







 这篇博客介绍了注意力机制的概念,将其与人类观察力相类比,并探讨了如何在核回归中应用注意力机制。文章通过非参数和有参注意力机制的示例,展示了注意力池化如何改进特征提取。使用高斯核函数和学习参数w实现的注意力机制在预测任务中表现出了有效性,并通过代码示例展示了在Python中如何实现这一机制。
这篇博客介绍了注意力机制的概念,将其与人类观察力相类比,并探讨了如何在核回归中应用注意力机制。文章通过非参数和有参注意力机制的示例,展示了注意力池化如何改进特征提取。使用高斯核函数和学习参数w实现的注意力机制在预测任务中表现出了有效性,并通过代码示例展示了在Python中如何实现这一机制。
看了沐神讲解的注意力机制,茅塞顿开。但是本人是个新手,理解力也有限,难免理解不到位,还请大家批评指正。
- 概念
注意力机制就类似人的观察力,当我们要从海量的信息中得到目标信息时,从第一个信息逐个甄别显然耗费精力,一般情况下都会根据目标的某些特征来大致定位,然后有方向性的来寻找。就比如说我们需要在一张图片找到一个人,那么我们肯定不会去看一只蝴蝶。我们会找到照片中的所有的人,然后逐个甄别目标人物,这就是注意力机制。 - 概念过渡
回想CNN的池化层,常见的池化层有平均池化,最值池化等。我们对所有的信息都一视同仁,同样的卷积也是一样,对于整个输入只是用一个卷积核来遍历。这就是只考虑了不随意搜索。注意力机制就是有目的的进行搜索,称之为查询。在池化中通过注意力池化就可以得到更好的特征。 - 平均值池化
在池化阶段,最简单的是平均池化,给定一个输入x,把所有的y值均值化以后作为该输入的预测值,这显然不太行。看效果:
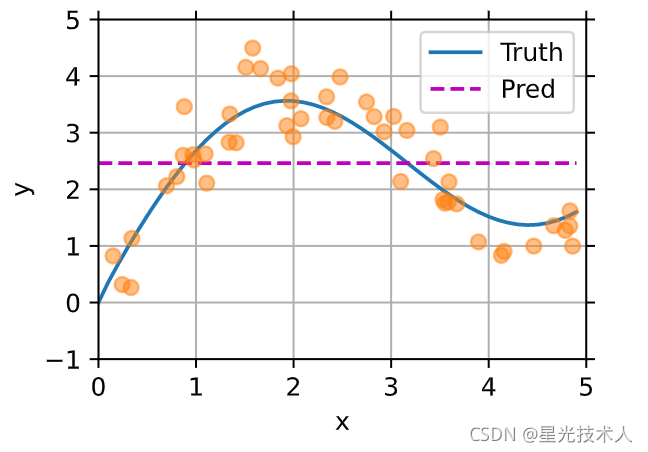
- 非参注意力机制
较好的方法有Nadaraya-Watson核回归,下边是无参数的注意力机制
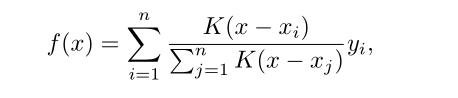
接下来我们来说说核函数,我们取核函数为高斯核函数
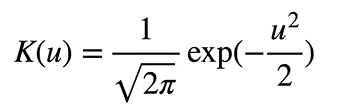
那么:
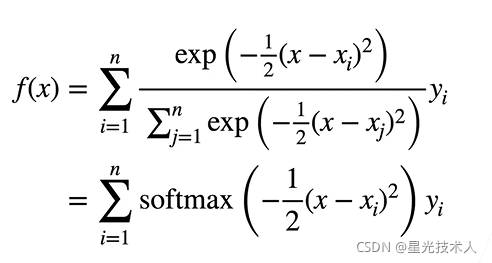
注意这里的式子并不绝对相等,只不过上下上边式子意义在于把我们的距离映射到0–1之间,这与softmax的思想相似,所以用softmax来代替
注意:这里我们固定了bandwidth为1
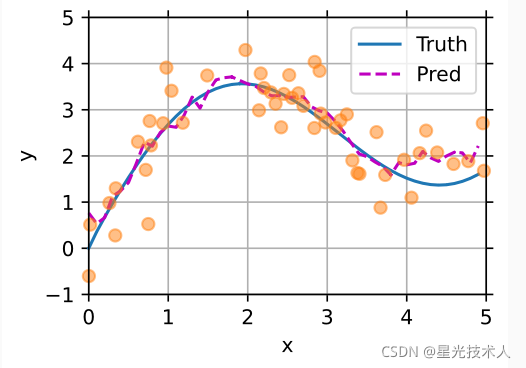
通过计算,我们得到每一个输入对应已知数据的权值,然后通过权值取得输入值的预测值。每一个数据的预测都依据所有训练数据。下面看效果
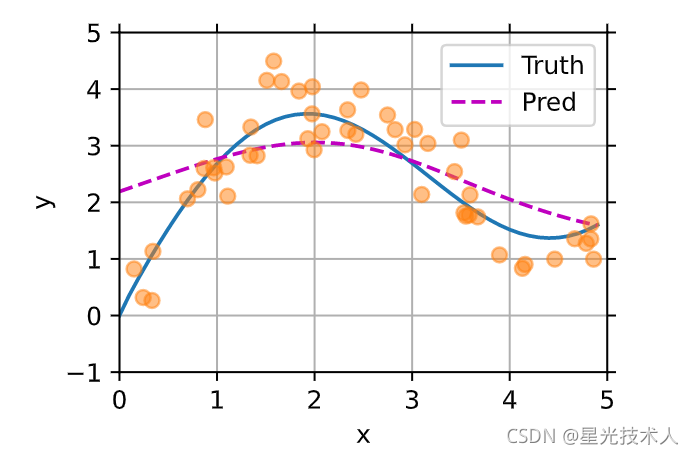
通过上图可知,加入注意力机制对于预测是有效的,不用建立模型,然后选取loss函数,然后逐步优化也是可以的。只要给的数据足够多,就可以预测出理想的模型;但是我们往往得不到大量的数据,所以需要尽量在有限的数据下等到较好的模型。对于这个方法我们固定了带宽为1.所以说我们也可以通过把带宽设置为可以训练的参数来得到最优的带宽参数 - 有参注意力机制
我们引入学习参数w。那么:
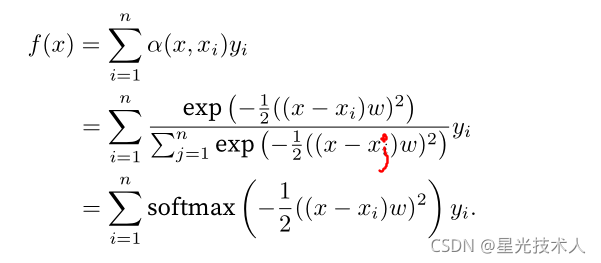
通过训练参数w,得到较好的模型。
- 代码部分
.代码部分:
import torch
from torch import nn
