






引言
上周给大家介绍了另一种基于LORA的高效微调ChatGLM-6B模型的方法。本周分享一下另一种高效的微调方法——P-Tuning v2方法,同时在文章的最后对比一下两种高效微调方法的效果怎么样,只有自己动手做实验了才能很客观的看出哪种方法效果更好,在后面的业务工程上具体的方案选型也才可以有更好的选择。

参考paper:https://arxiv.org/pdf/2110.07602.pdf
一 P-tuningV2概述
P-tuningV2方法是P-tuning方法的改进,主要是基于P-tuning和prefix-tuning技术,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的。和P-tuning相比改进之后的P-tuning v2可以在不参数量的模型上微调效果达到Fine tuning的水平,而P-tuning只能在参数量达到百亿量级的模型上才会有好的效果。
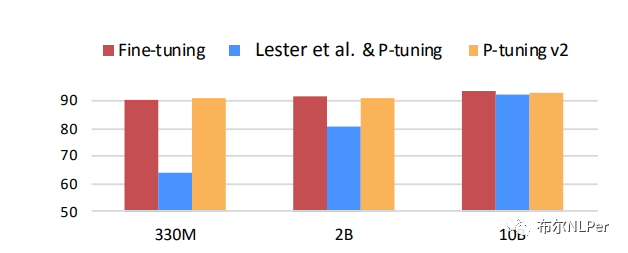
关于介绍了Prefix-Tuning、P-tuning V1和 V2相关的原理和思路。
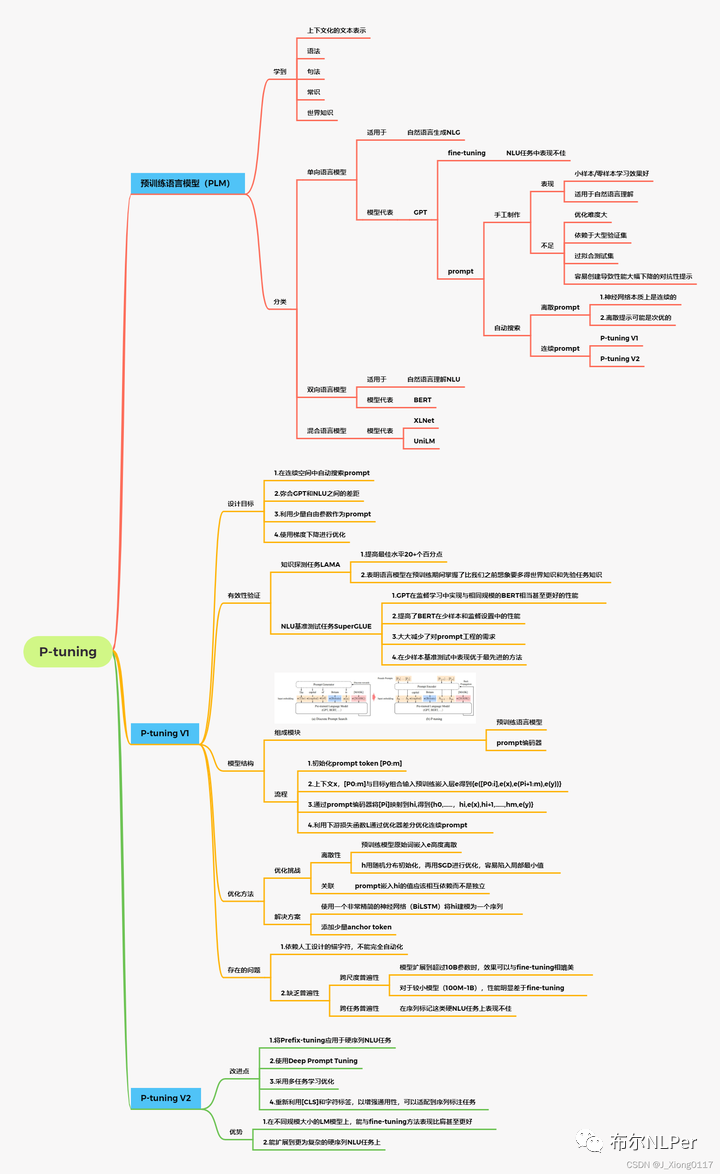
并附录一张总结比较全面的思维导图:
二 P-Tuning V2高效微调ChatGLM的步骤
1 项目和环境搭建
这里面项目地址也是官方提供的开源代码:
https://github.com/THUDM/ChatGLM-6B
官方教程文档:
https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
首先使用git将项目clone到自己的本地或者云服务器里面,微调部分在THUDM/ChatGLM-6B的ptuning目录下面,需要进入ptuning目录,安装项目requirements.txt环境。
cd ptuning
运行微调需要4.27.1版本的transformers。除 ChatGLM-6B 的依赖之外,还需要安装以下依赖
pip install rouge_chinese nltk jieba datasets
2 数据集处理
官方给出的数据处理格式:
ADGEN 数据集为根据输入(content)生成一段广告词(summary)。
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
其实数据格式就是{“content”:“”,“summary”:“”}形式,这里面我没可以处理自己的数据集成这种格式,我的是问答类数据,那么content就是问题,summary就是回答。

