




概述
2025年4月29日,凌晨五点多,Qwen3发布。不得不感叹阿里人真卷呀,在这个点发布新产品。
此次Qwen3发布供包括8款「混合推理模型」:
- 两款MoE模型:
- Qwen3-235B-A22B(2350亿总参数、 220亿激活参数)
- Qwen3-30B-A3B(300亿总参数、30亿激活参数)
- 六款Dense模型:
- Qwen3-32B
- Qwen3-14B
- Qwen3-8B
- Qwen3-4B
- Qwen3-1.7B
- Qwen3-0.6B
开源仓库:https://github.com/QwenLM/Qwen3
体验地址:https://huggingface.co/spaces/Qwen/Qwen3-Demo
技术博客:https://qwenlm.github.io/zh/blog/qwen3
注:Qwen3-235B-A22B这种形式表示比较新颖,A22B表示在模型推理时,计算每个Token时,有22B的参数被激活,这22B的参数包括在总参数235B之内。
DeepSeek-V3同样采用混合专家(MoE)架构,671B的参数量中,激活参数量为37B,只是它没有标在名称中。
在Qwen3这样命名之后,之后的模型有可能会遵循这一命名规则。
性能分析
官方的技术博客放了两张性能比较图。
第一张图比较了Qwen3-235B-A22B和Qwen3-32B两个最大参数量的模型,与其它模型在公开数据评测标准下性能表现。
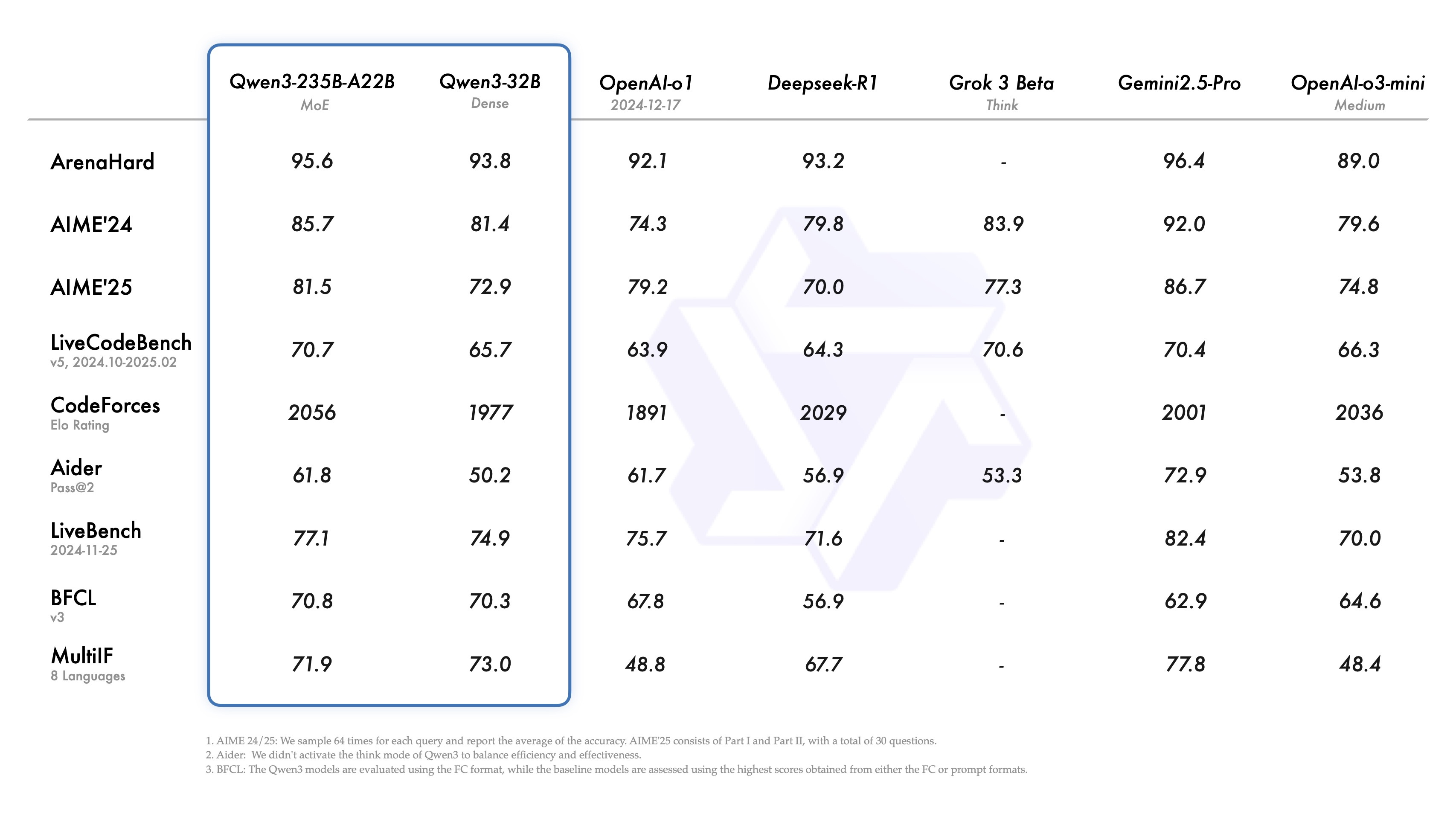
从图中可以看出,在各领域的评测中,这两款模型普遍强于DeepseekR1和OpenAI-o1/o3-mini,但仍略逊于公认最强的Gemini2.5-Pro。
第二张图比较了Qwen3-30B-A3B和Qwen3-4B两个略低参数量的模型,与其它模型在公开数据评测标准下性能表现。
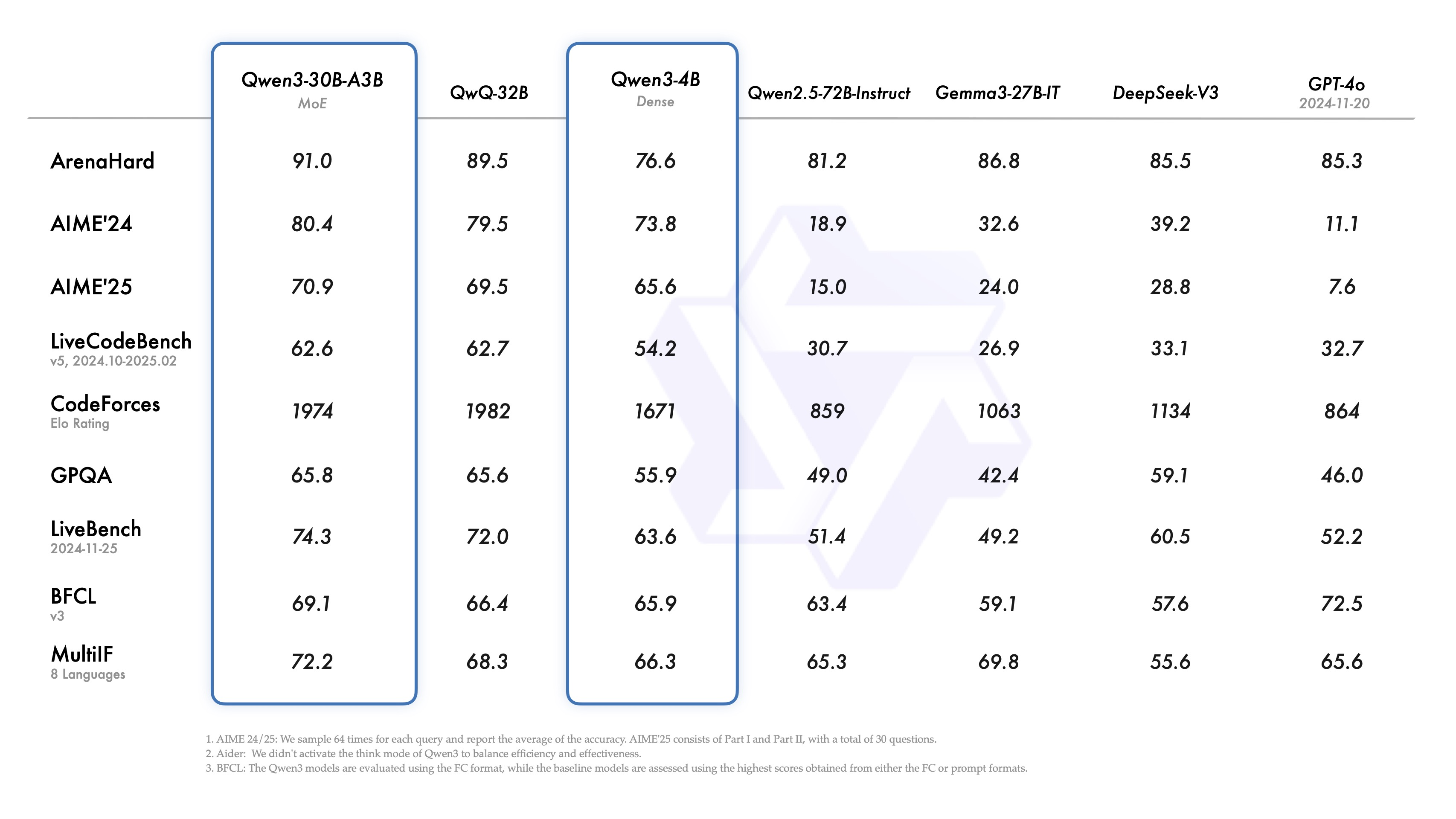
从这张图可以看出,Qwen3-30B-A3B在各项指标上都略高于之前风评不错的QwQ-32B,其它的比较没太大参考价值。
博客中进一步介绍了这8款模型的参数细节,如下表所示:
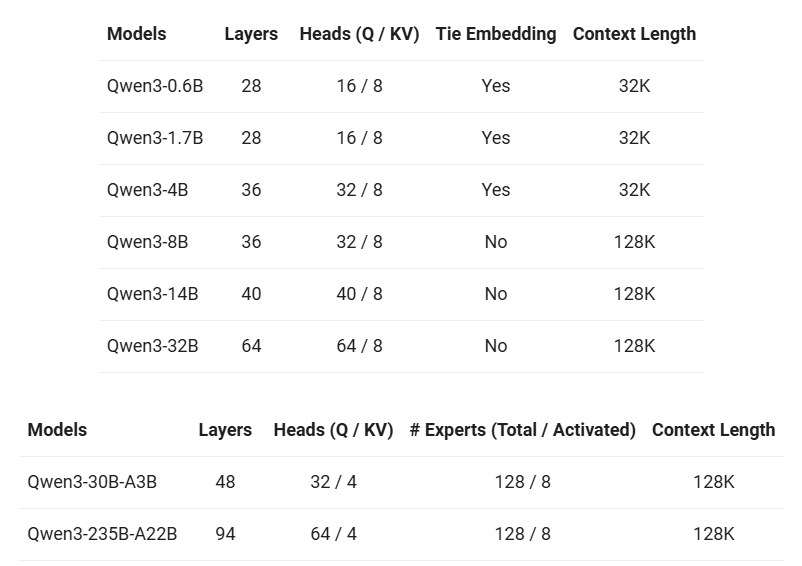
表中的各列含义如下:
- Layers:Transformer 层数
- Heads(Q/KV):Query 头数 / 共享的 Key-Value 头数