from d2l import torch as d2l
def f(x):
return 2 * torch.sin(x) + x**0.8
class Data():
def __init__(self,n_train):
#n_train是训练样本数
self.n_train = n_train
self.X_tile = None
self.Y_tile = None
self.x_train = None
self.y_train = None
self.x_test = None
self.y_test = None
self.n_test = None
self.keys = None
self.values = None
def get_data(self):
self.x_train, _ = torch.sort(torch.rand(self.n_train) * 5) # 训练样本的输入
self.y_train = f(self.x_train) + torch.normal(0.0, 0.5, (self.n_train,)) # 训练样本的输出
self.x_test = torch.arange(0, 5, 0.1) # 测试样本
self.y_truth = f(self.x_test) # 测试样本的真实输
self.n_test = len(self.x_test)
self.X_tile = self.x_train.repeat((self.n_train, 1)) #训练数据的x轴坐标(50,50)
self.Y_tile = self.y_train.repeat((self.n_train, 1)) #训练数据的y轴坐标(50,50)
self.keys = self.X_tile[(1 - torch.eye(self.n_train)).type(torch.bool)].reshape((self.n_train, -1))#形状为(50,49),每一行都是不包括自己本身的49个横坐标
self.values = self.Y_tile[(1 - torch.eye(self.n_train)).type(torch.bool)].reshape((self.n_train, -1))#形状为(50,49),每一行都是不包括自己本身的49个纵坐标
def plot_kernel_reg(self,y_hat):
d2l.plot(self.x_test, [self.y_truth, y_hat], 'x', 'y', legend=['Truth', 'Pred'],xlim=[0, 5], ylim=[-1, 5])
d2l.plt.plot(self.x_train, self.y_train, 'o', alpha=0.5)
class NWKernelRegression(nn.Module):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True))
def forward(self, queries, keys, values):
#queries是查询点,也就就数据点的x轴坐标,这里作为预测模型的输入点(1,50)
#keys是横坐标组成的矩阵(50,49)
#values是原始纵坐标经过重复以后的矩阵(50,49)
