






作者 | SwanLab 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/1898365161976369427
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『Transformer』技术交流群
本文只做学术分享,如有侵权,联系删文
简介
最近,在 transformers 的代码中可以看到关于Qwen3的PR在3月21日时被提交,并在最近被合并进了主分支了。在src/transformers/models/可以找到已经更新的Qwen3的代码。
虽然网上有几篇针对 Qwen3 模型的 PR 代码分析文章,但是笔者发现绝大多数都是使用 LLM 生成的文章,许多内容都是错误或者具有严重的误导性,因此笔者仅自己所能对代码做了细致的分析和考证。
本文我们将根据Qwen3的稠密模型和MoE模型相较于于原来模型的差异,说下笔者的一些观点、猜测和想法,同时也希望阅读本文的读者也可以学习到如何比对模型结构变化。
本文撰写于4月21日,后期如果Qwen3的技术报告发布,我们也会持续跟进分析。对文章中的分析可能存在不足的地方,欢迎大家讨论和提出改进意见。如发现错误或者不足之处也可以通过邮件 contact@swanlab.cn 告知笔者~

改进总结
首先,我们先速览一下,Qwen3 相比 Qwen2/2.5 改进了哪些地方(根据公开信息)。具体细节如下表所示:
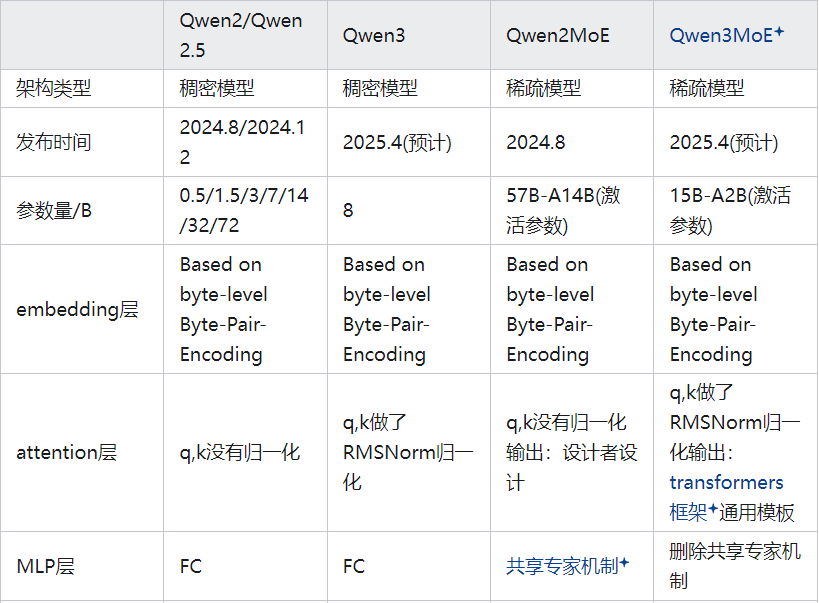
Qwen3和Qwen3MoE模型的Attention层中都对q和k进行了归一化处理
Qwen3-8B的模型参数量比Qwen2.5-7B增加了约1B
Qwen3和Qwen3MoE模型默认支持滑动窗口缓存
Qwen3MoE模型集成transformers框架的flash-attention模块
Qwen3MoE删除了共享专家模式
前置知识
Qwen2、Qwen2.5、Qwen3模型规格一览
笔者做了一个表格,方便大家直接了解Qwen2到Qwen3系列模型的模型架构和参数分布分布。
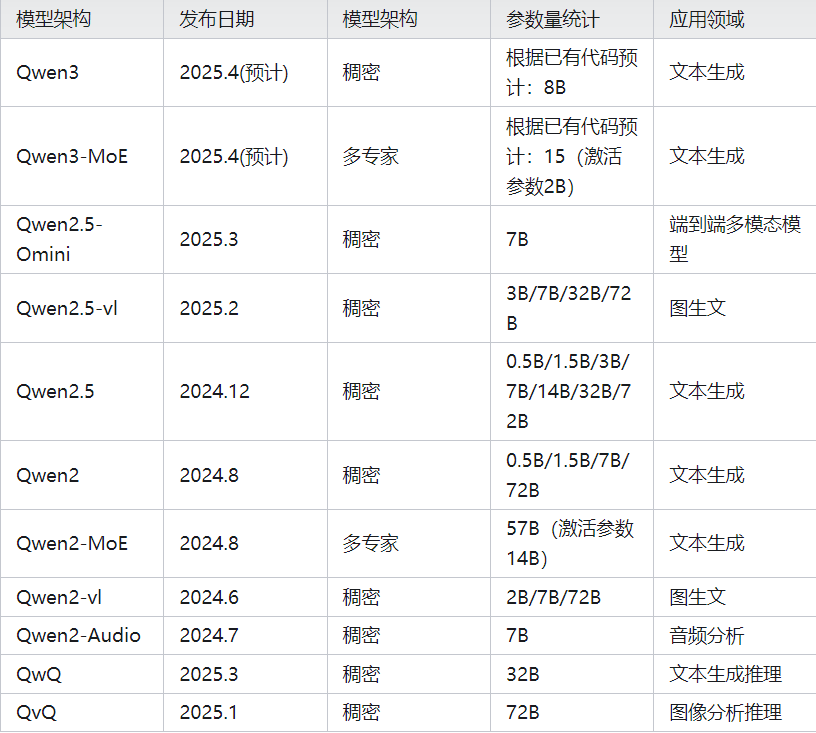
⚠️注意:截止本文撰写日期为止,Qwen3系列并未公开其权重,因此上表Qwen3、Qwen3-MoE为代码中已公开大小,实际上种类应该会更为丰富。
Qwen2.5相比于Qwen2
Qwen2.5相比于Qwen2在训练阶段使用了不同的数据集,然后对模型的初始参数修改了下,结构上直接使用Qwen2的结构,而Qwen2.5的技术报告剩下的50%基本都在讲和其他模型的对比评估结果,因此Qwen2.5的技术报告给出的信息较少,总结下面几点:
预训练数据集增加,从Qwen2的7T tokens增加到18T tokens。
模型支持高达 128K 的上下文长度,可生成最多 8K 内容,并拥有强大的多语言能力,支持 29 种以上语言。
在数学推理等问题上相比于其他的主流模型评分要高。
Qwen2相比于Qwen2MoE
