






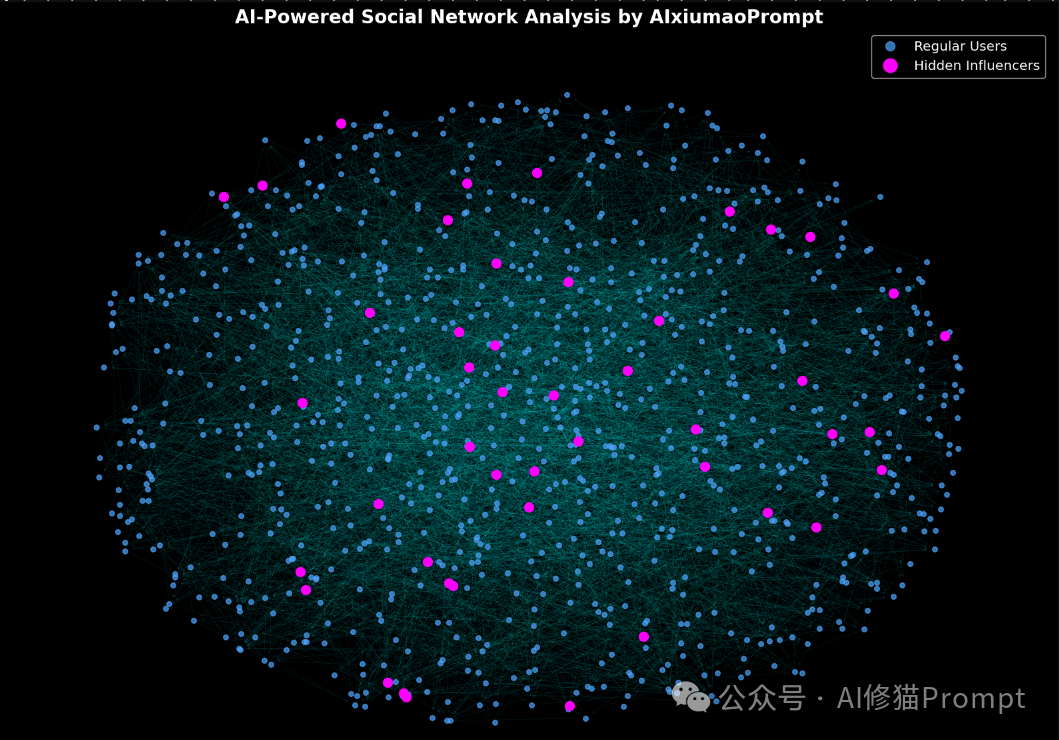
最近有研究发现,当LLM面对结构化数据,特别是图数据时,LLM的表现却不尽如人意。这几天,来自希腊和法国的研究团队提出了一种创新方法——利用伪代码提示来增强LLM的图推理能力。我基于这项研究先写了一个伪代码的SYSYTEM PROMPT运行出了一个社交网络分析的结果,再用这个结果写了一段代码,运行出了下面的图。我的评价只有一句:LLM图推理还是要用Pseudo prompt。

