






引言
大模型(LLM)主要依赖于分词器(Tokenizer )将文本转换为Tokens,目前主流开源大模型基本上都是基于英文数据集训练得到的,然而,此类模型当处理其它语言时效率会降低。为此,为了能够将原始 LM 分词器替换为任意分词器,而不会降低性能,本文作者定义了一个新挑战:零样本分词器迁移(ZeTT,Zero-Shot Tokenizer Transfer),训练了一个适配各种模型的超网络(Hypernetwork),解耦LLM分词器(Tokenizer),增强LLM跨语言处理性,实验表明:在跨语言和编码任务上可媲美原始模型。
https://arxiv.org/pdf/2405.07883
背景介绍
语言模型(LM)通常依赖于分词器将文本映射为token序列。针对不同任务场景,大多数LM都会用到子词级、字节级、字符级等分词器。此类模型有一个共同的问题,那就是一旦用特定的分词器训练,便无法用不同的分词器进行推理。
由于当前主流大模型预训练时基本上主要关注英语,当面对其它语言或领域(如代码)时,分词器的编码效率就会较低,导致推理成本在英语和非英语文本之间差异巨大。此外,分词器在未涉及领域中的表现也不佳,例如Llama模型在编码任务中的表现不尽如人意。为了解决这些问题,先前的方法主要是通过重新训练嵌入参数(有时还包括整个LLM模型)来为LM配备新的分词器。这种适应可以通过启发式初始化嵌入参数来加快。
为此,本文作者提出了这样一个问题:能否在不观察任何数据的情况下,为任意分词器动态创建嵌入矩阵?并将该挑战定义为:零样本分词器转换(ZeTT)。如果模型性能能够大致保持,ZeTT实际上可以将LM与其训练时使用的分词器分离开来。
针对这一挑战,作者首先评估了以往基于启发式方法在ZeTT中的效果,发现尽管启发式方法在某种程度上能保持性能,但与原始LM性能之间通常存在较大差距。为了缩小现有语言模型(LMs)在零样本分词器迁移(ZeTT)上的差距,文章训练一个超网络(hypernetwork),该网络能够针对多样化分布的分词器预测嵌入参数,旨在实现有效的ZeTT。
Hypernetwork
超网络(Hypernetwork)的核心思想是训练一个单独的网络,它能够为任何给定的分词器动态生成嵌入参数,从而让语言模型能够适应不同的分词策略而无需重新训练整个模型。该网络的输入输出结构如下图所示:

其中:
超网络的输入主要包括新的分词器词汇表
Vb
和分词函数
Tb
,输出为
ϕinb
和
ϕoutb
,他们分表代表输入嵌入参数和输出嵌入参数,这些参数用于更新语言模型以适应新的分词器。
具体Hypernetwork网络架构如下图所示。它主要包括:分词器嵌入生成、Transformer处理、嵌入参数生成。
