






 利用 Ollama 和 LangChain 强化条件判断语句的智能提示分类
利用 Ollama 和 LangChain 强化条件判断语句的智能提示分类
❝
本文译自Supercharging If-Statements With Prompt Classification Using Ollama and LangChain一文,以Lumos工具为例,讲解了博主在工程实践中,如何基于LangChain框架和本地LLM优雅实现了通用的意图识别工具。
简短回顾 Lumos! 🪄
我以前写过不少关于 Lumos 的内容,所以这次我就简短介绍一下。Lumos 是一个基于本地大型语言模型(LLM)开发的网页浏览辅助工具,呈现为 Chrome 浏览器插件形式。它可以抓取当前页面的内容,并把抓取的数据在一个在线内存 RAG 工作流中处理,一切都在一个请求上下文内完成。Lumos 建立在 LangChain 基础上,并由 Ollama 本地LLM驱动,开源且免费。
Lumos 擅长于大型语言模型(LLM)所擅长的任务,比如:
- 摘要新闻文章、论坛帖子与聊天历史
- 关于餐厅和产品评价的查询
- 提取来自密集技术文档的细节
Lumos 甚至帮我优化了学习西班牙语的过程。该应用的操作逻辑极其方便。随着我不断深入使用这个应用,我也渐渐发掘出用LLM在浏览器中的新奇用法。
重建计算功能 🧮
在处理文本任务时,LLM 既有创意又灵巧。但它们的设计原则不是基于确定性Andrej Karpathy 曾将大型语言模型形容为 “dream machines”。因此,像 456*4343 这样简单的运算,LLM无法通过预测模型给出正确的回答。对于一个包含众多数值和符号的复杂方程,即便是最高级的模型也可能力不从心。
456*4343 — 56/(443-11+4) 等于多少?
 GPT-3.5 错误地“计算”了 456*4343
GPT-3.5 错误地“计算”了 456*4343
 Llama2 错误地“计算”了 456*4343
Llama2 错误地“计算”了 456*4343
