







文章目录
前言
具有区域的多模态大模型,除了整体图像理解之外,Groma 还擅长区域级任务,例如区域描述和视觉grounding。 此类功能建立在本地化视觉标记化机制的基础上,其中图像输入被分解为感兴趣的区域,然后编码为区域标记。 通过将区域标记集成到用户指令和模型响应中,我们无缝地使 Groma 能够理解用户指定的区域输入并将其文本输出转化为图像。 此外,为了增强 Groma 的接地聊天能力,我们利用强大的 GPT-4V 和视觉提示技术,策划了一个视觉 grounded的指令数据集。 与依赖语言模型或外部模块进行定位的 MLLM 相比,Groma 在标准引用和 grounded 基准测试中始终表现出优越的性能,凸显了将本地化嵌入到图像标记化中的优势。
一、摘要
除了整体图像理解之外,Groma 还擅长区域级任务,例如区域描述和视觉grounding。 此类功能建立在本地化视觉标记化机制的基础上,其中图像输入被分解为感兴趣的区域,然后编码为区域标记。 通过将区域标记集成到用户指令和模型响应中,我们无缝地使 Groma 能够理解用户指定的区域输入并将其文本输出转化为图像。 此外,为了增强 Groma 的接地聊天能力,我们利用强大的 GPT-4V 和视觉提示技术,策划了一个视觉 grounded的指令数据集。 与依赖语言模型或外部模块进行定位的 MLLM 相比,Groma 在标准引用和 grounded 基准测试中始终表现出优越的性能,凸显了将本地化嵌入到图像标记化中的优势。


二、引言
多模态大型语言模型(MLLMs)已经将人工智能的火花从语言领域拓展到了视觉领域。归功大型语言模型(LLMs)的foundation能力,MLLMs精准视觉语言任务理解,这些任务需要高级理解和复杂推理能力(如图像描述和视觉问答)。尽管取得了这些成就,而当前的MLLMs通常在定位能力存在不足,无法将理解定位区域的视觉内容。这种局限性限制了模型在机器人技术、自动驾驶和增强现实等实际应用中的潜力。
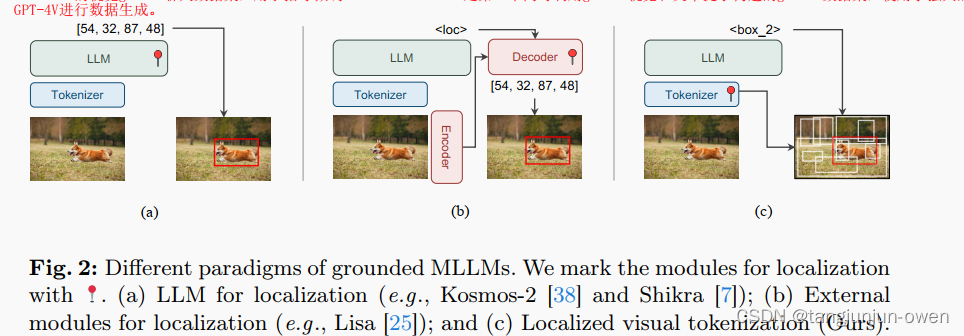
鉴于存在的差距,一些研究方向试图增强LLM以直接输出目标坐标用于定位(如图2a)。虽然这种方法设计简单,但LLMs需要用高分辨率图像输入满足定位,这对于准确的定位至关重要。此外,LLMs中序列输出的属性不适合密集预测任务如分割。这些问题引发了另一个研究方向,即合并外部模块(如SAM)取解码边界框box或掩码mask(如图2a)。这种方法避开了上述问题,但在推理中引入了额外的延迟,因为它需要分别处理MLLM和定位模块的图像输入。
上述情况促使我们探索了一种新的基于实地的MLLM范式。受到开放词汇对象检测的启发,我们将基于实地的任务分解为两个子问题:发现对象(定位)和将对象与文本相关联(识别)。我们注意到,仅定位需要很少的语义理解,但需要感知技能,这通常超出了LLM的专业范围。这启发我们在MLLM中解耦定位和识别。但是,我们不是使用外部模块,而是提出利用MLLM的视觉tokenizer的空间理解能力去进行定位(如图2c)。这种先感知后理解的设计也类似于人类视觉过程。
与先前为定位而增强LLMs的方法相比,Groma绕过了LLMs处理高分辨率输入时的大量计算,将处理高分辨率输入的定位装维图像tokenization的过程。也就是说,Groma可以使用高分辨率图像作为标记器输入,并使用下采样的图像token作为LLM输入,这样既节省了计算量,又不损失定位准确性。此外,与采用分别设计模型定位输出和推理输入的方法不同,Groma通过使用区域tokens无缝统一了这两种能力。
