







01引言
深度学习 Transformer 自注意力机制中的掩码(Mask)是一种关键技术,用于控制模型在处理序列数据时哪些位置的信息可以被相互关注。掩码在不同的上下文中有不同的应用,但总体目的是防止在处理序列的当前位置时“泄露”未来位置的信息或者忽略无关的位置。
02理解
常见的掩码类型:
1. 遮蔽未来的信息(Look-ahead Mask):
在自回归任务中,如语言模型或机器翻译,每个输出应该仅依赖于它之前的输出。因此,需要一个掩码来确保在计算当前输出时忽略所有未来的位置。
这种掩码通常是一个上三角矩阵,其中对角线及以下的元素为 True(表示掩蔽),对角线以上的元素为 False(表示不掩蔽)。
2. 填充掩码(Padding Mask):
在处理变长序列时,通常需要将序列填充到相同的长度。填充的位置对于模型来说是无关的,因此需要一个掩码来告诉模型忽略这些位置。
这种掩码通常基于一个二进制矩阵,其中填充位置为 True(表示掩蔽),非填充位置为 False。
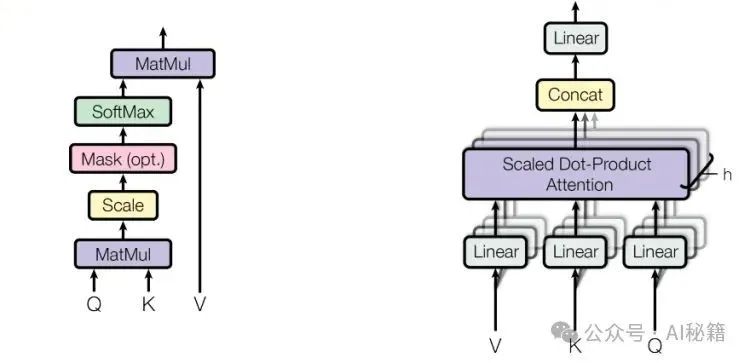
自注意力机制中的掩码应用:
在自注意力层中,掩码用于修改注意力分数,使得被掩码的位置的权重为零(或接近零),从而在计算注意力加权平均时忽略这些位置。具体步骤如下:
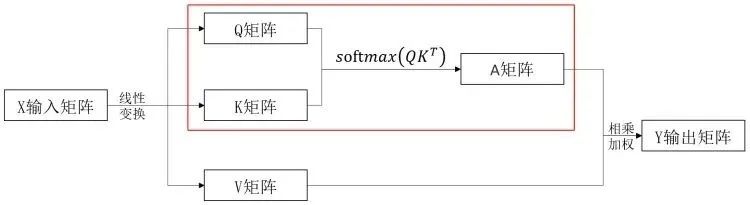
1. 计算注意力分数:
通常通过计算查询(Query)、键(Key)之间的点积,然后除以缩放因子(通常是键向量的维度的平方根)。
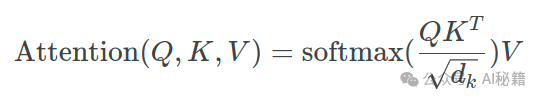
2. 应用掩码:
将掩码与注意力分数相乘。对于填充掩码,可以直接将 True 位置的分数设置为一个非常小的负数(如 -1e9),这样在应用 softmax 函数时,这些位置的权重将接近于零。
对于遮蔽未来的信息的掩码,同样可以将被掩码位置的分数设置为一个非常小的负数。
3. 计算注意力权重:
使用 softmax 函数对修改后的注意力分数进行归一化,得到注意力权重。
4. 计算加权平均:
使用注意力权重对值(Value)向量进行加权平均,得到最终的输出。

5. 例子

在代码段中,return subsequent_mask == 0 这个表达式用于生成一个布尔类型的张量,指定了哪些位置应该被掩蔽。
解释
subsequent_mask 是一个通过 torch.triu 创建的上三角矩阵,其中对角线和对角线以上的元素被设置为 1(因为 torch.triu 默认创建一个上三角矩阵,其中对角线及以上位置为 True,以下为 False)。在调用 .type(torch.uint8) 后,这些值被转换为 1(真)和 0(假)。
当执行 subsequent_mask == 0 时,此操作会逐一检查 subsequent_mask 中的每个元素是否等于 0:
- 如果元素值为 0(即原来是 False),则表达式结果为 True。
- 如果元素值为 1(即原来是 True),则表达式结果为 False。
因此,返回的张量将具有以下特性:
- 对角线及以下的元素(原始掩码中的值为0的地方)在返回的张量中会变为 True,表示这些位置应该被掩蔽(即在注意力计算中忽略这些位置)。
- 对角线以上的元素(原始掩码中的值为1的地方)在返回的张量中会变为 False,表示不需要掩蔽这些位置。
例子
假设 size=3,则 subsequent_mask 为:
1 1 1
0 1 1
0 0 1
经过 subsequent_mask == 0 操作后,得到的张量为:
False False False
True False False
True True False
03代码
假设有一个简单的自注意力计算:
import torch
import torch.nn.functional as F
query = torch.tensor([[1, 2], [3, 4]], dtype=torch.float32)
key = torch.tensor([[5, 6], [7, 8]], dtype=torch.float32)
value = torch.tensor([[9, 10], [11, 12]], dtype=torch.float32)
# 计算点积
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(query.size(-1))
# 创建一个遮蔽未来的掩码
mask = torch.triu(torch.ones_like(scores), diagonal=1) == 0
# 应用掩码
scores = scores.masked_fill(mask, float('-inf'))
# 计算注意力权重
attention = F.softmax(scores, dim=-1)
# 计算加权平均
output = torch.matmul(attention, value)
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1842
1842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