LLMs 在处理特定任务时需要借助额外的工具,比如执行代码或解决数学问题等。Lumos 也是如此。我不记得为什么需要在浏览器里快速使用计算器了(或许是计算税收?),但我知道我不想拿出手机或另开一个标签页。我只是希望我的 LLM 能准确解答数学问题。
所以,我决定把一个计算器集成到 Lumos 里。
借助 Ollama 进行提示分类 🦙
我之前用 Ollama 做了提示分类的实验并发现这个技术相当有用。如果可靠的话,“分类提示”的输出可以强化条件判断语句和逻辑分支。
虽然 Lumos 并没有基于 LangChain Agent 实现,但我希望用户使用它的体验能和与 Agent 互动一样流畅。它应能够在不需明确的指示下独立执行各种工具。应用程序应当能自动识别何时需要使用计算器。利用 Ollama 来判断是否需要计算器工具的实施是轻而易举的。
参考以下代码示例:
const isArithmeticExpression = async (
baseURL: string,
model: string,
prompt: string,
): Promise<boolean> => {
// 检查开头的触发指令
if (prompt.trim().toLowerCase().startsWith("calculate:")) {
return new Promise((resolve) => resolve(true));
}
// 否则,尝试分类当前提示
const ollama = new Ollama({ baseUrl: baseURL, model: model, temperature: 0, stop: [".", ","]});
const question = `以下提示是否代表含有数字和运算符的数学方程式?请用'是'或'否'来回答。\n\n提示: ${prompt}`;
return ollama.invoke(question).then((response) => {
console.log(`isArithmeticExpression 分类结果: ${response}`);