稠密模型(比如Qwen3、Qwen2.5系列模型等)是在模型的结构或激活过程中,全部参数或模块被激活;稀疏模型(MoE模型)在模型的结构或激活过程中,只有部分参数或模块被激活,而不是全部。之所以使用MoE模型,是因为其训练时计算速度比稠密模型要快,而且在相同激活参数条件下MoE收敛速度快,适合大规模训练,因此Qwen2除了有稠密模型也有稀疏模型。
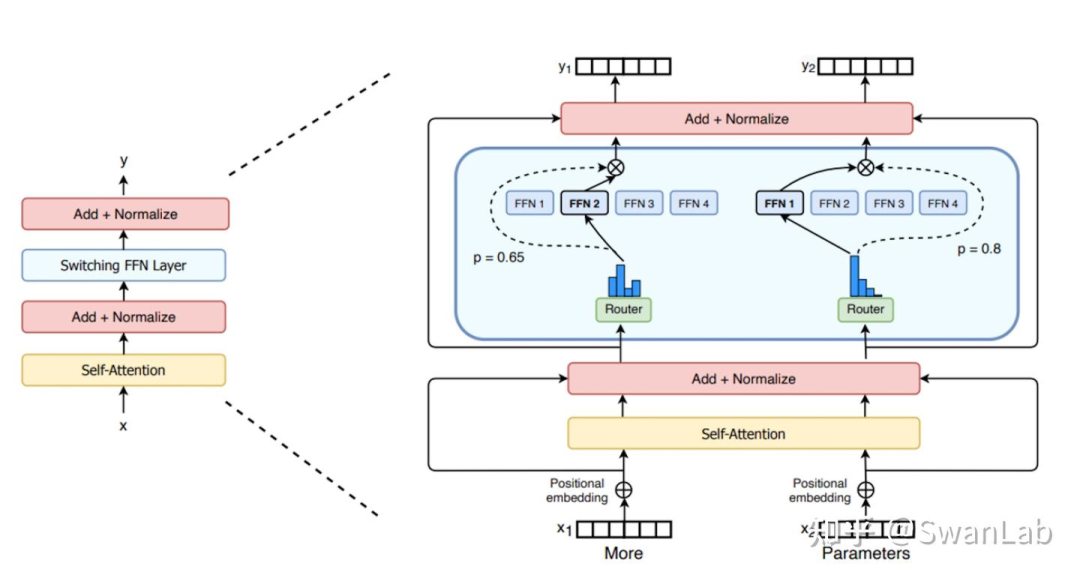
需要注意的是,我们通常所见的MoE(Mixture of Experts,混合专家模型)是稀疏模型的一种具体实现,它通过将复杂的任务分解为多个子任务,并由多个“专家”模型分别处理这些子任务。MoE的核心思想是通过稀疏激活机制,仅激活部分专家来处理当前输入,从而提高计算效率。混合专家模型的一个显著优势是它们能够在远少于稠密模型所需的计算资源下进行有效的预训练。这意味着在相同的计算预算条件下,您可以显著扩大模型或数据集的规模。特别是在预训练阶段,与稠密模型相比,混合专家模型通常能够更快地达到相同的质量水平。
笔者这里打个比方,稠密模型可以类比于一个专家来处理所有tokens的训练,那么如果用一块卡来训练的话,这里可以假设显存占用率有80%,而稀疏模型有多个专家,每个专家在训练过程中可能只负责其中的几个tokens,比如输入总共是100tokens的话,那么假设有10个专家,假设每个专家处理相同数量的tokens,那么每个专家可能只负责处理其中10个tokens,假设每个专家分别挂载到不同的卡上,那么每个专家的显存占用率可能只有8%(参考稠密模型的),这样可以明显降低计算资源,提高训练效率,但是需要注意的是,由于不同专家分配到了不同的设备上,因此对卡间带宽的要求较高。
简单来说:
稀疏 VS 稠密
与稠密模型相比, 预训练速度更快
与具有相同参数数量的模型相比,具有更快的 推理速度
需要 大量显存,因为所有专家系统都需要加载到内存中
在 微调方面存在诸多挑战,但 近期的研究 表明,对混合专家模型进行 指令调优具有很大的潜力。
稀疏模型适用于拥有多台机器且要求高吞吐量的场景。在固定的预训练计算资源下,稀疏模型往往能够实现更优的效果。相反,在显存较少且吞吐量要求不高的场景,稠密模型则是更合适的选择。
Qwen2与Qwen2MoE的代码层面改动
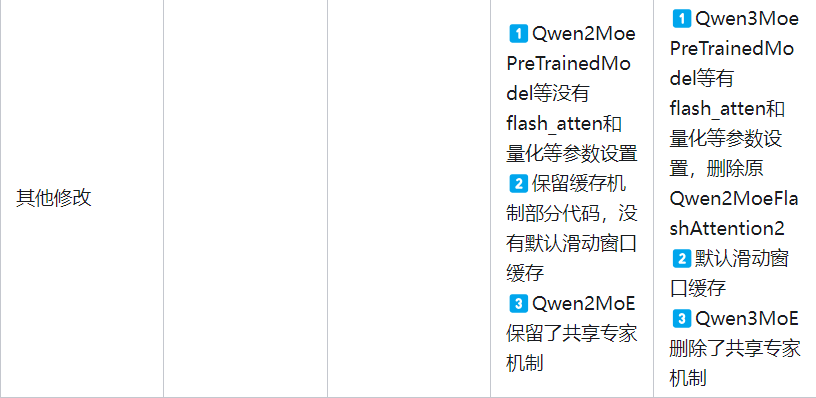
Qwen2MoE相比于Qwen2仅有FFN处进行了改动,Qwen2MoE将原有的MLP处改成了只要专家数量>0就走Qwen2MoeSparseMoeBlock函数也就是混合专家模块,并且需要注意的是,该模块使用了共享专家机制,该机制是DeepSeek团队在V2技术报告里提到的,如下图所示:
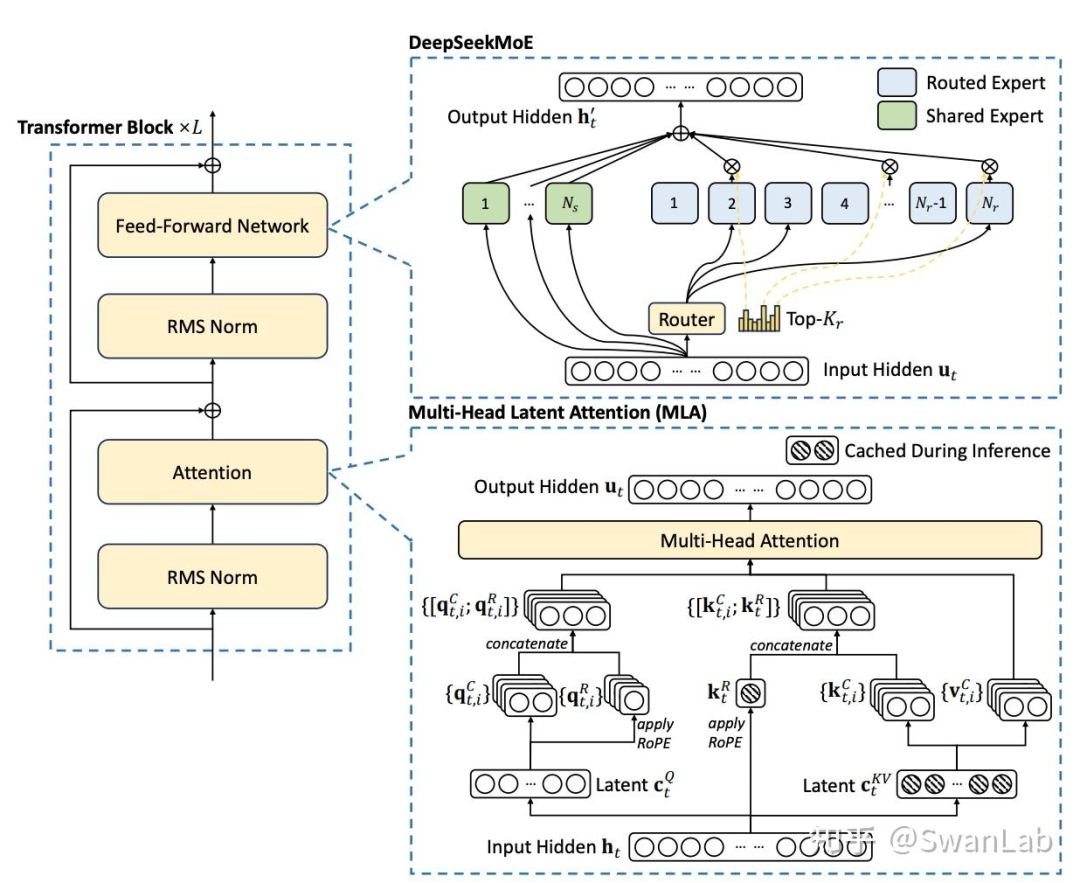
共享专家机制简介:传统路由策略中,分配给不同专家的Token可能蕴含一些通用知识或信息。不同的专家可能会在各自的参数中获得这些通用知识,从而导致专家参数的冗余。若有专门的共享专家来捕捉和整合上下文中的通用知识,将缓解其他路由专家之间的参数冗余。这种冗余参数的减少有助于由更专业的专家构建更加参数高效的模型。为实现该目标,deepseek团队在细粒度专家划分的基础上进一步隔离一部分专家作为共享专家。无论路由模块如何,每个Token都将会被送入这部分共享专家。为保证恒定的计算成本,激活的路由专家将减少相应的数量,如上图所示。
