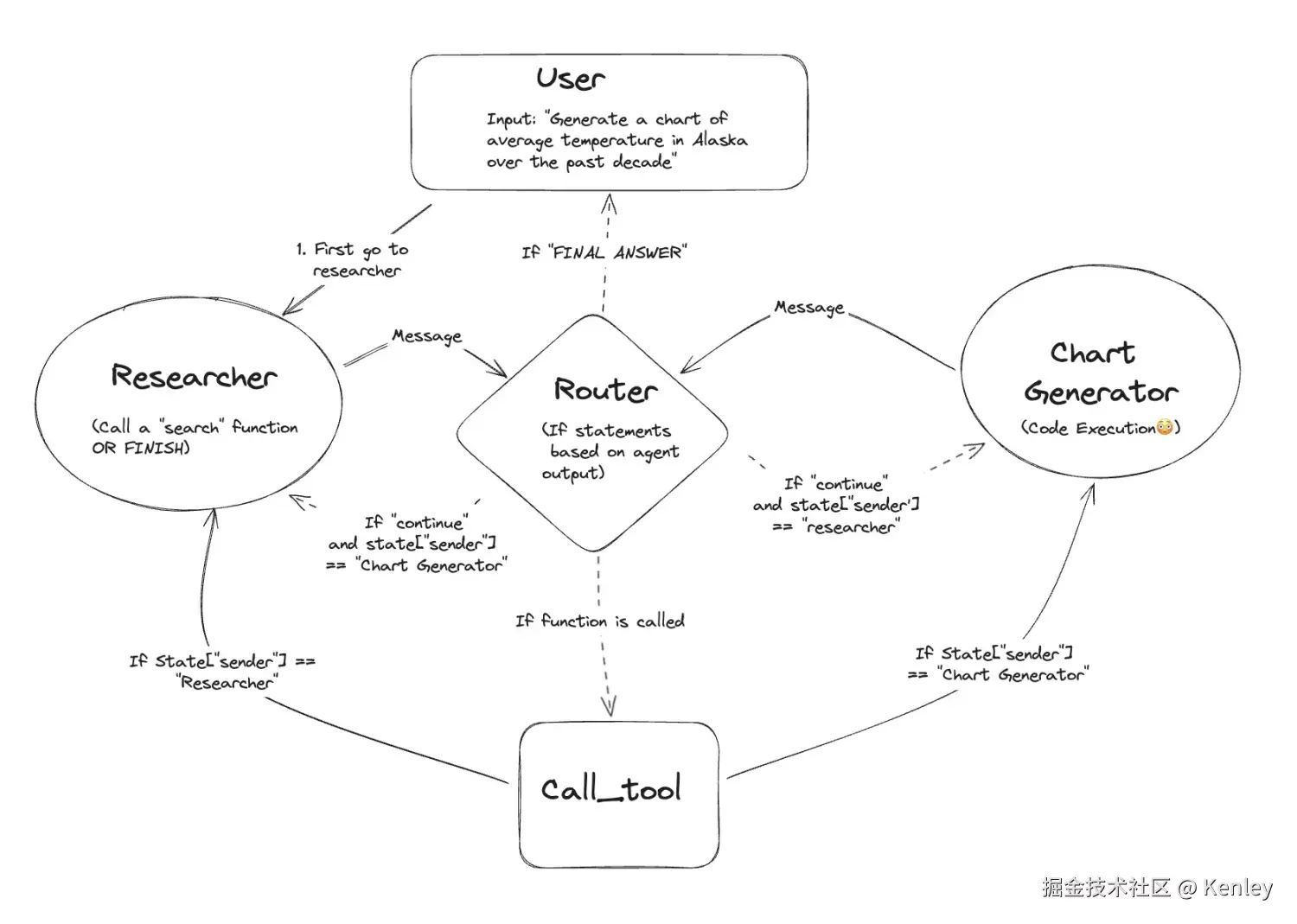
- 1)开始先到检索的agent,调用大模型,根据结果看需要走哪个分支(调用工具、调用其他agent、直接结束)
- 2)如果是到调用工具,则调用检索的工具,进行检索,然后把结果返回给检索的agent,这里是原路返回
- 3)到了检索的agent,再次调用大模型,根据结果看需要走哪个分支
- 4)如果是到图表生成的agent,进入agent后,调用大模型,根据结果看需要走哪个分支
