






在大语言模型(LLM)成为 AI 时代核心驱动力的今天,很多开发者和研究者都渴望理解其原理,并尝试自己动手训练一个大模型。然而,大多数资料或过于抽象,或高度依赖已有框架封装,缺乏系统性的指导。

今天推荐的这本书——《从零构建大模型》(原书名 Build a Large Language Model (From Scratch))正好填补了这一空白。它不仅讲透了大模型的基本原理,更从实际出发,带领读者从最底层一步步构建出一个完整的 GPT风格 的模型,实现训练、微调和部署。这是一本将理论与实践完美结合的指南,无论你是研究者、工程师,还是 AI 初学者,都能从中受益良多。
一、为什么推荐这本书?
1. 理论+实践:系统化构建大语言模型的知识体系
本书不是泛泛而谈的 LLM 概念介绍,而是完整还原了一个大语言模型的构建路径——从文本预处理、词嵌入、注意力机制、Transformer 架构,到模型训练、指令微调,再到推理优化与部署,内容扎实全面,环环相扣。
通过阅读这本书,读者能够:
-
深刻理解 GPT 的核心机制:自注意力、多头注意力、位置编码等底层原理不再是“黑箱”;
-
掌握用 PyTorch 从零实现大模型的各个组件:从张量操作到完整模型,拒绝“调包侠”式学习;
-
熟悉大模型预训练与微调的全过程:无监督预训练、分类任务微调、指令微调(如
ChatGPT风格的对话优化); -
学会使用 LoRA 等技术进行轻量级微调(附录 E),降低计算资源需求;
-
建立起完整的 LLM 技术地图:从数据准备到模型部署,覆盖全生命周期。
2. 代码开源,可完全复现
本书配套的代码已全部开源,代码结构清晰、注释详尽,非常适合边读边练。例如,第 3 章实现自注意力机制的代码仅需 50 行,但完整涵盖了权重计算、因果掩码、多头划分等核心逻辑,真正实现“手把手”教学。
3. 从基础打起,适合所有技术层次读者
无论你是否熟悉深度学习,书中从 PyTorch 基础(附录 A)、词嵌入、注意力机制讲起,再到完整的 Transformer 和 GPT 架构搭建,层层推进。
-
对初学者:附录 A 提供 PyTorch 快速入门,无需担心框架不熟;
-
对进阶者:附录 E 和 F 详解 LoRA 微调和推理优化,助力工业级部署;
-
对研究者:第 7 章指令微调与评估方法,直击 ChatGPT 核心技术。
二、书籍核心内容:从零构建 GPT 的完整路径
本书最打动人的地方,不只是讲“怎么做”,而是构建了一个完整的“做这件事的知识地图”——从理解语言模型的本质,到动手实现每一个关键模块,最终完成一个能运行的 GPT 模型。
这本「从零构建大模型中英版」已经整理并打包好pdf了,放在这↓↓↓↓↓↓↓↓