用以上数据格式创建自己的train.json和dev.json文件,指定数据文件夹路径后期微调需要改成自己的路径名称。
这里是我的路径:

这里面给两种数据增强的方法(扩展):
(1)simBert做相似文本生成。
这里给出苏神的代码:
https://github.com/ZhuiyiTechnology/simbert

(2)直接使用ChatGPT生成相似文本。

对比可以很明显的看出GPT3.5生成的相似文本质量会更好,后期如果有这方面需求的可以尝试使用GPT3.5模型接口去做数据扩增的工作。
3 P-Tuning v2微调步骤
(1)修改train.sh文件参数

修改数据集路径train_file 和validation_file 为自己指定路径名称,更改模型路径model_name_or_path 为自己的模型路径。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载,我使用的是32G V100是完全够用了,就把quantization_bit 4注释了。这里可以根据自己的显卡配置自行设置。
其他参数也是根据自己数据集具体情况来调整合适的值,比如max_source_length 长度根据自己数据content文本长度来定,max_target_length 可以根据自己summary长度大小来设定。
bash train.sh
开始运行train.sh做微调,这里我自定义的数据集比较少,预计训练时间两三个小时左右。
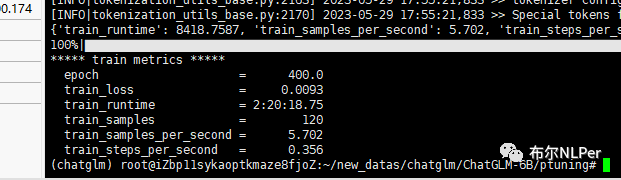
训练好的模型文件保存在output文件夹下,后期做推理时需要加载。
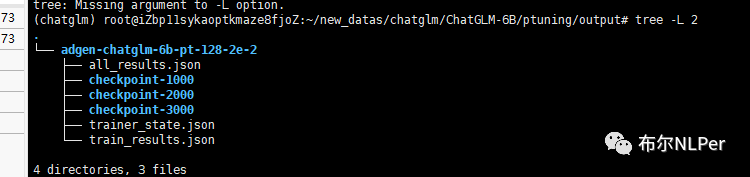
(2)修改evaluate.sh参数