01
伪代码提示的力量
尽管LLM在自然语言处理领域取得了显著成就,但在处理图结构数据时仍面临重大挑战。先前的研究表明,LLM在解决某些看似简单的图问题时存在困难。例如,Wang等人(2023a)的研究显示LLM具有初步的图推理能力,而Fatemi等人(2024)的研究则发现LLM在一些基本图任务(如计算图的边数)上表现不佳。这种矛盾的结果凸显了LLM在图推理领域的不稳定性,也促使研究者思考:如何才能有效提升LLM在图推理任务中的表现?
研究团队提出了一种新颖的方法:使用伪代码作为提示来增强LLM的图推理能力。这种方法的核心思想是将算法逻辑以伪代码的形式呈现给LLM,从而引导模型按照结构化、模块化的方式进行问题解决。
-
图任务:展示了一个简单的图结构。
-
伪代码:提供了计算边数的算法步骤。
-
提示:将图任务转化为自然语言问题。
-
最终提示:结合伪代码和问题,形成完整的提示。
-
输出:按照伪代码prompt输出
这一方法具有以下几个关键优势:
1. 减少歧义: 相比自然语言,伪代码提供了更清晰、更精确的指令,减少了理解上的歧义。
2. 结构化思维: 伪代码prompt引导LLM按照算法逻辑进行推理,促进了结构化思维。
3. 增强可解释性: 通过提供清晰的步骤,伪代码prompt使得LLM的推理过程更加透明和可解释。
4. 融入领域知识: 伪代码允许研究者将图论和算法设计的专业知识直接注入到prompt中。这一点很重要,可以减轻LLM的先验知识匮乏导致的幻觉。
02
实验设计:全面且系统的评估
为全面评估这种方法的有效性,研究团队设计了一个复杂而系统的实验:
1. 图任务范围:
研究涵盖了10种不同复杂度的图算法问题:
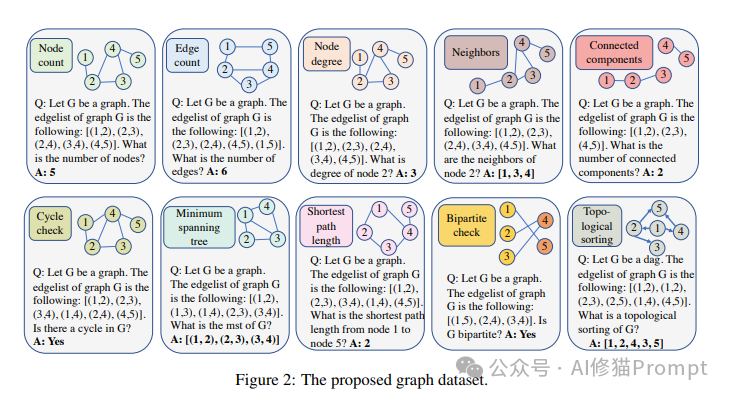
- 节点计数
- 边计数
- 节点度数计算
- 邻居节点识别
- 连通分量计数
- 循环检测
- 最小生成树
- 最短路径计算
- 二分图检测
- 拓扑排序
2. 图类型和规模:
- 主要使用Erdős–Rényi随机图
- 根据节点数量将图分为三类:
* 小型(5-11个节点)
* 中型(11-21个节点)
* 大型(21-51个节点)
- 特殊任务使用特定图类型:
* 拓扑排序任务使用有向无环图
* 二分图检测任务使用随机二分图和Erdős–Rényi图
3. 数据集规模:
- 总计生成6,600个问题实例
- 对于图级属性任务,每种图大小生成100个问题
- 对于节点级属性任务,每种图大小生成500个问题
- 对于边级属性任务,每种图大小生成500个问题
4. 模型选择:
实验采用了两种代表性的LLM:
- GPT-3.5-Turbo:代表专有模型
- Mixtral 7x8B:代表开源模型
5. 对比方法:
研究比较了多种提示方法:
- 零样本提示(0-SHOT)
- 单样本学习(1-SHOT)
- Build-a-Graph提示(BAG)
- 零样本思维链(0-COT)
- 伪代码提示(PSEUDO)
- 伪代码提示+单样本学习(PSEUDO+1-SHOT)
6. 评估指标**:**
使用准确率(正确答案数/总查询数)作为主要评估指标
这种全面的实验设计确保了研究结果的可靠性和普适性,为后续研究提供了坚实的基础。
03
深入分析伪代码提示的效果
1. 整体性能提升
实验结果显示,伪代码提示方法在多数任务中都带来了性能提升。特别是在LLM原本表现欠佳的任务中,这种提升更为显著。例如:
- 对于GPT-3.5-Turbo,在边计数任务中:

* 小型图:PSEUDO方法达到90%准确率,比0-SHOT提高12个百分点
* 中型图:PSEUDO方法达到34%准确率,比0-SHOT提高18个百分点
* 大型图:PSEUDO方法达到9%准确率,比0-SHOT提高7个百分点
- 对于Mixtral 7x8B,在连通分量计数任务中:
* 小型图:PSEUDO+1-SHOT方法达到75%准确率,比0-SHOT提高40个百分点
* 中型图:PSEUDO方法达到63%准确率,比0-SHOT提高23个百分点
2. 模型差异化表现
研究发现,伪代码提示对不同模型的影响并不一致。这一发现强调了prompt工程需要针对不同模型进行定制化设计的重要性。例如:
- 在循环检测任务中:
* 对GPT-3.5-Turbo,PSEUDO方法显著提升了性能(小型图从43%提升到76%)
* 对Mixtral 7x8B,PSEUDO方法反而降低了性能(小型图从85%降至33%)
3. 图规模的影响
研究清晰地表明,随着图规模的增大,LLM的性能普遍下降。这一发现对于处理大规模图数据的prompt设计提出了挑战。例如:
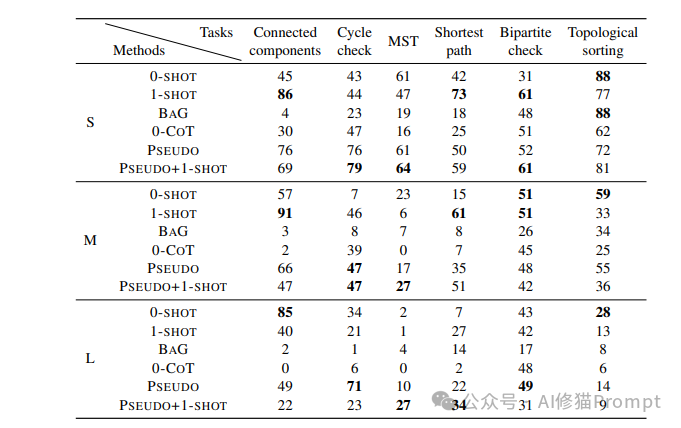
- 在节点度数计算任务中,GPT-3.5-Turbo的性能随图规模增大而显著下降:
* 小型图:75%准确率
* 中型图:24%准确率
* 大型图:6%准确率
4. 节点计数vs边计数
一个令人惊讶的发现是,LLM在节点计数任务上表现出色,但在边计数任务上却困难重重。这种差异在大型图上尤为明显:
- GPT-3.5-Turbo在大型图上的表现:
* 节点计数:100%准确率
* 边计数:仅2%准确率
5. 单例示范的有效性
研究表明,在使用伪代码提示时,仅需一个示例就能达到良好的效果,有时甚至优于多个示例。例如:
- 在最小生成树任务中,对于小型图:
* PSEUDO+1-SHOT方法达到64%准确率
* 增加更多示例并未带来显著改善
6. 伪代码风格的影响
研究还探讨了不同伪代码风格对LLM性能的影响:
- 在最小生成树任务中:
* Python风格伪代码:31%准确率
* 普通伪代码:24%准确率
* 复杂伪代码(多函数):29%准确率
这表明,伪代码的具体表达方式也会影响LLM的理解和执行。
04
伪代码提示的优势所在
1. 结构化思维的引导
伪代码提示为LLM提供了一个清晰的问题解决框架,引导模型按照算法逻辑进行推理。这种结构化的思维方式有助于LLM更好地理解和解决图算法问题。例如,在最短路径计算任务中,伪代码明确指出了使用广度优先搜索的步骤,这大大提高了LLM找到正确解决方案的概率。
2. 歧义性的减少
相比自然语言描述,伪代码具有更低的歧义性。这使得LLM能够更准确地理解任务要求,从而生成更精准的答案。例如,在边计数任务中,伪代码清晰地指出了遍历边列表并累加计数的过程,避免了可能的误解。
3. 步骤分解的优势
伪代码提示将复杂的图算法问题分解为一系列简单步骤。这种分解不仅使得问题更容易解决,也提高了推理过程的可解释性。在连通分量计数任务中,伪代码明确列出了初始化、遍历和合并组件的步骤,使LLM能够逐步推理。
4. 领域知识的融入
通过伪代码,研究者可以将图论和算法设计的专业知识直接注入到提示中。这种方式有效地弥补了LLM在特定领域知识上的不足。例如,在最小生成树任务中,伪代码包含了Kruskal算法的核心思想,这对LLM的正确推理起到了关键作用。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

05
实践启示
这项研究为prompt工程师们提供了宝贵的实践指导:
1. 领域特化的提示设计
针对特定领域的问题,如图算法,使用该领域的专业语言(如伪代码)可能比一般的自然语言提示更有效。例如,在拓扑排序任务中,使用描述有向无环图特性的伪代码可以显著提高LLM的性能。
2. 模型特化的策略
不同的LLM可能对同一种提示方法有不同的反应。因此,在设计prompt时需要考虑目标模型的特性。研究显示,GPT-3.5-Turbo和Mixtral 7x8B在某些任务上对伪代码提示的反应存在显著差异,这强调了针对特定模型优化prompt的重要性。
3. 问题分解的重要性
将复杂问题分解为简单步骤不仅有助于LLM更好地理解和解决问题,也提高了结果的可解释性。在最短路径计算等复杂任务中,这种分解策略的效果尤为明显。
4. 示例的精简原则
在使用伪代码提示时,往往只需要一个精心设计的示例就能达到良好效果。这一发现有助于简化prompt设计过程,同时也降低了计算成本。
5. 规模适应性的考虑
随着处理对象(如图)规模的增大,LLM的性能可能会下降。在设计prompt时需要考虑这一因素,可能需要为不同规模的问题设计不同的提示策略。例如,对于大型图,可能需要更详细的步骤分解或更多的中间检查点。
6. 伪代码风格的选择
研究表明,不同风格的伪代码(如Python风格、普通伪代码、复杂多函数伪代码)对LLM的性能有不同影响。prompt工程师应该根据具体任务和目标模型选择最合适的伪代码风格。
对于正在开发AI产品的prompt工程师来说,这项研究提供了宝贵的启示:
1. 领域知识的重要性: 在设计prompt时,应考虑如何有效地将领域特定的知识和结构融入其中。
2. 问题分解的艺术: 将复杂任务分解为清晰、可执行的步骤是提高LLM性能的关键。
3. 模型特化的必要性: 不同的LLM可能需要不同的提示策略,需要针对特定模型进行优化。
4. 规模适应性的挑战: 随着问题规模的增大,可能需要调整提示策略以维持性能。
5. 持续实验和优化: prompt工程是一个需要不断实验和调整的过程,以找到最佳的提示方法。
伪代码提示方法为LLM在处理结构化数据和复杂算法问题方面开辟了新的可能性。我也把这项研究应用到实际中,如开篇介绍的那样,解决一个在社交媒体中寻找“隐藏影响者”的问题,实际代码中我将用户改为1000,实际找到46名,显示前5名,并分析说明如何利用这些隐藏影响者来进行营销:
OpenAI o1


读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}