不过根据Qwen3提交的PR代码来看,Qwen3MoE中取消了共享专家机制,这个在后文有所分析。
Qwen3的改动
我们直接可以对比下transformers集成代码中,位于src/transformers/models的Qwen2和Qwen3中的modeling_qwen.py文件看看具体代码信息变动。根据代码分析此次模型的变动如下:
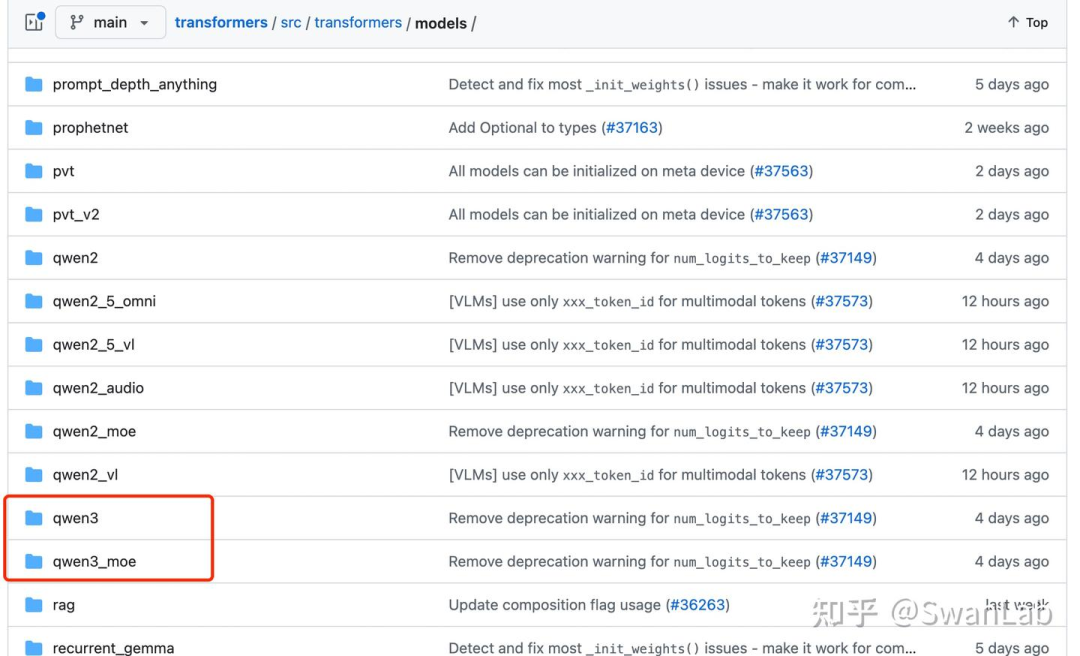
1、模型任务领域
从下图中可以看出,Qwen3系列模型应该是文本模型而非图文模型,并且发布稠密模型和混合专家模型,目前没有看到有vl模型还有O模型(端到端多模态模型)的代码更新。
当然,由于Qwen2.5发布了O模型(Qwen2.5-Omini),笔者也认为Qwen3会有多模态模型的更新,目前还没有和transformers进行集成,可能要再等一段时间,之前的Qwen2的vl模型和文本模型相差了一个多月,那么如果Qwen3有vl的模型的更新,笔者猜测应该要需要等文本模型更新后了。
PS:
Qwen2.5似乎有些pr,看了之后感觉是把一些模型的名字改了下,没有结构上的大修改,因此不必在意,我们就只看下Qwen3即可。
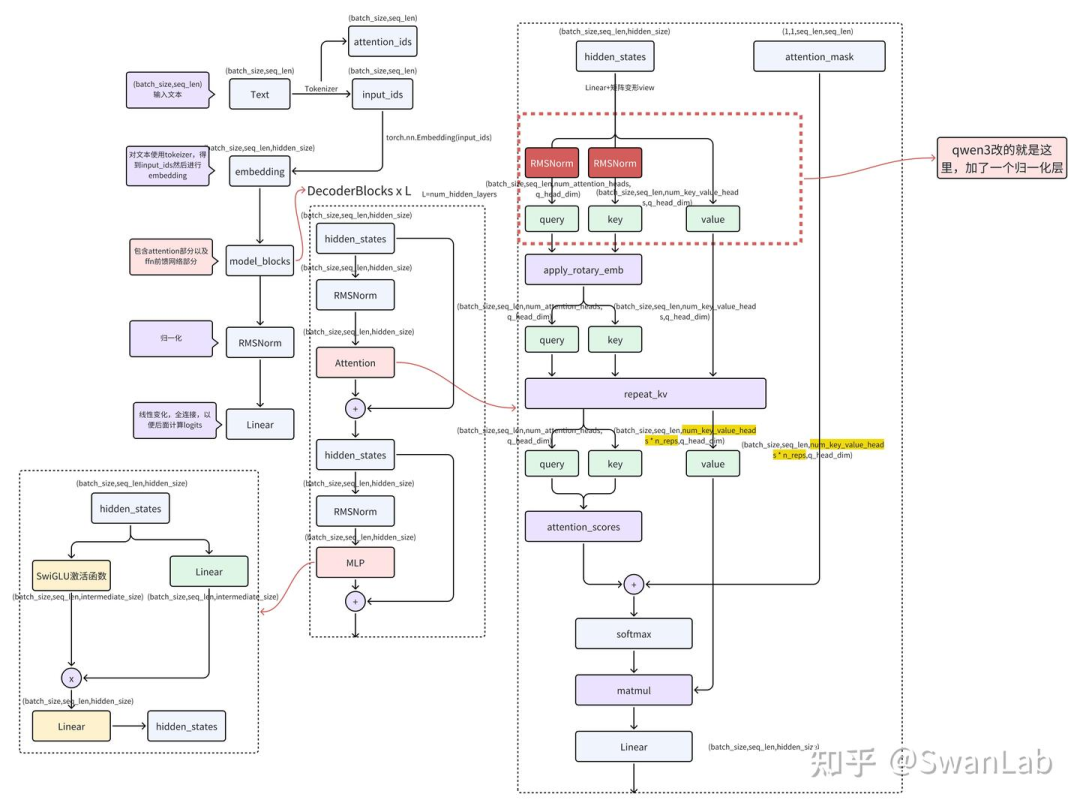
2、注意力机制改动
我们从代码对比中可以看到,在attention部分的初始化定义了归一化部分,使用的是RMSNorm函数,和Qwen2一样,但是在原Qwen2中是的DecoderLayer才有,是对到attention层和mlp层的输入进行归一化,这种归一化方式通过去除输入的尺度差异,提升了训练的稳定性和收敛速度,同时增强了模型对不同尺度输入的适应性,从而提高泛化能力。公式如下:
Attention(Q,K,V)=Softmax(\frac{RMSNorm(Q)·RMSNorm(K)^T}{\sqrt{d_k}})·V使用
RMSNorm的原因估计是降低计算成本,因为RMSNorm仅需进行一次平方和、一次平方根和一次除法运算,这使得相比其他正则化方法其在计算上更加高效,因此在LLM上更受欢迎(此前Qwen2、包括新的LLaMA都使用了RMSNorm)。
Qwen3在attention层中对输入进行进一步的归一化处理,这里笔者猜测可能是想进一步提升训练的稳定性,笔者估计这么做的原因是因为Qwen3的模型参数(尤其是层数)方面会有进一步增长。
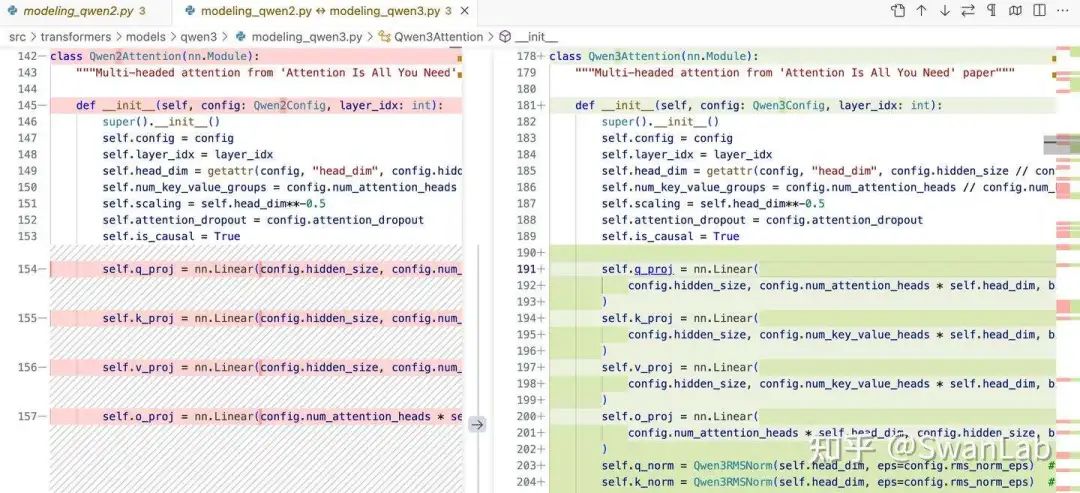
具体代码:
## 初始化部分
self.q_norm = Qwen3RMSNorm(self.head_dim, eps=config.rms_norm_eps)
self.k_norm = Qwen3RMSNorm(self.head_dim, eps=config.rms_norm_eps)
## 前向传播
query_states = self.q_norm(self.q_proj(hidden_states).view(hidden_shape)).transpose(1, 2)