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))#把行坐标拉成列,然后拼接49列,每一 行代表一个输入数据,重复49次
self.attention_weights = nn.functional.softmax(-((queries - keys) * self.w)**2 / 2, dim=1)#(50,49)
return torch.bmm(self.attention_weights.unsqueeze(1),values.unsqueeze(-1)).reshape(-1)
# (50,1,49) (50,49,1)
if __name__ == '__main__':
data = Data(50)
data.get_data()
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=0.2)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, 5]) #Animator库用来动态展示图画
#绘制loss曲线
for epoch in range(20):
trainer.zero_grad()
# 注意:L2 Loss = 1/2 * MSE Loss。
l = loss(net(data.x_train, data.keys, data.values), data.y_train) / 2
l.sum().backward()
trainer.step()
print(f'epoch {epoch + 1}, loss {float(l.sum()):.6f}')
animator.add(epoch + 1, float(l.sum()))
d2l.plt.figure(1)
d2l.plt.title("Parametric attention mechanism")
#计算通过学习参数以后得到的预测值
y_hat = net(data.x_test, data.keys, data.values).unsqueeze(1).detach()
#绘制有参数注意力机制图
data.plot_kernel_reg(y_hat)
d2l.plt.figure(2)
d2l.plt.title('Nonparametric attention mechanism')
#绘制无参数注意力机制下的曲线
keys = data.x_train.repeat((data.n_test, 1))
keys1 = torch.reshape(data.x_train,(data.n_test,1)).repeat((1,data.n_test))
values = torch.reshape(data.y_train,(data.n_test,1))
A = nn.functional.softmax(-((keys - keys1)**2)/2,dim=1)
y_hat = torch.mm(A,values)
data.plot_kernel_reg(y_hat)
结果:
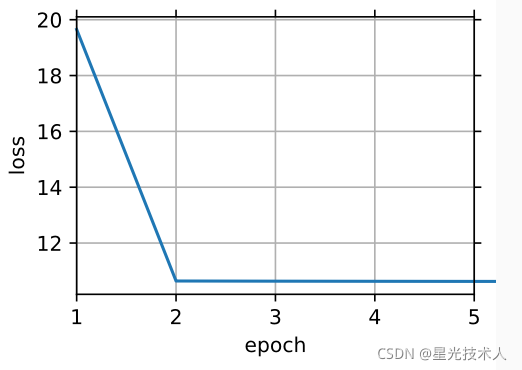
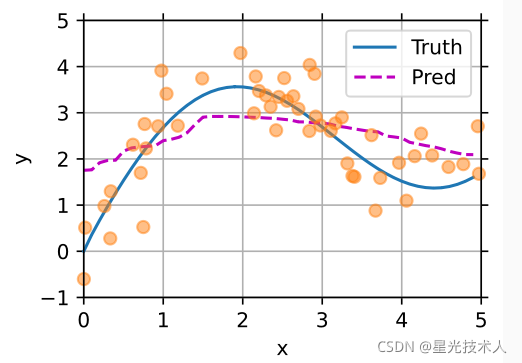



















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