和train.sh一样需要修改数据集和模型路径名称。
bash evaluate.sh
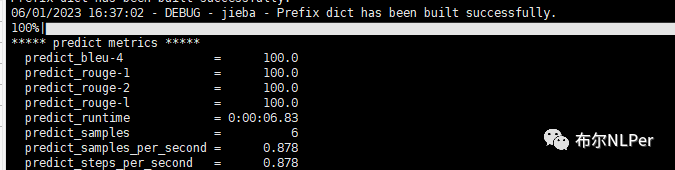
模型评估的中间文件predict也保存在output文件夹里面,可以用来评估模型在验证集上的效果。
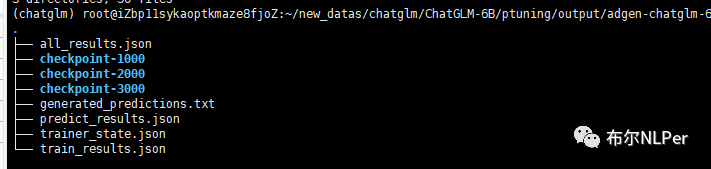
4 模型推理
模型的推理演示这里面也是使用和LORA一样的官方提供的web_demo2.py界面展示,当然可以运行ptuning路径下的web_demo.sh文件,同样需要改一下模型文件路径。