- 5)如果是调用工具,则调用生成图表的工具,生成最后的图表,然后把结果原路返回给对应的agent
- 6)agent收到结果后,再次调用大模型,通过大模型的结果进行判断,如果完成任务了则直接结束。
- 7)综上,调用结束,其中至少调用四次大模型。
3.LangSmith执行图
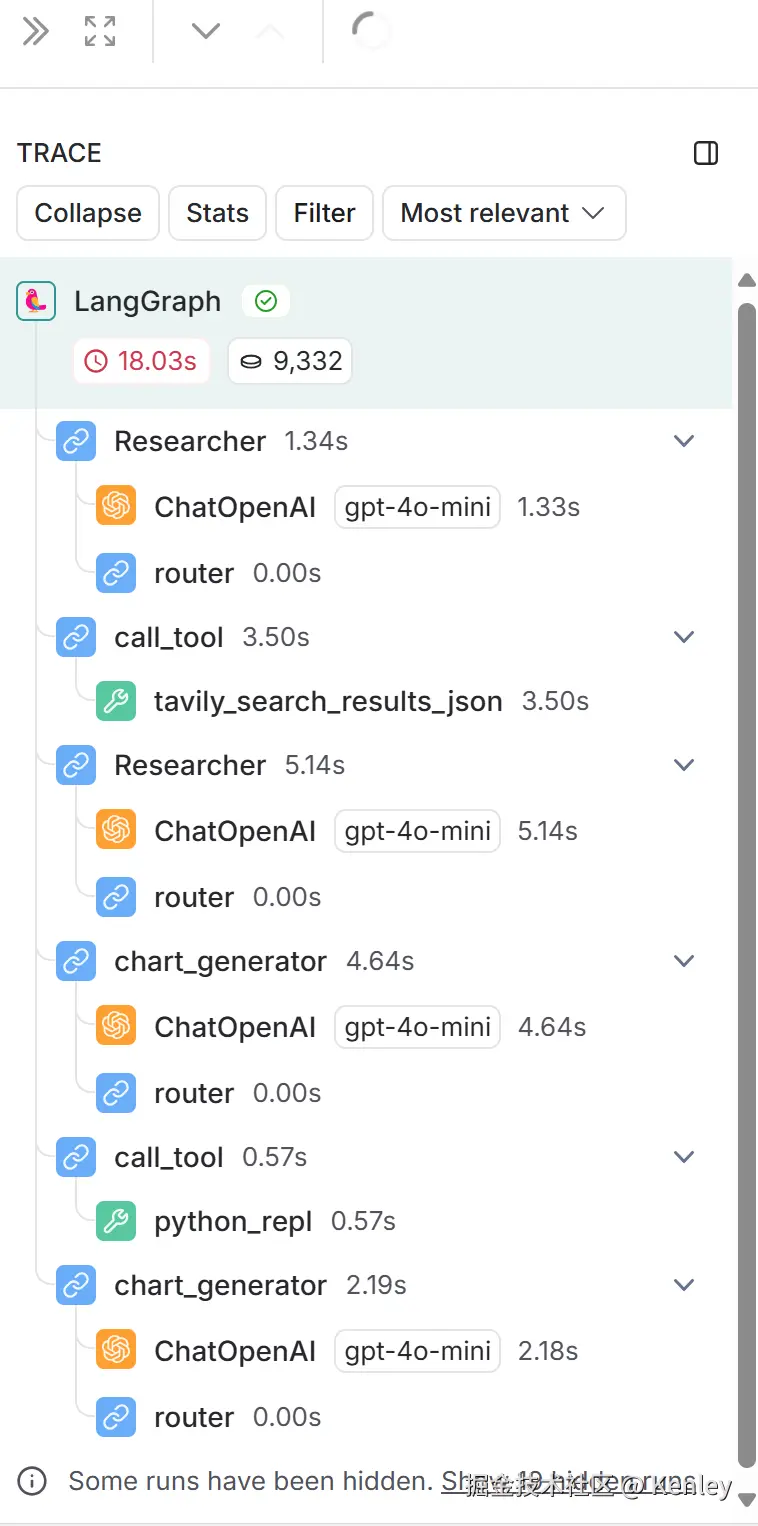