key_states = self.k_norm(self.k_proj(hidden_states).view(hidden_shape)).transpose(1, 2)用结构图展示下具体变动,其中红色部分是修改的地方:
3、模型参数量
在模型结构中一般不太会写模型参数量,一般都是在设定参数的时候才有,但是我们可以从代码中找到一点相关信息。

看样子有个8B参数量的模型,然后我们可以从Qwen2.5的模型仓库中发现没有8B参数量的模型,然后一般src/transformers/models/configuration_qwen2.py是模型结构参数初始化的文件,而观察了configuration_qwen3相比于configuration_qwen2的初始化参数后发现好像只更改了名字,虽然新增加了head_dim,但是和原来的是一样的,同时新增加了attention_bias参数,原来是默认的False,如下图所示。

所以从初始化参数看不出为什么Qwen3是个8B的模型,而不是原来7B的。
这里笔者猜测一下此次变大的原因——主要是Embedding层参数量占比过高导致的。根据Qwen2.5的技术报告来看,Qwen2.5的Embedding层的词表大小148k大小左右,占据了7B参数量的接近7%,约为0.5B,换句话说No-embedding参数量仅为6.5B。这导致了Qwen2.5模型相比于同代数的是模型如Gemma2-9B(No-embedding参数8.2B)或者Llama3-8B(No-embedding参数7.5B)参数量要小得多。
笔者猜测Qwen团队在构建Qwen2系列模型时为了维持模型7B的参数量,模型是做了部分删减的。这在Qwen的层数也能看出来——Qwen2.5-7B仅有28层,维度也仅为3584,对比Llama3-8B的层数32,维度为4096要小得多。因此在Qwen3的设计中,估计Qwen团队将直接让其No-embedding参数与业界主流模型保持一致,来取得更优秀的效果。
从这个稠密模型的参数量相比于Qwen2的变化来看,估计模型仓库里的模型整体上都有参数量的提高(相比于Qwen2或2.5系列单个模型多0.1B-1B左右)。
关于LLM的参数配置,有一篇很有意思的论文MobileLLM做了详细的研究和实验。 Scaling Law在小模型中有自己独特的规律。 引起Transformer参数成规模变化的参数几乎只取决于
d_model和n_layers
d_model↑ +n_layers↓ -> 矮胖子d_model↓ +n_layers↑ -> 瘦高个
MobileLLM提出在较小的模型上深度比宽度更重要,「深而窄」的「瘦长」模型可以学习到比「宽而浅」模型更多的抽象概念。 例如当模型参数固定在125M或者350M时,30~42层的「狭长」模型明显比12层左右的「矮胖」模型有更优越的性能, 在常识推理、问答、阅读理解等8个基准测试上都有类似的趋势。不过这种趋势一般存在于较小的模型,在较大的模型上比例关系对于性能的影响并非非常明显。
明确支持滑动窗口(sliding window)机制
在 Qwen3Attention 类中,Qwen3 明确检查了是否启用了滑动窗口机制,并在必要时调整了注意力的计算方式。