- Tie Embedding:是否将输入词嵌入和输出投影层的权重共享,小模型共享后,参数量会节省
- Experts(Total/Activated):专家数(总数/激活的数)
- Context Length:上下文长度
这几个参数中,上下文长度对实际体验影响最大。上下文长度更长,意味着模型能支持输入更多内容,意味着记忆力会更强。
这几款模型的最大上下文长度均为128K,和DeepSeek R1保持一致,并没有明显进步。
亮点分析
Qwen3总共放出3个亮点:
1. 思考/非思考无缝切换
Qwen3系列模型,不再像DeepSeek那样,思考/非思考需要切换模型,同一个模型,可以指定是否让它思考。
- 思考模式:在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
- 非思考模式:在此模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题
这个设计很不错,因为部署模型时,只需要部署一个模型,而把是否思考的选择权交给用户,根据问题难度来选择是否开启思考。
博客中还进一步展现了思考/非思考模型在几个标准评估数据集上的表现:
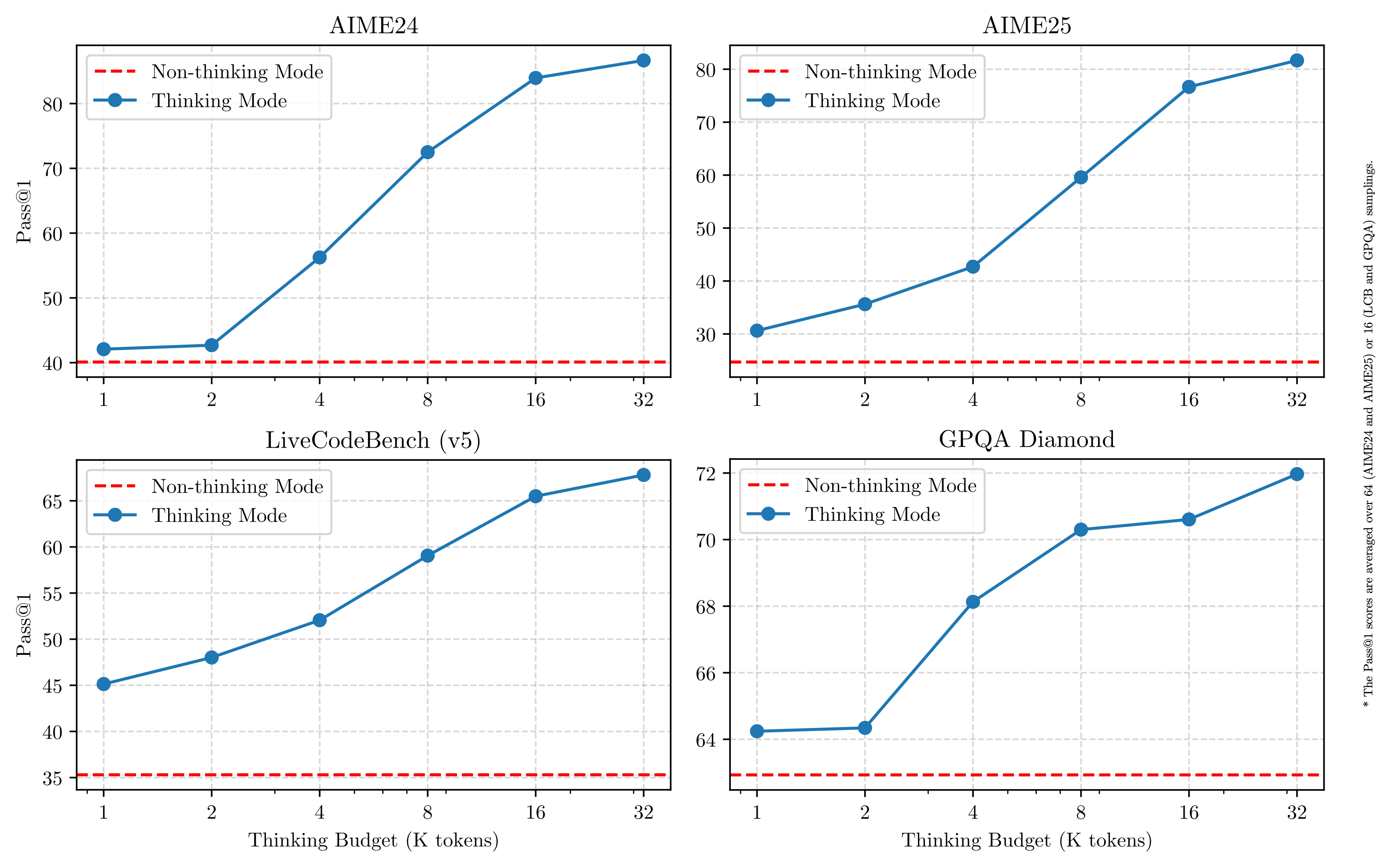
图中,红色的基线表示非思考的性能指标,横坐标表示思考的长度,长度越长,相应的思考过程也越久。图中的蓝线说明,一定范围内,思考时间越长,确实带来了性能的显著提升。
在实际应用时,我们肯定希望模型能尽快回答出问题,而不是思考半天。因此,思考长度和性能之间是需要进行平衡和取舍的。
2. 多语言
Qwen3 模型支持 119 种语言和方言。
这个亮点说实在有点“没活硬整”,扩充那么多小众国家的语言,对普通用户的应用场景,起不到作用。

3. Agent与MCP支持
一个“战未来”的亮点,随着 MCP 服务的增加,会起到一定作用,但目前的使用场景并不多。
训练细节
截至目前,Qwen3没有发布相关的论文,因此只能通过其技术博客了解到部分训练细节。
1.预训练
预训练使用了 36 万亿个token(是Qwen2.5的两倍)
在构建数据集中,使用了Qwen2.5-VL这个多模态模型&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 506
506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