我们可以用一张“构建路径图”来概括这条从 0 到 1 的旅程:
graph TDA[文本处理] --> B[编码层设计]B --> C[注意力机制]C --> D[Transformer Block]D --> E[完整 GPT 模型]C --> C1[多头注意力]D --> D1[层归一化、GELU、残差]C1 --> F[因果掩码 + 训练流程]D1 --> G[微调任务(分类、指令)]F <--> G
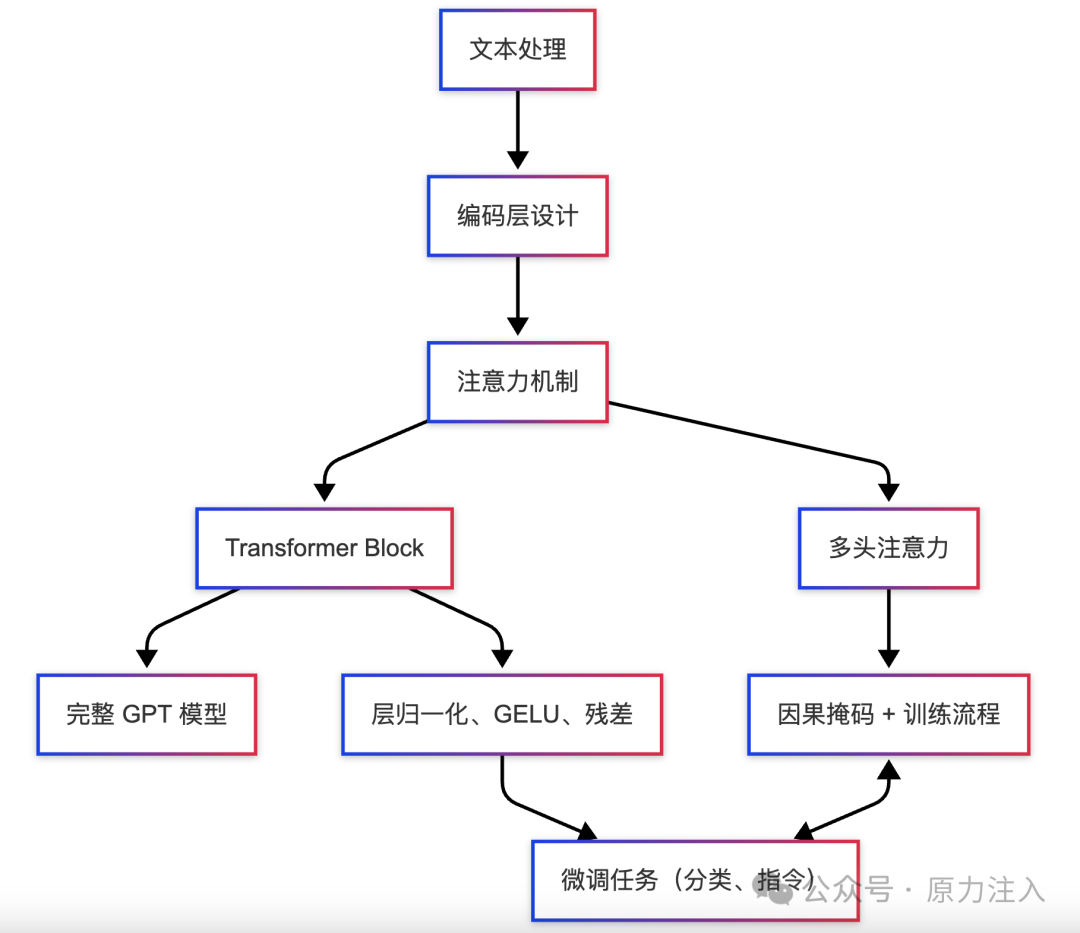
接下来的章节内容正是沿着这条路径展开,每一章不仅解释“这一步是什么”,更讲清楚“为什么要这样做”以及“怎么亲手实现”。
1. 明确目标:什么是大语言模型?(第 1 章)
-
揭秘
LLM的三大能力:文本生成、逻辑推理、任务泛化; -
拆解
GPT架构的演进史:从Transformer到GPT-3的设计哲学。
2. 数据准备:文本预处理与嵌入表示(第 2 章)
-
BPE 分词:将“机器学习”拆解为“机器”+“学习”,平衡词表大小与语义粒度;
-
位置编码:用正弦函数为词元添加位置信息,解决
Transformer的无序性问题; -
滑动窗口采样:从长文本中提取训练样本,提升数据利用率。
3. 模型基础:注意力机制与 Transformer(第 3-4 章)
-
自注意力机制:用矩阵运算模拟词与词的关系权重,解决长程依赖问题;
-
因果掩码:在训练时隐藏未来词元,确保生成文本的因果性;
-
多头注意力:并行捕捉不同语义空间的特征,提升模型表达能力;
-
层归一化与残差连接:加速训练收敛,缓解梯度消失。
4. 预训练与微调(第 5-7 章)
-
无监督预训练:用大规模文本数据训练模型“填空”能力(如预测下一个词);
-
分类微调实战:在预训练模型上添加分类头,实现垃圾邮件检测等任务;
-
指令微调:用对话数据教会模型遵循人类指令(如“写一首诗”)。
5. 进阶实战与优化(附录)
-
LoRA 微调:仅训练少量参数,低成本适配新任务;
-
推理优化:量化、剪枝、批处理,加速模型部署。
三、对初学者的独特价值:从困惑到通透的跃迁
许多初学者面对大模型时,常陷入以下困境:
-
“公式看不懂” → 本书用代码替代数学推导,例如用矩阵乘法实现注意力权重(代码见第 3 章);
-
“数据集太大跑不动” → 提供小规模示例数据集,可在个人电脑上运行;
-
“不知道如何优化模型” → 第 5 章详解温度缩放、
Top-k采样等解码策略,平衡生成多样性与质量。
书中代码示例(第 4 章生成文本):
def generate_text(model, prompt, max_length=50):model.eval()tokens = tokenizer.encode(prompt)for _ in range(max_length):logits = model(torch.tensor([tokens]))next_token = logits.argmax(-1)[-1].item()tokens.append(next_token)return tokenizer.decode(tokens)
仅需 10 行代码即可实现基础文本生成,直观感受模型工作原理。
四、学习路径与实践建议
1. 三步上手:零基础友好
-
第一步(1-2 天):通读第 1-2 章,运行代码仓库中的文本预处理示例;
-
第二步(3-5 天):实现第 3-4 章的注意力机制和
GPT模型,生成简单文本; -
第三步(1-2 周):用第 5-7 章代码训练小规模模型,完成分类和指令微调。
2. 资源整合:高效学习工具包
-
代码仓库:优先使用中文注释版(LLMs-from-scratch-CN);
-
延伸阅读:搭配《
The Annotated Transformer》理解经典论文; -
社区支持:关注
MLNLP-World技术社区,获取最新解读与答疑。
五、从“用模型”到“造模型”的蜕变
构建大语言模型不再是科技巨头的专利。通过本书,你将:
-
摆脱“调参侠”困境,真正掌握模型设计主动权;
-
低成本训练垂直领域小模型,如法律咨询、医疗问答专用
LLM; -
为学术研究夯实基础,探索模型压缩、多模态等前沿方向。
正如作者所言:“理解大模型的最好方式,就是亲手构建一个。”
无论你的目标是求职、创业,还是纯粹的技术热爱,《从零构建大模型》都将成为你 AI 之旅的里程碑。
请立即行动,用代码揭开大模型的神秘面纱吧!
这本「从零构建大模型中英版」已经整理并打包好pdf了,放在这↓↓↓↓↓↓↓↓

















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