NOTE:和LangGraph执行图对应着看。以及注意自己环境的matplotlib的版本,可能和llm生成的代码版本不一致,导致运行报错。
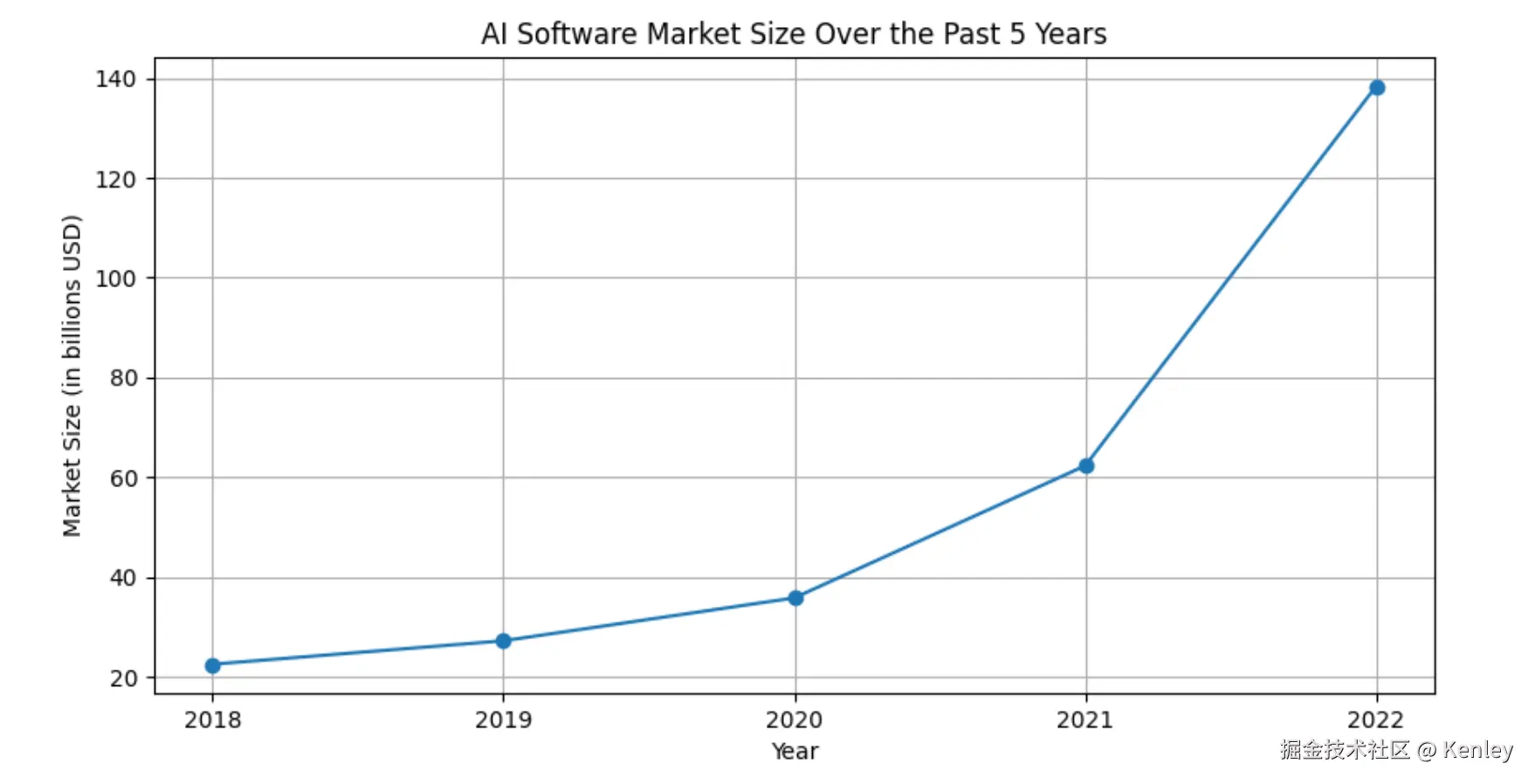
4.最终执行结果
让Agent系统获取过去5年AI软件市场规模,然后绘制一条折线图的结果如下图所示, 整体表现为自己查询数据,自己生成代码,自己展示并保存结果图片。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