const answer = response.trim().split(" ")[0].toLowerCase();
return answer.includes("yes");
});
};
只需询问大型语言模型,该提示是否为一个含有数字和运算符的数学方程,并检查返回的内容是否含有“是”或“否”。过程非常直接。这种实现即使在没有 JSON 模式和函数调用时也相当可靠。与让模型分类多个可能无关的类别相比,直接要求 LLM 对话给出二进制反应相比,更简单直接。我们在测试中的 Llama2 和 Mistral 都表现出色。将模型温度设为0,并配置结束序列如 [".", ","],能进一步提高响应速度和可靠度。相较于用户平时遇到的几秒钟的响应时间,这种分类所增加的延迟可以忽略不计。当然,对于某些应用来说,这点额外的等待时间或许还不够。
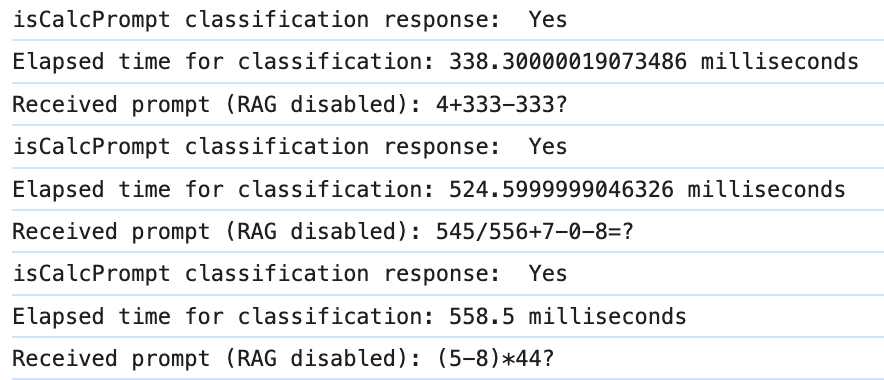 Lumos 控制台日志
Lumos 控制台日志
我们还要特别强调,利用本地 LLMs,这个操作基本上是零成本的。Ollama 在这种情况下的实用性得到了充分的体现。为了让用户能最大程度地控制,我们还设有触发器选项,用户可通过在提示中加上特定的前缀来确保触发相应工具的执行。这与 ChatGPT 通过 @ 符号调用特定 GPT 功能相似。
456 x 4343 =1980408 🔢
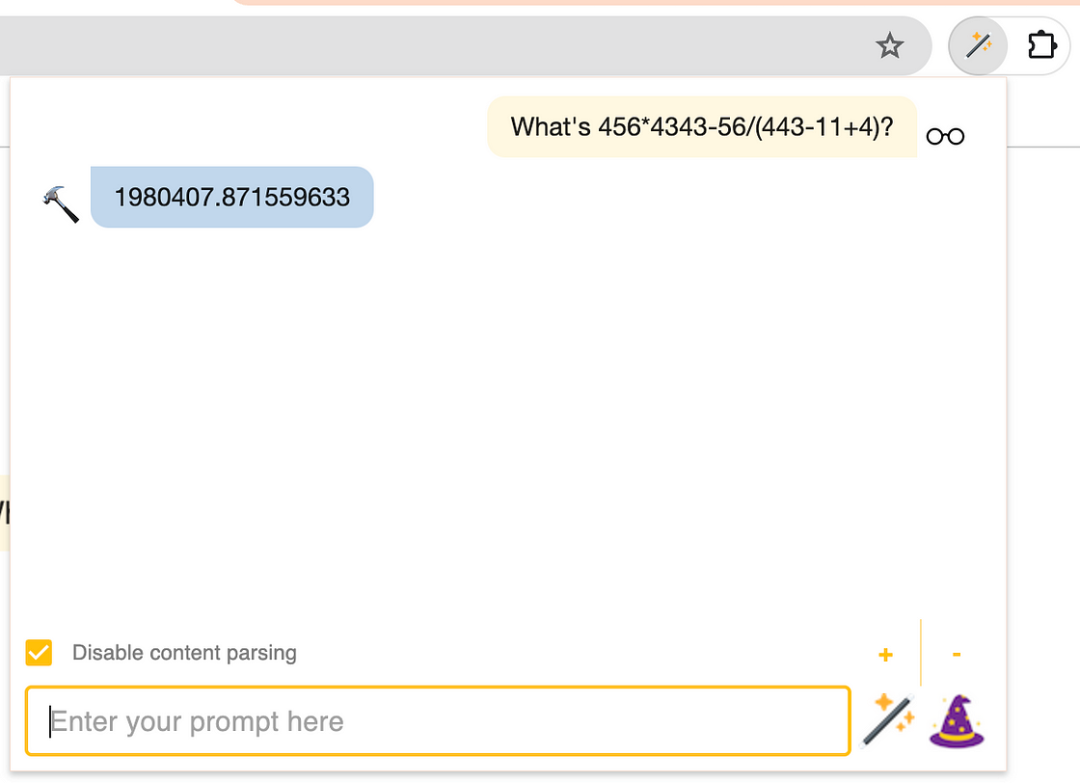 Lumos 正确计算出 456*4343
Lumos 正确计算出 456*4343
Lumos 的计算器 设计得非常直观。它是以 LangChain 工具(Tool)的形式构建的,这样未来可以方便地将应用整合进更强大的 Agent 系统中。对于自定义工具,虽然 LangChain 推荐开发 DynamicTool 或 DynamicStructuredTool,直接继承 Tool 基类同样简洁易行。
参见以下代码:
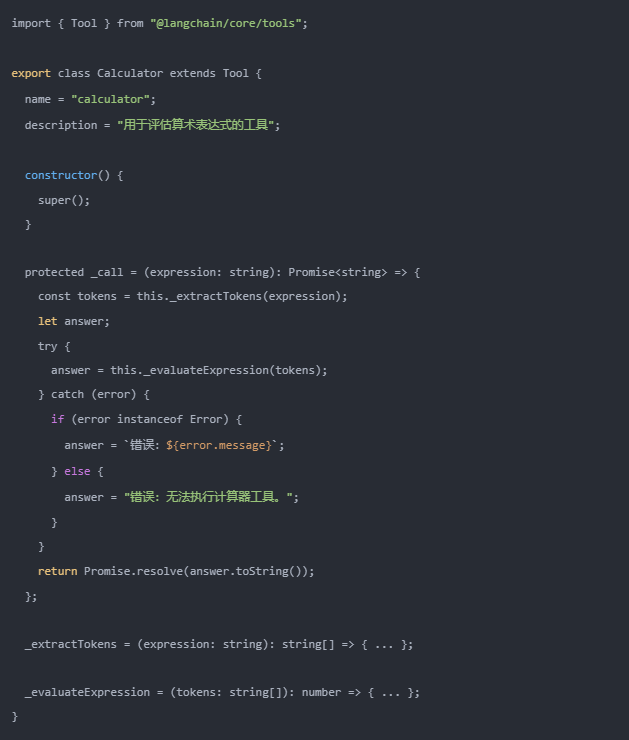
当 Lumos 接收到一个类似数学方程的提示,不管它的复杂程度如何,它都能自动判定调用计算器。