对比ptuning路径下的web_demo.py 在web_demo2.py中修改代码:
from transformers import AutoModel, AutoTokenizer, AutoConfig
import streamlit as st
from streamlit_chat import message
import os, sys
import torch
st.set_page_config(
page_title="ChatGLM-6b 演示",
page_icon=":robot:"
)
@st.cache_resource
def get_model():
tokenizer = AutoTokenizer.from_pretrained("/root/new_datas/chatglm/ChatGLM-6B/model/chatglm-6b", trust_remote_code=True)
config = AutoConfig.from_pretrained("/root/new_datas/chatglm/ChatGLM-6B/model/chatglm-6b", trust_remote_code=True)
config.pre_seq_len = 128 # 预测时需要模型config中含有 pre_seq_len, 模型才会定义prefix_encoder
model = AutoModel.from_pretrained("/root/new_datas/chatglm/ChatGLM-6B/model/chatglm-6b", config=config, trust_remote_code=True).half().cuda()
prefix_state_dict = torch.load(os.path.join("/root/new_datas/chatglm/ChatGLM-6B/ptuning/output/adgen-chatglm-6b-pt-128-2e-2/checkpoint-3000", "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
model = model.eval()
return tokenizer, model
MAX_TURNS = 20
MAX_BOXES = MAX_TURNS * 2
def predict(input, max_length, top_p, temperature, history=None):
tokenizer, model = get_model()
if history is None:
history = []
with container:
if len(history) > 0:
if len(history)>MAX_BOXES:
history = history[-MAX_TURNS:]
for i, (query, response) in enumerate(history):
message(query, avatar_style="big-smile", key=str(i) + "_user")
message(response, avatar_style="bottts", key=str(i))
message(input, avatar_style="big-smile", key=str(len(history)) + "_user")
st.write("AI正在回复:")
with st.empty():
for response, history in model.stream_chat(tokenizer, input, history, max_length=max_length, top_p=top_p,
temperature=temperature):
query, response = history[-1]
st.write(response)
return history
container = st.container()
# create a prompt text for the text generation
prompt_text = st.text_area(label="用户命令输入",
height = 100,
placeholder="请在这儿输入您的命令")
max_length = st.sidebar.slider(
'max_length', 0, 4096, 2048, step=1
)
top_p = st.sidebar.slider(
'top_p', 0.0, 1.0, 0.6, step=0.01
)
temperature = st.sidebar.slider(