具体代码:
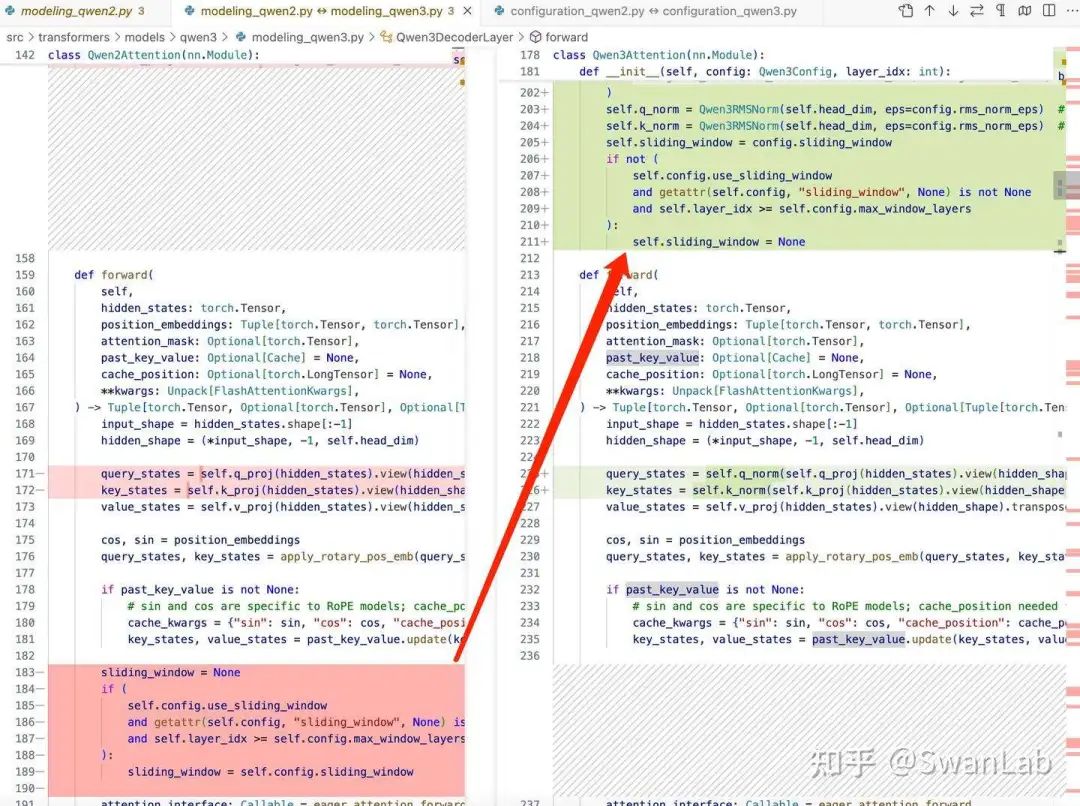
这里应该只是改成了初始化部分定义,能更方便调用,并且和原来不一样的是,Qwen3的滑动窗口是默认开启,原来Qwen2是默认不用滑动窗口,如果当前层的索引小于 max_window_layers,则表示当前层不在滑动窗口机制的范围内,因此也禁用滑动窗口机制。滑动窗口机制通常用于处理长序列数据,以提高计算效率和减少内存占用。
笔者猜测使用默认滑动窗口的原因是Qwen3将支持更长的上下文长度(业内比如MiniMax上下文长度支持到了恐怖的4M,Llama4 Scout更是到了10M,而DeepSeek-V3的文本长度也达到了128k),Qwen3的文本长度大概率会持平或者超过128k。更长的上下文本长度对于采用R1这种强化学习训练方法更有帮助,比如Llama4文本长度达到了256K,因此此次Qwen3很可能会进一步升级文本长度。
4、Qwen3MoE相比于Qwen2MoE
参数量变化

图9.Qwen2-MoE模型和Qwen3-MoE模型的结构代码对比(模型参数量部分)
根据提交的代码来看,Qwen3MoE模型的最小参数量将达到15B(激活参数2B),能方便更多研究者进行研究。
根据此前Qwen1.5-MoE模型(14.7B)的结构估计,最小Qwen3MoE模型猜测是64专家、每个token路由4个专家的MoE模型。感兴趣的同学可以提前参考Qwen1.5-MoE模型的config文件,不过Qwen1.5-MoE采用了共享专家策略,因此其激活参数为2.7B,与Qwen3-MoE代码中记录的2B有些许区别。
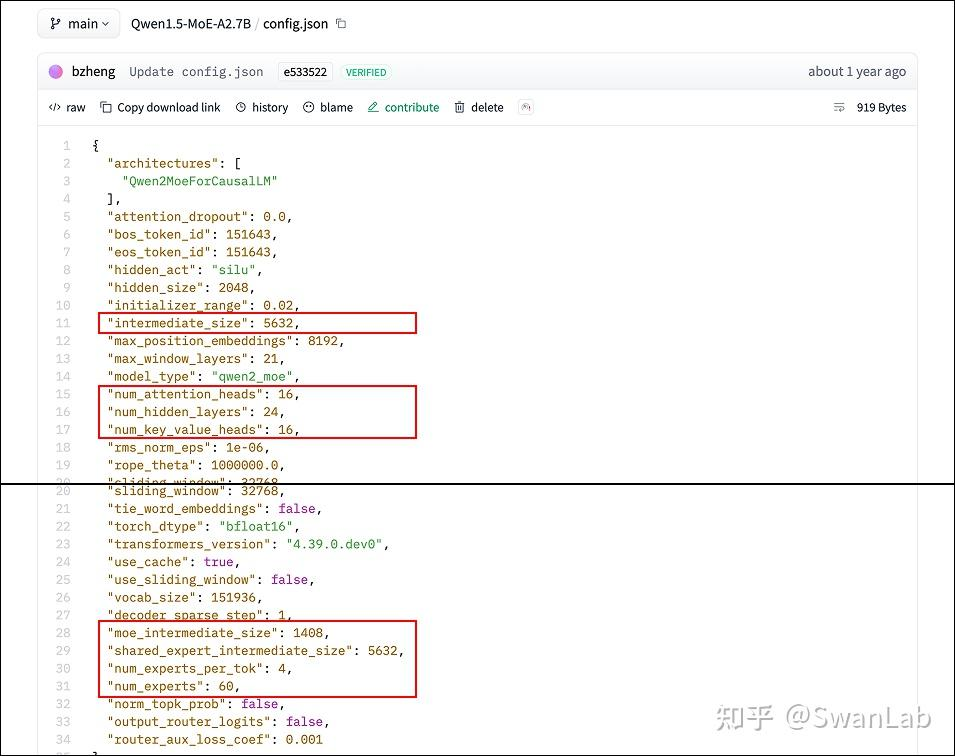
在Qwen3MoE的config中发现默认参数的专家数量是128,每个token分配的专家数量是8,然后Qwen2MoE的config中默认参数的专家数量是60,
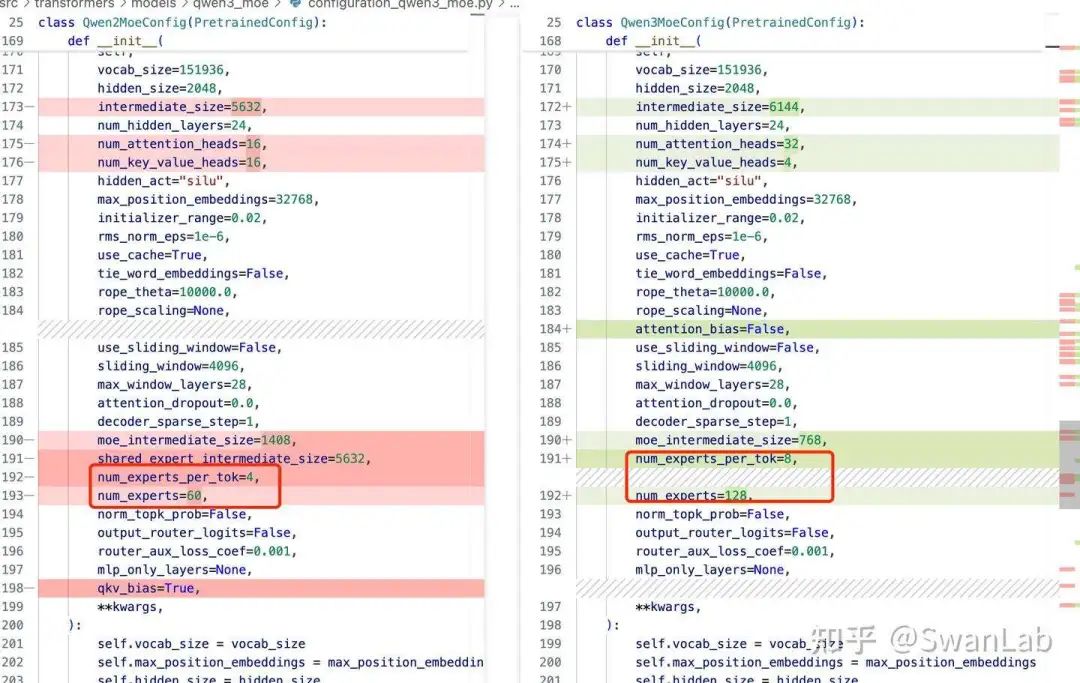
每个token分配的专家数量是4,由于Qwen3MoE模型的默认参数是15B-A2B,因此笔者认为Qwen1.5-MoE模型的专家数量更具有参考价值,而笔者之前也猜测Qwen3MoE模型不一定只有15B的参数量,有可能有更大参数量的模型,因此认为15B-A2B的模型仍然可以参考Qwen1.5-MoE的参数配置,也就是专家数量是60,每个token分配的专家数量是4。
当然了,估计Qwen3MoE除了发布15B-A2B大小的模型,还会发布更大的MoE模型,期待Qwen团队后续的权重公开。
attention层部分改动
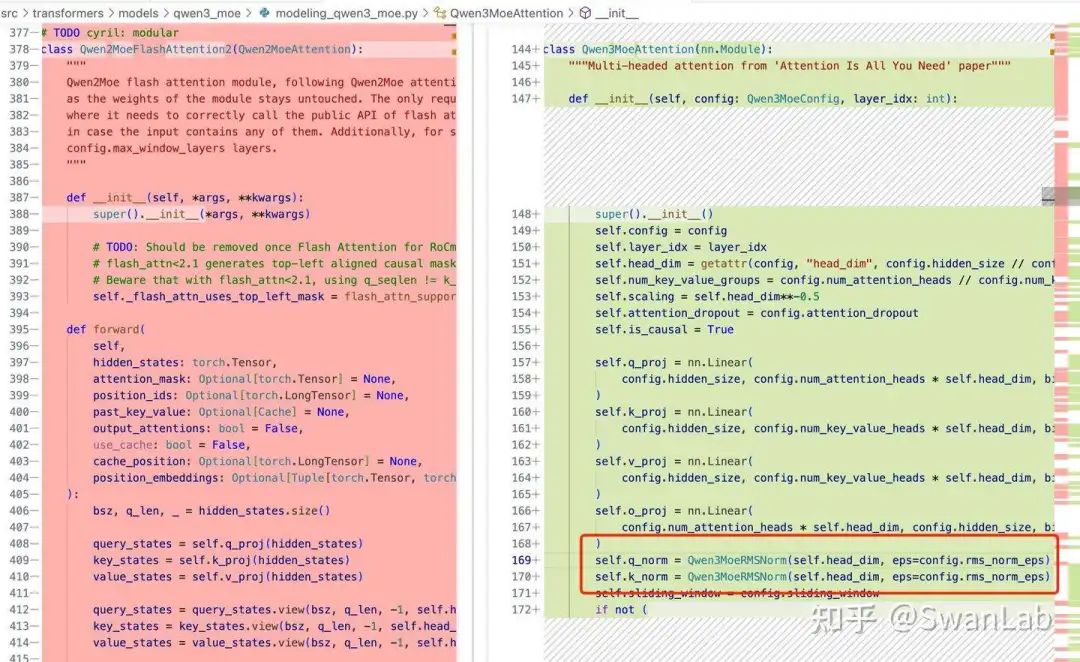
1. 归一化层
moe的attention部分和Qwen3一致,都是对输入部分进行了RMSNorm归一化处理,因此该部分的结论和上面一样,应该也是降低计算成本,提高模型泛化能力,避免在训练过程中出现梯度爆炸或消失的问题。
1. 输出层部分改动
相比于Qwen2,Qwen3应该是对attention输出权重矩阵适配了统一函数做了一些改动,可以看到ALL_ATTENTION_FUNCTIONS函数应该是在transformers的通用模板中,这么做的目的应该是和transformers框架做更好的适配。
