










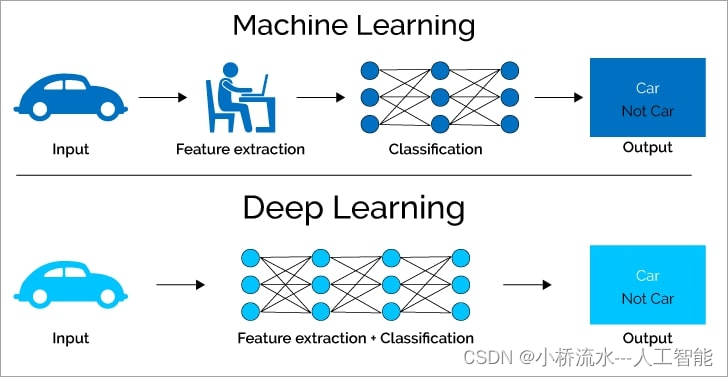
浅层与深层机器学习算法的训练对比
在探索机器学习的世界时,我们经常会遇到各种类型的学习算法,这些算法根据模型的复杂度和层数可以大致分为两类:浅层机器学习算法和深层机器学习算法。尽管这两类算法的目标都是通过从数据中学习来解决问题,但它们在训练过程和使用的技术上存在显著差异。本篇博客将详细探讨这两类算法的训练过程、是否需要损失函数以及它们在应用中的不同点。
浅层机器学习算法
定义和例子
浅层机器学习算法通常指的是那些具有简单结构、较少层次的模型。这类算法包括但不限于线性回归、逻辑回归、决策树、支持向量机(SVM)和K-最近邻(K-NN)等。
训练过程
浅层机器学习算法的训练过程相对简单直接。这些算法通常依赖于统计技术来找出数据特征和输出变量之间的关系。例如:
- 线性回归:通过最小化误差的平方和来找到最佳拟合直线。
- 决策树:通过优化某些决策标准(如信息增益)递归地分割数据。
是否需要损失函数?
不是所有浅层算法都显式地使用损失函数。例如,决策树在构建过程中优化分类错误或节点纯度而不直接计算损失函数,而K-NN则根本不进行显式的训练过程。然而,像线性回归和逻辑回归这样的算法则依赖于损失函数(如均方误差或交叉熵损失)来指导模型训练。
深层机器学习算法
定义和例子
深层机器学习算法,通常称为深度学习,涉及构建多层(通常是非常多层)的网络结构来学习数据的高级抽象表示。典型的例子包括各种类型的神经网络,如卷积神经网络(CNN)、循环神经网络(RNN)和最近非常流行的Transformer模型。
训练过程
深度学习模型的训练通常更为复杂,涉及以下关键步骤:
- 前向传播:数据通过网络层次传播,每层应用激活函数处理数据。
- 损失函数计算:在网络的末端计算预测结果和真实标签之间的误差。
- 反向传播:使用梯度下降或其他优化算法调整网络权重以最小化损失函数。
是否需要损失函数?
深层机器学习算法总是需要一个损失函数,这是训练过程中不可或缺的部分。损失函数在模型训练中起到了评估模型表现的关键角色,帮助优化算法调整模型参数以改进学习成果。
结论
无论是浅层机器学习算法还是深层机器学习算法,损失函数在其中扮演的角色差异显著。 浅层算法在某些情况下可以不依赖于显式的损失函数,而深度学习则绝不能离开损失函数。了解这些差异不仅有助于选择适当的方法解决特定的问题,还有助于更好地理解算法在内部是如何工作的。希望本篇博客能帮助您清晰地理解这两类机器学习算法的训练过程和它们在实际应用中的不同用途。














 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









