






Gemma3技术总结
简介
Gemma 是一个源自 Google 的轻量级模型系列,该系列依托于先进的 Gemini 技术进行构建。2025 年 3 月 12 日,Google 正式发布了 Gemma 系列的最新一代产品——Gemma 3。这款新一代的 Gemma 模型具有多模态处理能力,不仅能够理解和生成文本内容,还能对图像数据进行分析和处理。Gemma 3 拥有一个宽广的上下文窗口,大小达到 128K tokens,这意味着它可以在单次处理过程中考虑更多的信息。此外,Gemma 3 支持超过 140 种不同的语言,极大地扩展了其应用范围。
Gemma 3 提供了四种不同规模的版本以满足各种需求:从相对较小的 10 亿参数(1B)版本到更强大的 270 亿参数(27B)版本不等。这些不同规模的模型在多种自然语言处理任务中展现出了卓越的能力,包括但不限于问答、文档摘要生成以及复杂的逻辑推理等应用场景。特别值得一提的是,尽管拥有强大的功能,但通过优化设计,即使是较大规模的 Gemma 3 版本也能够在硬件资源较为有限的情况下高效运行,这使得它成为了一款非常适合部署于边缘计算设备或移动平台上的解决方案。
对于那些希望深入了解 Gemma 3 背后技术细节的研究者来说,可以参考以下论文获取更多信息:
Gemma 架构
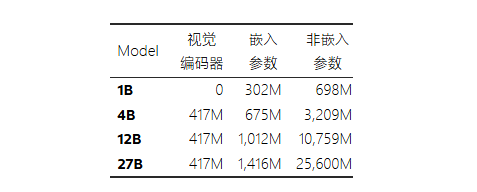
整体架构
GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(256000, 3072, padding_idx=0)
(layers): ModuleList(
(0-27): 28 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=3072, out_features=4096, bias=False)
(k_proj): Linear(in_features=3072, out_features=4096, bias=False)
(v_proj): Linear(in_features=3072, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=3072, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=3072, out_features=24576, bias=False)
(up_proj): Linear(in_features=3072, out_features=24576, bias=False)
(down_proj): Linear(in_features=24576, out_features=3072, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=3072, out_features=256000, bias=False)
)
embed_tokens(嵌入层)
该层将输入令牌(单词或子单词)转换为模型可以处理的密集型数字表征(嵌入)。其词汇量为 256,000,并可创建维度为 3,072 的嵌入。
layers
这是模型的核心部分,由 28 个堆叠的 GemmaDecoderLayer 组件构成。每一层都优化了令牌嵌入,以捕捉单词及其上下文之间的复杂关系。
self_attn