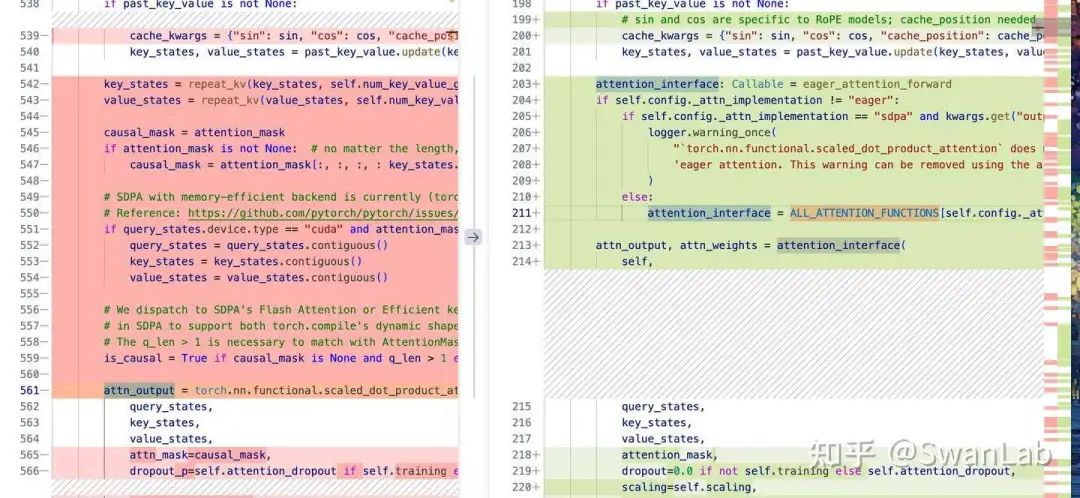
这么看,Qwen3_moe相比于Qwen2_moe删减了很多,而大部分的处理应该和ALL_ATTENTION_FUNCTIONS重叠,或者最终效果一致,那么Qwen应该是做了相应的适配。
注意:
在Qwen3_moe的参数初始化中,有一个self.scaling参数,在上图右下角也有,Qwen3Moe 中的 self.scaling 是通过 self.head_dim**-0.5 计算的,而 Qwen2Moe 中是通过 math.sqrt(self.head_dim) 计算的。
MLP层改动
删除共享专家机制
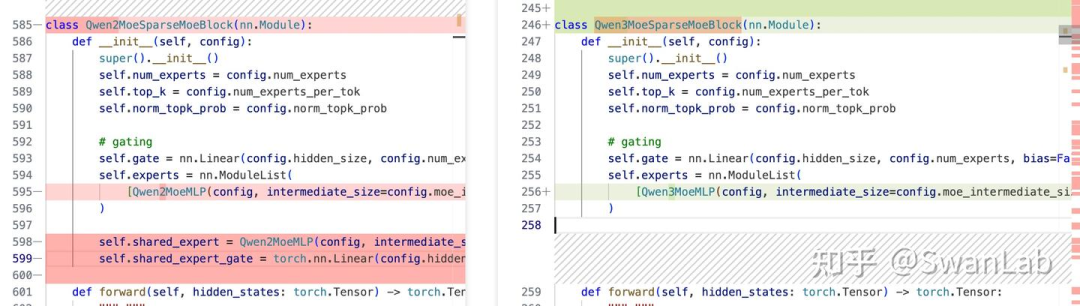
从对比代码中看,Qwen3_moe删除了共享专家部分,这里猜测Qwen团队应该是做了相关的实验,笔者之前也猜测15B应该是他们MoE的最低门槛参数量的模型,应该还有更大的模型,而该模型框架要适配他们所有的MoE模型的,因此应该是有没有共享专家机制都不会影响最终的模型性能,而使用了共享专家机制的话shared_experts需要过多的资源,其他的专家所在的设备有可能不能有效利用,因此综合考虑之后Qwen团队选择直接删掉该模块也是合情合理的。
共享专家机制在deepseek-v2模型中被引入,V3和R1都有很好的应用,关于共享专家可在Qwen2相比于Qwen2MoE中看到。
直观上采用共享专家这种方式可以结合稠密网络和稀疏网络的优点。但是共享专家也有些潜在的缺点:
训练和推理的计算框架变得更为复杂,需要专门针对共享专家处进行优化。
Qwen团队可能在实际验证后发现共享专家不一定有很好的效果提升,因此Qwen团队就直接简化处理了。
模型应用层
Qwen3MoEPreTrainedModel
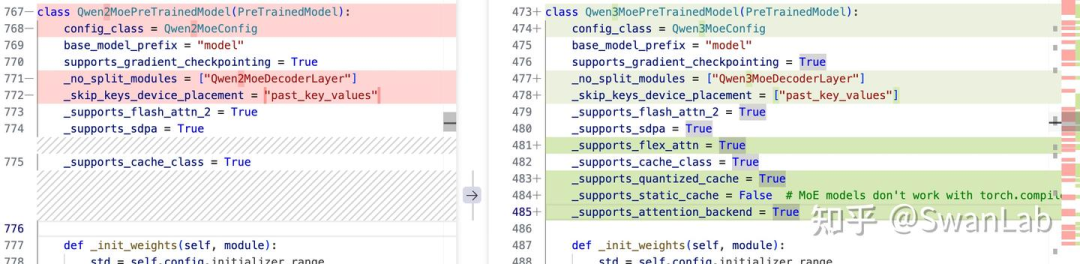
相比于Qwen2,Qwen3增加了一些属性和对特定功能的支持,这些变化反映了 Qwen3MoE 模型在设计和实现上的改进。以下是详细的对比和分析:
新增功能:
灵活的注意力机制:
_supports_flex_attn表示Qwen3MoE支持灵活的注意力机制,可以动态调整注意力的计算方式。量化缓存:
_supports_quantized_cache表示Qwen3MoE支持量化缓存,可以减少内存占用,提高推理速度。属性值的变化:
更灵活的缓存处理:
_skip_keys_device_placement从字符串改为列表,支持更复杂的缓存机制。明确不支持静态缓存:
_supports_static_cache明确为False,表明Qwen3MoE更侧重于动态缓存机制。支持注意力后端:
_supports_attention_backend表示Qwen3MoE支持多种注意力实现方式,提高了模型的灵活性和性能。
这些变化反映了 Qwen3MoeE 模型在设计上的改进,特别是在处理长序列、动态缓存和灵活注意力机制方面的优化。这些改进有助于提高模型的效率、适应性和实际应用中的性能。
Qwen3MoEModel