'temperature', 0.0, 1.0, 0.95, step=0.01
)
if 'state' not in st.session_state:
st.session_state['state'] = []
if st.button("发送", key="predict"):
with st.spinner("AI正在思考,请稍等........"):
# text generation
st.session_state["state"] = predict(prompt_text, max_length, top_p, temperature, st.session_state["state"])
这里注意之前在推理过程遇到过两个问题,之前踩了不少坑:
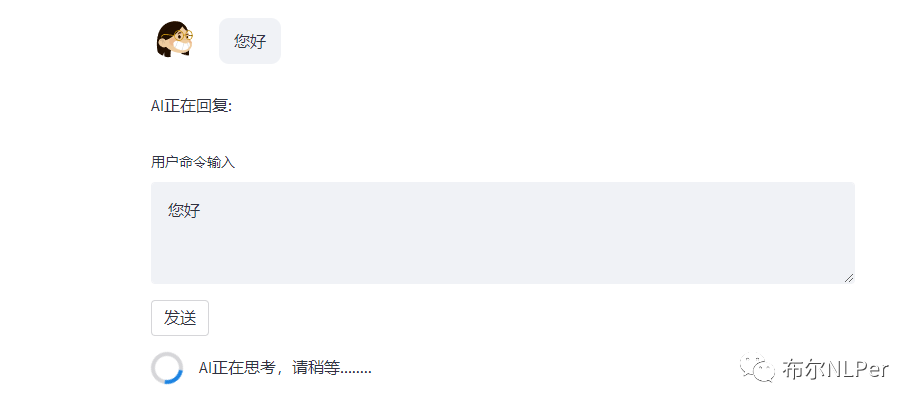
原因是模型不能简单的把web_demo2.py中的模型路径替换,出现这种问题是因为直接修改一下web_demo2.py启动文件中模型路径ptuning/output/adgen-chatglm-6b-pt-8-2e-2 ,这样是有问题的。于是借鉴了ptuning路径下的web_demo.py中加载模型的方式重新加载模型。
另一个是报错
“AttributeError: ‘ChatGLMModel‘ object has no attribute ‘prefix_encoder‘”
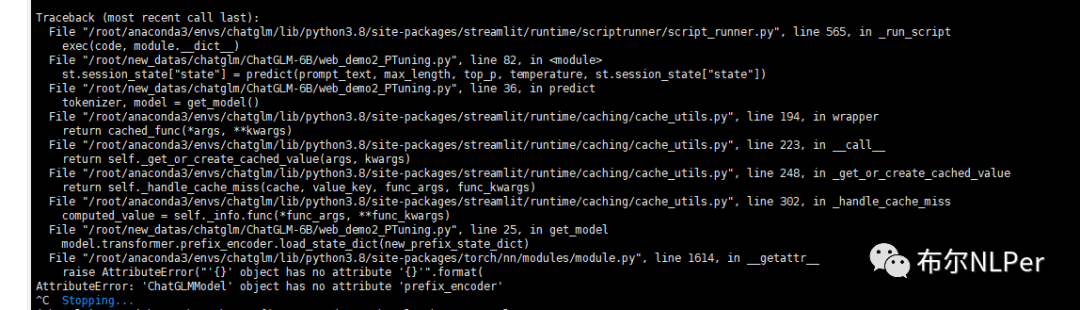
该问题主要是加载模型出现了问题,加载模型部分需要添加config配置参数,并且需要给config指定pre_seq_len,预测时需要模型config中含有 pre_seq_len, 模型才会定义prefix_encoder。
config.pre_seq_len = 128 # 预测时需要模型config中含有 pre_seq_len, 模型才会定义prefix_encoder
model = AutoModel.from_pretrained("/root/new_datas/chatglm/ChatGLM-6B/model/chatglm-6b", config=config, trust_remote_code=True).half().cuda()
当然直接用我上面提供修改后的的web_demo2.py代码应该是不会出现什么两个问题的,注意路径对应自己的路径名称。
三 两种高效微调方式效果对比
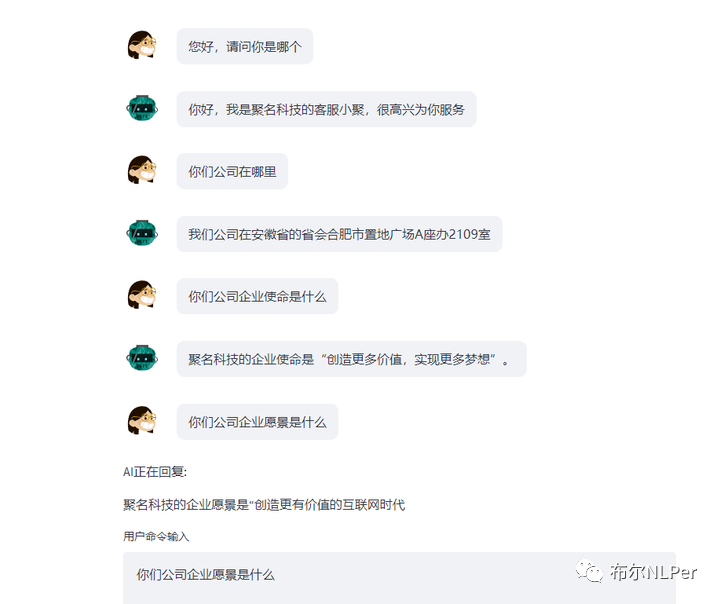
在我自己的相同数据集上面使用LORA和P-Tuning v2两种微调方法,从结果可以明显的看过来P-Tuning v2的效果是要优于LORA效果的。
{"content": "你是谁?","summary":"你好,我是聚名科技的客服小聚,很高兴为你服务"}
{"content": "你们公司地点在哪啊?","summary":"我们公司在安徽省的省会合肥市置地广场A座办2109室"}
{"content": "你们的企业使命是什么?","summary":"聚名科技的企业使命是“创造更多价值,实现更多梦想”。"}
{"content": "你们的企业愿景是什么?","summary":"聚名科技的企业愿景是“创造更有价值的互联网时代"}
{"content": "那你们公司的业务线是啥?","summary":"聚名科技的主要业务是域名服务,是安徽省最大的域名提供商。"}
{"content": "说一下你们公司秉持的的价值观是什么?","summary":"聚名科技的企业价值观是保持奋斗,追求细节,开放创新,结果导向,客户第一"}
下面是LORA高效微调效果:
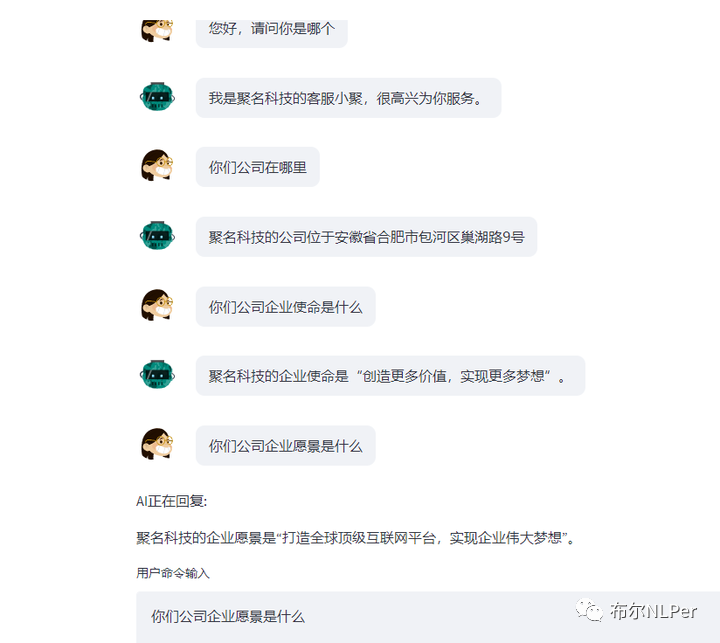
下面是P-Tuning V2高效微调效果:
四 结束语
本文主要介绍了另一种基于P-tuningV2的高效微调方法,用实验对比了基于LORA的微调方式,效果还是明显要更好一点的,后面在实际业务的技术选型上也计划使用基于P-tuningV2的高效微调方法来微调公司垂直领域的业务。总结一下在做实际工作和学习过程中调研方案一定要多动手去做实验,才能更客观的选择更好的方案,当然多看理论也是很好处的,之前也看到了很多P-tuningV2的缺点,相对于LORA微调,前者在大模型微调过程中出现的知识遗忘问题要更严重,后期还要多做实验去验证这个问题。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1415
1415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









