




目录
站在测试管理的角度,对缓存系统在主从切换、节点宕机、网络分区等故障场景下的验证,需要进行系统化、工程化的测试设计与分析。这不仅关乎功能正确性,更直接关系到系统的可用性、数据一致性和持久性。
作为测试经理,我们需要构建一个覆盖全面、风险导向的测试策略。以下是详细的测试思路和分析。
一、 核心测试维度
在规划具体测试场景前,我们首先要明确从哪些维度去衡量缓存系统在故障下的表现:
可用性:故障发生时及发生后,缓存服务是否仍然可用(可读、可写)?服务中断时间有多长?
数据一致性:
最终一致性:主从切换或脑裂后,数据在不同节点间最终是否一致?
强一致性:(如果系统声称支持)在故障期间,读写是否始终能读到最新写入的数据?
数据持久性/完整性:故障恢复后,数据是否会丢失?是否会出现大量脏数据?
性能与稳定性:故障恢复期间及恢复后,系统的性能(吞吐量、延迟)是否会急剧下降?系统是否能保持稳定,不会出现雪崩。
二、 故障场景分析与测试思路
我们将针对三种典型故障场景,逐一拆解测试点。
场景一:主从切换
测试目标:验证当主节点因计划内(如运维升级)或计划外(如宕机)原因失效时,从节点能自动或手动提升为新主,并接管服务。
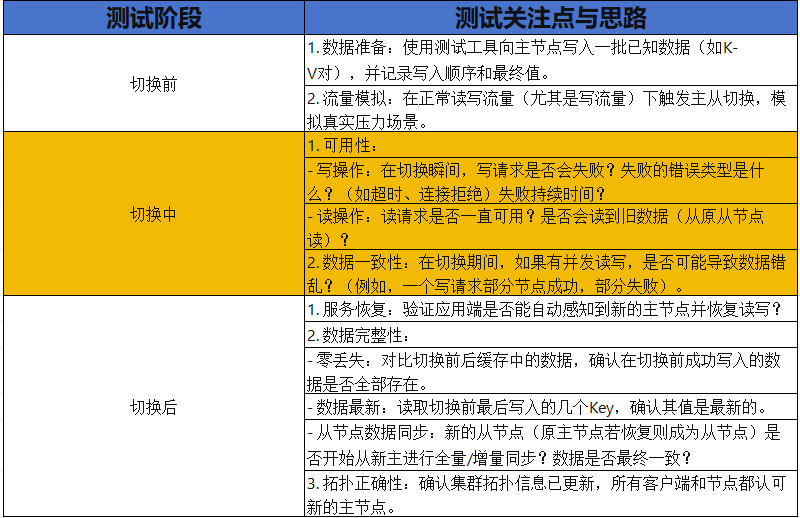
测试管理要点:
自动化:将主从切换场景自动化,并纳入持续集成中的耐久性测试环节。
指标监控:在整个过程中,紧密监控服务拒绝率、请求延迟、节点状态等关键指标。
场景二:节点宕机
测试目标:验证单个或多个节点(主或从)突然失效时,系统的容错能力和自愈能力。
节点类型 测试关注点与思路
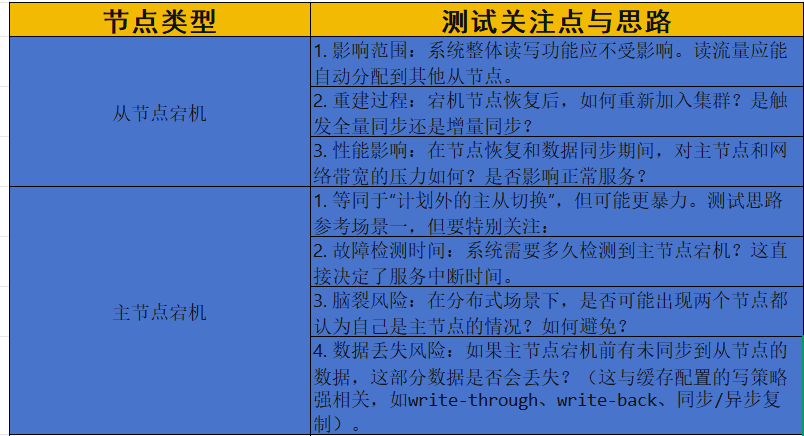
测试管理要点:
混沌工程:主动注入故障(如使用ChaosBlade、Litmus等工具杀死节点进程、断网卡),验证系统的韧性。
容量规划:测试多个从节点同时宕机的场景,评估系统的冗余度是否足够。
场景三:网络分区
测试目标:验证当集群内部网络发生分裂,形成多个孤立的子集群时,系统如何保障数据一致性和可用性(即CAP定理的权衡)。
测试思路:
模拟分区:使用网络工具(如tc, iptables)将集群节点划分为两个或多个无法通信的组。
观察行为:
脑裂:是否两边都产生了新的主节点?导致同时可写?
可用性优先 vs 一致性优先:
如果系统优先保证可用性:那么客户端连接到不同分区的节点可能都能读写,但写入不同分区的数据在网络恢复后会产生冲突。
如果系统优先保证一致性:那么只有一个分区(通常包含大多数原主节点的分区)能继续提供服务,其他分区的节点会拒绝读写请求(变为只读或不可用)。
分区恢复:
数据合并:网络恢复后,系统如何解决数据冲突?是采用最后写入获胜、基于时间戳,还是需要人工干预?
状态恢复:节点是否能自动发现网络恢复,并重新加入集群?数据同步过程是否正常?
数据一致性:最终所有节点的数据是否达成一致?是否有数据被静默丢弃?
测试管理要点:
这是最复杂的场景,需要与开发架构师深入沟通,明确系统在CAP中的选择和冲突解决机制。
重点验证冲突解决策略:设计测试用例,故意在不同的分区写入冲突数据(相同的Key,不同的Value),验证恢复后的结果是否符合预期。
三、 测试策略与保障体系
作为测试经理,不能只关注单个测试用例,而要构建一个完整的测试体系。
分层测试策略:
单元/组件测试:验证单个节点的故障处理逻辑。
集成测试:搭建小型集群,模拟上述故障场景。
系统/端到端测试:在生产类似环境中,在真实业务流量背景下进行故障注入,观察对整个应用的影响。
环境与工具:
专用测试环境:必须有一个可控的、可随意破坏的集群环境。
故障注入工具:集成混沌工程平台,实现故障场景的自动化、标准化。
流量模拟与数据比对工具:开发或引入能够持续产生流量、并能在故障前后进行数据一致性校验的工具。
监控与可观测性:
在测试过程中,必须配备完善的监控系统,包括:
应用层:QPS、成功率、延迟。
缓存层:节点状态、内存使用率、连接数、复制延迟、键数量。
系统层:CPU、内存、网络IO、磁盘IO。
通过日志和链路追踪,定位故障发生时的具体问题。
流程与文档:
测试计划:明确测试范围、场景、通过标准、风险。
测试用例:详细描述每个故障场景的操作步骤和预期结果。
测试报告:记录测试过程、结果、发现的问题(如数据丢失量、服务中断时间)和改进建议。
从测试管理的角度看,验证缓存系统在故障下的表现是一个系统工程。核心思路是:主动模拟故障,系统化地观察系统的行为,并从可用性、一致性和持久性三个维度进行量化评估。通过构建覆盖不同故障场景的自动化测试套件,并将其纳入CI/CD管道,可以持续地保障缓存系统的韧性和可靠性,从而为业务的稳定运行打下坚实基础。


















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