首先,对于缓存机制,删除了很多代码,左下方已经给出是因为要适配transformers新的框架做了修改,效果和原来一致,都是动态缓存机制。
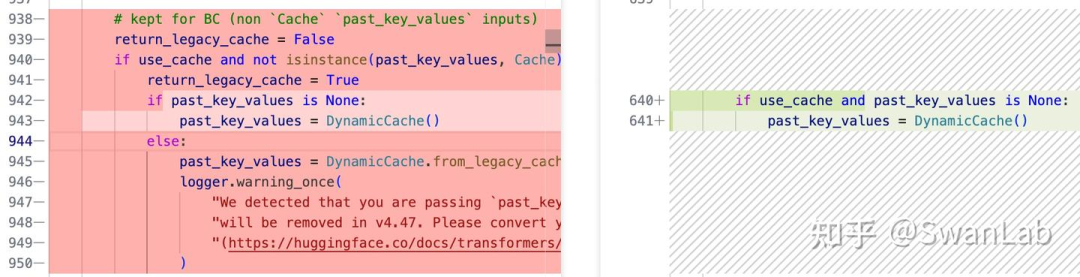
其次,我发现在该函数里,在初始化以及前向传播函数中多次提到flash_attention的相关参数flash_attn_kwargs,在 Qwen3MoEModel 中引入 flash_attn_kwargs 参数是为了提供更灵活的注意力机制实现方式。flash_attn_kwargs 是一个字典,包含了用于配置和优化注意力计算的各种参数。这种设计允许模型在运行时动态调整注意力机制的实现细节,以适应不同的硬件环境和任务需求,不仅提高了模型的性能和内存使用效率,还为未来的扩展提供了便利。
具体代码:
# forward参数初始化
**flash_attn_kwargs: Unpack[FlashAttentionKwargs],
# layer输出
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
partial(decoder_layer.__call__, **flash_attn_kwargs),
hidden_states,
causal_mask,
position_ids,
past_key_values,
output_attentions,
output_router_logits,
use_cache,
cache_position,
position_embeddings,
)
else:
layer_outputs = decoder_layer(
hidden_states,
attention_mask=causal_mask,
position_ids=position_ids,
past_key_value=past_key_values,
output_attentions=output_attentions,
output_router_logits=output_router_logits,
use_cache=use_cache,
cache_position=cache_position,
position_embeddings=position_embeddings,
**flash_attn_kwargs,
)注意:
Qwen3_MoE直接删除了Qwen2MoeFlashAttention2部分,而结合上面说的,在Qwen3MoEModel中加入了flash_attention参数,应用于前向传播计算当中,以及说的简化模型结构,这里猜测是设计值直接默认使用flash_attention加速模型推理,从而使得15B的模型能够实现MoE的基本功能。
笔者总结
Qwen3和Qwen3MoE模型的Attention层中都对q和k进行了归一化处理,估计是为了提升训练的稳定性,以支持更大尺寸模型的训练
Qwen3-8B的模型参数量比Qwen2.5-7B增加了约1B,估计是为了平衡embedding参数占比过大的问题
Qwen3和Qwen3MoE模型默认支持滑动窗口缓存,估计是为了支持更大的上下文长度