扩展分类技巧处理复杂条件 🌲
这种为多种模式功能而复现的分类技术,比如Lumos 的多模式能力,就能够在用户需要时从网页上下载图像。反之,如果不需要,则出于效率考虑,跳过下载过程。我决定用一个可配置的函数来普适化这种方法。
参见以下代码:
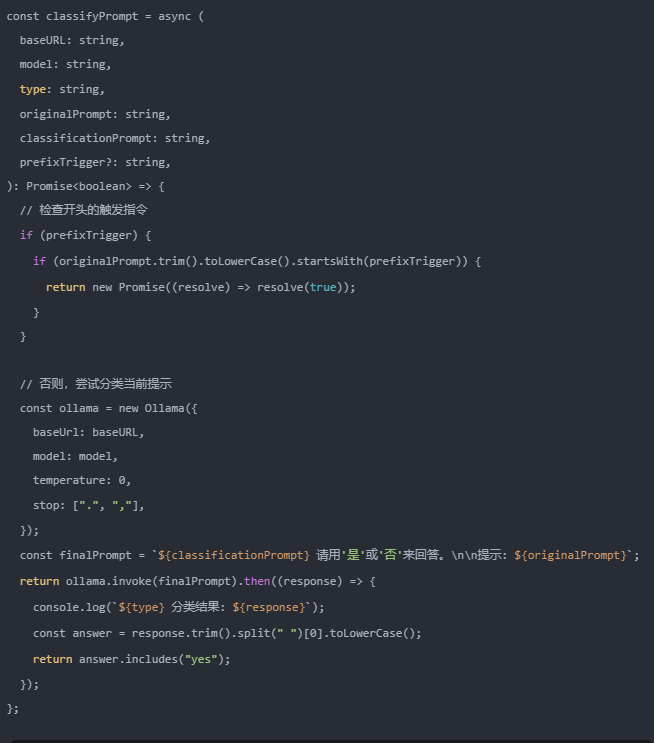
现在 classifyPrompt() 能够接收一个“分类提示”以及一个触发器参数。这个函数可以在整个应用程序代码中被复用。
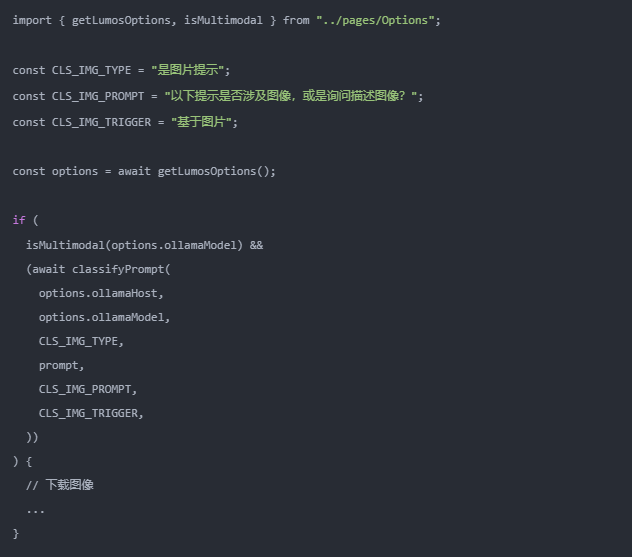
把分类结果纳入条件判断语句是个自然、简单并且有效的做法。采用这种方法,软件开发者能够完全掌握应用程序的运作流程。到一定程度上,依赖于 LLM 的编程逻辑现在变得可测试了。
Lumos 在决定是否下载图像的时候,不仅考虑了分类结果,还把用户的一些配置选项考虑在内。更复杂的是,结合复杂应用状态(比如用户配置、访问控制、缓存状态等)和分类结果进行一致决策对于 LLM 来说,在大规模应用上会更有挑战。
这种方法可能被用于同时对多个 LLM 功能进行 A/B 测试。对于某些敏感领域,比如需要特定授权执行工具的情况或对 RAG 功能需要特定数据权限访问,这种设计方式看起来非常合适。我们不会让任何重要决策留给偶然。
Lumos 未来将如何发展?🔮
从短期来看,我将继续探索将更多工具集成进 Lumos。我将考虑迁移至 Agent 架构,并着手解决本地 LLM 应用运行时的效率和速度挑战。
长远来讲,还有更大的机遇值得我们考量。Chrome 插件固然强大,但其能力终究有限。当我们在思索将 LLM 运用到浏览器中的新场景时候,或许有必要完全打造一个全新的浏览器。目前而言,这些尚只是构想。暂且让我们享受在这个创新激动人心的时代开发 LLM 应用的过山车旅程,有了 LangChain 和 Ollama,这趟旅程会更加顺畅。😎
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