从数据角度来看,为了提高Groma的定位理解能力,我们采用了一系列具有区域级别注释的数据集进行训练,这些数据集涵盖了目标和目标与区域详细描述的一系列区域描述(就是目标区域描述和目标区域与其它区域关系描述)。此外,为了弥补缺乏长格式box数据,我们构建了一个名为Groma Instruct的视觉ground聊天数据集,用于指导微调。Groma Instruct是第一个同时利用ground视觉和文本提示构建的ground数据集,使用了强大的GPT-4V进行数据生成。
我们的全面实验证明了Groma设计的优越性,结果显示它在已建立的参考和接地基准测试上优于所有可比较的MLLMs。我们还展示了Groma在会话式VQA基准测试中保持了强大的图像级理解和推理能力。此外,为了评估定位多个、多样化和大小不一的对象的能力,我们将LVIS检测基准测试用于对象定位评估。在这个具有挑战性的基准测试中,Groma大幅超越了替代方法(超过10%的AR),突显了其稳健且精确的定位能力。
三、相关文献
1、Image-level MLLMs
图像级多模态大模型包含三个部分视觉编码、视觉与语言连接、大语言模型三个结构,有说了BLIP-2\LLaVA\MiniGPT4等代表文章。
2、Region-level MLLMs
区域级的多模态,要门直接将box转为location tokens或位置表征,也有人使用spatial-aware方法,也有人直接使用现有模型结合定位方式。
四、模型方法
在本节中,我们介绍了Groma,这是一个基于实地的多模态大型语言模型,能够理解用户定义的区域输入并生成视觉ground的输出。首先,我们在第3.1节中详细介绍了Groma的模型架构。然后,在第3.2节中,我们介绍了如何格式化区域输入和输出。最后,在第3.3节中,我们详细学习pipelines。
1、模型架构
正如图3所示,Groma主要包括:(1)用于场景级图像tokenization的图像编码器,(2)用于发现感兴趣区域的区域proposer,(3)用于区域级图像tokenization的区域编码器,以及(4)用于建模多模态输入和输出的大型语言模型。我们将在接下来的段落中详细介绍每个组件。
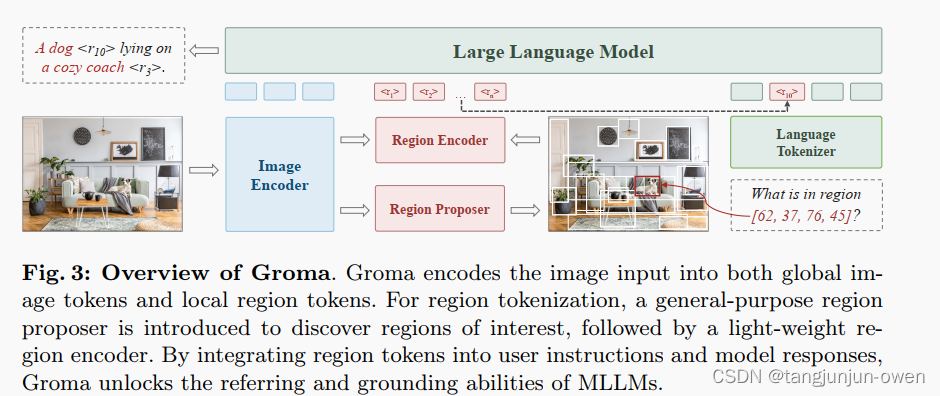
2、Image Encoder
视觉编码采用DINOv2更适合区域定位,而没采用通用CLIP作为视觉编码。尺寸采用448*448,对于大尺寸会造成更多的tokens。我们也使用MiniGPT-v2方法合并了tokens,并使用1d替代2d方法。
3、Region Proposer
为了获取图像的定位理解,Groma创新地将区域proposer纳入图像标tokenization过程中。具体来说,区域proposer使用一个二分类检测头实现,采用Deformable DETR(DDETR)变换器。DDETR的原始分类头被替换为一个二元分类器去基于它们提取定位框给出类别score。受ViTDet的启发,我们从图像编码器的最后4层中提取特征图,并重新调整这些特征图以构建分层特征金字塔,作为区域提提取的输入。对于每个图像,区域提议器生成300个区域box,然后通过NMS和目标score进行过滤,然后再输入到区域编码器中。
4、Region Encoder.