Qwen3MoE模型集成Flash Attention 2和SDPA加速,比Qwen2MoE的规范性和兼容性更好
Qwen3MoE并没有使用Qwen2MoE中的共享专家模式
题外话
该文章也会发布在SwanLab微信公众号上,SwanLab是我们团队的核心产品,用于模型训练跟踪和可视化分析,可以访问https://docs.swanlab.cn/了解,有兴趣的小伙伴可以多多关注。

参考文章
Qwen3 即将推出!
Qwen3即将发布?深度研究报告——解析阿里巴巴新一代大语言模型的技术革新与行业影响
【大模型】大模型中的稀疏与稠密——一场效率与性能的较量
Qwen 技术报告
手搭一个qwen模型--CSDN
qwen2.5技术报告--知乎
qwen2模型分析--CSDN
Qwen2.5-1M Technical Report
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Llama-4-Maverick-17B-128E-Instruct
LLaMA3初步解读:ScalingLaw颠覆之作,弱智吧挑战及格!
详解SwiGLU激活函数
1-transformer_model/llm参数量-计算量-显存占用分析.md
Qwen1.5-MoE-A2.7B模型配置
附录:如何获得Qwen3模型结构信息
途径一:技术报告
一般来说,想这些模型在发布的时候,会有该模型的技术报告一起发出,比如qwen2.5的技术报告如下图所示,链接在这:
如果模型在版本更迭的时候有结构上的变化,一般在技术报告里能找到,而如果没有结构的变化,一般技术报告也会写出预训练和微调等超参数设置、sacling law等,当然也包含评估模型的分数等。
途径二:开源社区模型仓库
而如果没有技术报告,那么如果在模型结构上有很大的变动的话,在开源社区的模型仓库也可以找到,比如deepseek-r1,是找仓库中的modeling_deepseek.py,其中有embedding、attention等代码结构,可以直接找到。
途径三:transformers集成
如果上述都没有找到模型结构信息,那么也可以从各个开源框架中寻找是否有模型集成的信息,比如我们常用的transformers,一般都是各个模型集成的首选框架,这次的qwen3我们就可以直接从集成的代码中找到结构信息:modeling_qwen3.py
自动驾驶之心
论文辅导来啦

知识星球交流社区
近4000人的交流社区,近300+自动驾驶公司与科研结构加入!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(大模型、端到端自动驾驶、世界模型、仿真闭环、3D检测、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎加入。

独家专业课程
端到端自动驾驶、大模型、VLA、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频
学习官网:www.zdjszx.com

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