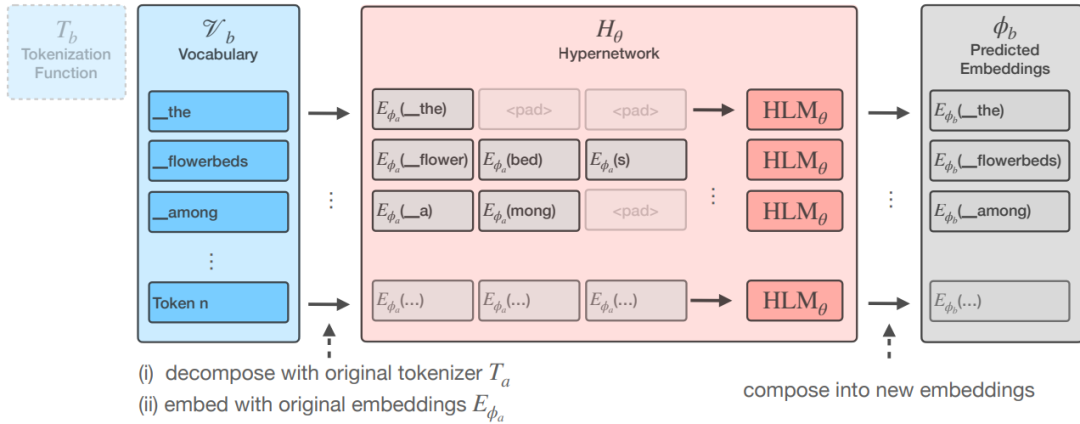
「分词器嵌入生成」 该过程主要包括分词和嵌入生成,其中分词主要是将新的分词器词汇表中的每个词
tb
通过原始分词函数
Ta
进行分解。例如,假设原始分词器会将“编程”分解为“编”和“程”,这两部分将被用来生成嵌入;嵌入生成主要是使用原始语言模型中的嵌入矩阵
Eϕa
对分解后的词序列进行嵌入。这些嵌入表示作为超网络的初始输入数据。
「Transformer处理」 超网络包含多个Transformer层,这些层能够捕捉序列中的上下文信息,从而生成更准确的嵌入参数预测。Transformer层通过自注意力机制处理输入嵌入序列,生成新的特征表示。
「新嵌入参数生成」 经过Transformer层处理后的特征表示,将被用于生成新的输入嵌入参数
ϕinb
和输出嵌入参数
ϕoutb
。这些新生成的嵌入参数用于更新语言模型,以适应新的分词器。
「网络训练设计」 主要损失函数的目标是最小化语言模型在新的分词器和超网络预测的嵌入参数上的损失,表示为:
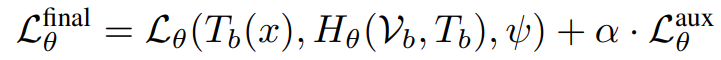
为了减少新嵌入参数与原始嵌入参数之间的差异,辅助损失函数用于惩罚预测的嵌入参数漂移,确保其尽可能与原始参数一致。
「训练过程」 首先初始化超网络参数
θinit
,从语料库中随机抽取文本样本,计算所有可能的子字符串及其在文本中的频率,并进行归一化处理。根据子字符串的频率和噪声参数,为子字符串分配分数,并选出前
k
个子字符串构成新的词汇表
Vb
。
然后,使用新的词汇表
Vb
构建新的分词器模型
Tb
。最后,对当前批次的文本进行分词,并通过超网络预测嵌入参数,计算语言模型在新的分词器和预测嵌入参数下的损失,并使用梯度下降法更新超网络参数
θ
,以最小化损失。
实验结果
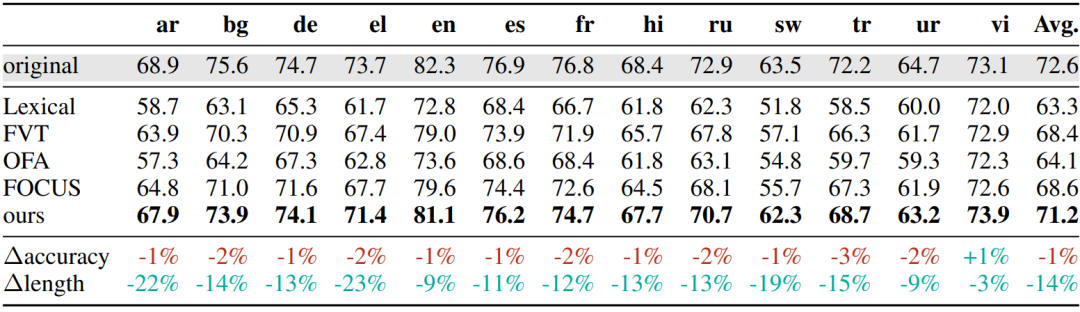
下表展示了**「XLM-R 分词器迁移结果」**,可以看到在所有基准上一致优于所有基线,平均准确度保持在原始模型的 1% 以内,最差情况下下降 3%,最佳情况下提高 1%,同时序列长度平均缩短了 14%。
下表展示了**「Mistral-7B 分词器迁移结果」**,可见对于 Mistral-7B,零样本迁移更具挑战性,但相比其它,Hypernetwork缩小了与原有分词器的差距。然而,使用目标分词器继续训练超网络可以几乎完全缩小差距。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