区域编码器将来自用户输入和区域提议器的区域提议(即边界框)转换为区域tokens。类似于前一步骤,我们从图像编码器的最后三层中选择特征图来创建分层特征金字塔。使用在[42, 63]中实现的多尺度ROIAlign [15]模块来裁剪和融合这些分层特征,形成统一的区域tokens。与其他表示区域输入的替代方式相比,例如位置的数值表示[7]和离散的位置tokens[6,38],区域token表示提供了明显的优势,因为它在语义上与底层区域对齐,使语言模型更容易理解。
重点说明:图像中获得的token比数字转换token更有利于语义理解
5、LLM
语言模型没有什么说的了,直接使用Vicuna模型
6、Input and Output Formatting
在tokenization过程中,每个区域token本质上都与图像中的一个具体位置相对应,对应其区域proposal。这种连接使语言模型通过简单地引用关联的区域token来将其文本输出与图像中的特定区域关联起来。然而,由于区域标记是连续嵌入,它们不能直接集成到语言模型的代码库中并在文本输出中引用。为了弥合这一差距,我们进一步引入了一组代理标记“,,…,”来注册区域标记。如下所示,Groma可以通过寻址代理标记来引用输出中的任何区域。
7、Referring Input
对于用户指定的区域,我们将其视为来自区域proposer提取区域,即将其编码为区域token并分配一个token标记。这使我们能够通过插入相应的区域token将用户指定的区域纳入我们的指令中。下面是Groma中引用对话的一个简单示例,其中来自用户指定的区域输入。
五、Model Training
训练模型分为三个阶段:
1、检测预训练给出定位能力
2、校准预训练为了图像级别与区域级别的视觉语言校准
3、指令调优为了增强对话能力
这里我只简述后2个阶段内容,第一阶段就是类似目标检测方法
1、Alignment Pretraining
为了使Groma的视觉和语言特征空间对齐,我们对模型进行了广泛的视觉-语言任务预训练。具体来说,对于图像级别的对齐,我们利用了ShareGPT-4V-PT [8]来进行详细的图像字幕生成。对于区域级别的对齐,我们利用了COCO [29]、RefCOCO [20]、RefCOCO+ [58]、RefCOCOg [34] 和Grit-20m [38]来进行引用表达理解(REC),利用Visual Genome [23]进行区域字幕生成,并利用Flickr30k Entities [40]进行基于图像的字幕生成。为了保持训练效率,我们将重点放在MLP投影层和区域编码器的微调上,而其他模块在整个训练过程中保持冻结状态。
2、Instruction Finetuning
基于对齐预训练,我们优化了训练数据,专注于高质量的数据集,并解冻语言模型以进行微调。在这个阶段,LLaVA Instruct [32] 和 ShareGPT-4V [8] 被整合进来,以提高Groma3的对话和指令跟随能力。此外,我们策划了一个高质量的基于对话的数据集,名为Groma Instruct(更多细节请参见下一节),以促进Groma的对话和基于地面的聊天能力的协同作用。
总结
本篇文章结合目标检测方式于多模态大模型中,给出语义token方式,该方式比直接数字的token更友好。
















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