在自注意力 (self-attention) 机制中,模型在生成下一个单词时为输入中的单词分配不同的权重。该模型利用缩放的点积注意机制,并使用线性投影(q_proj、k_proj、v_proj 和 o_proj)来生成查询、键、值和输出表征。
q_proj、k_proj 和 v_proj 的所有 out_features 值都是相同的 4,096,因为该模型使用了多头注意力 (MHA)。该机制有 16 个并行的头,每个头的尺寸是 256,总共为 4,096 (256 x 16)。
此外,该模型通过使用 rotary_emb (GemmaRotaryEmbedding) 进行位置编码(又名 RoPE),来更有效地利用位置信息。
最后,o_proj 层将注意力输出投影回原始维度 (3072)。
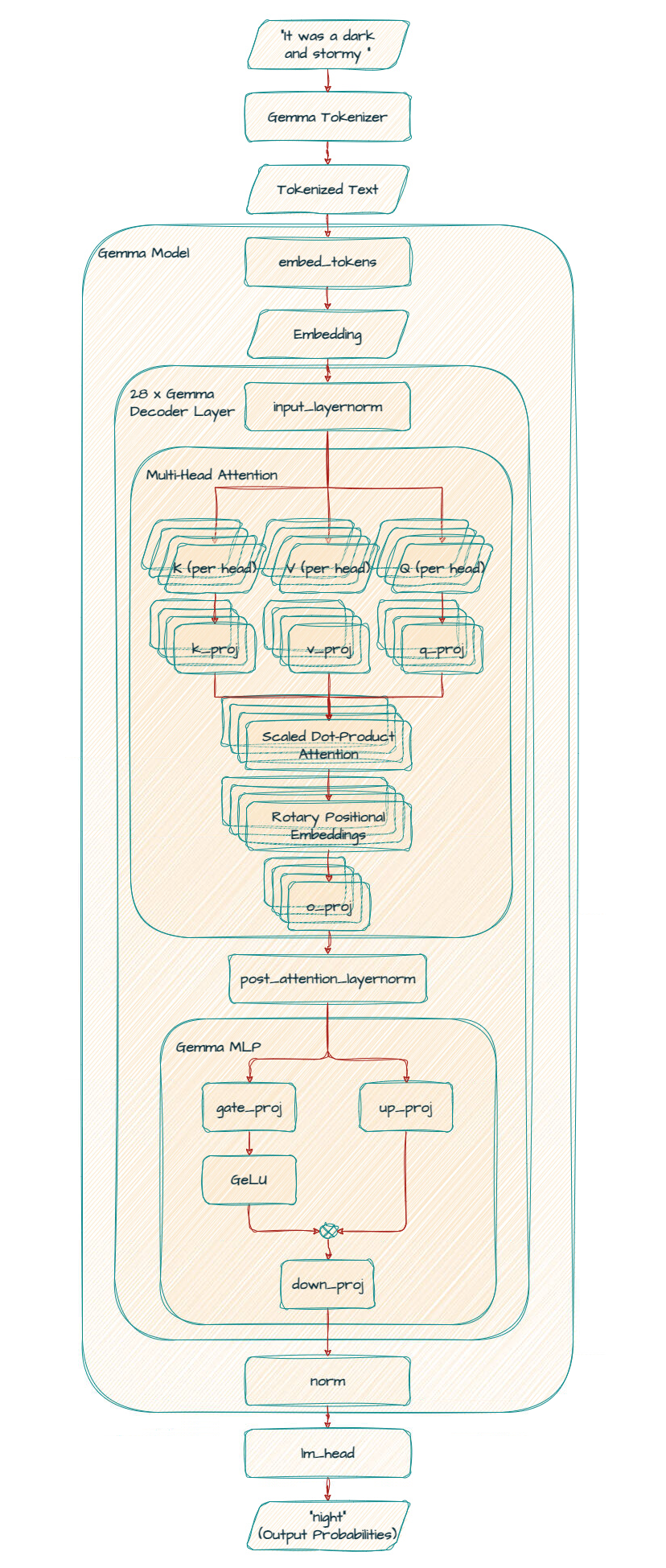
请注意,Gemma 2B 模型使用多查询注意力 (MQA)。
k_proj 和 v_proj 共享相同的头,大小为 256,因此 out_features 为 256。相比之下,q_proj 和 o_proj 有 8 个并行的头 (256 x 8 = 2048)。
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
mlp
此参数利用 gate_proj 和 up_proj 作为门控机制,然后通过 down_proj 将维度降回到 3,072。
归一化
这些归一化层稳定了训练过程,并提高了模型的有效学习能力。
| 术语 | 位置 | 主要目的 |
|---|---|---|
| norm (通常指 LayerNorm) | Transformer 模型各处 (输入、注意力后、FFN后等) | 稳定训练,加速收敛,改善梯度流动,提高性能 |
| input_layer norm | 输入层 (Embedding 后, Positional Encoding 后) | 稳定输入表示,加速训练 |
| post_attention layernorm | 自注意力机制之后 (残差连接之后) | 稳定注意力机制的输出,改善梯度流动,提高模型性能 (Transformer 中非常重要) |
lm_head
此最后一层将经优化的嵌入 (3,072) 映射回整个词汇空间 (256,000) 的概率分布上,以预测下一个令牌。
Gemma3 新功能
功能点
| 特性 | 详情 |
|---|---|
| 构建全球最佳单GPU模型 | Gemma 3 在 LMArena 排行榜的初步人类偏好评估中,表现优于 Llama - 405B、DeepSeek - V3 和 o3 - mini。帮助用户创建适合单 GPU 或 TPU 主机的引人入胜的用户体验。 |
| 支持 140 种语言 | 构建能够使用客户语言的应用。Gemma 3 提供超过 35 种语言的开箱即用支持,并对 140 多种语言提供预训练支持。 |
| 创建具备高级文本和视觉推理能力的 AI | 轻松构建能够分析图像、文本和短视频的应用程序,为交互式和智能化应用开辟新的可能性。 |
| 通过扩展的上下文窗口处理复杂任务 | Gemma 3 提供 128k token 的上下文窗口(相比之下, Gemma 2 的上下文窗口只有 80K),让应用程序能够处理和理解大量信息。 |
| 使用函数调用创建 AI 驱动的工作流 | Gemma 3 支持函数调用和结构化输出,帮助用户自动化任务并构建代理式体验。 |
| 通过量化模型实现更快的高性能 | Gemma 3 引入了官方量化版本,在保持高精度的同时减少模型大小和计算需求。 |
Chatbot Arena Elo 分数
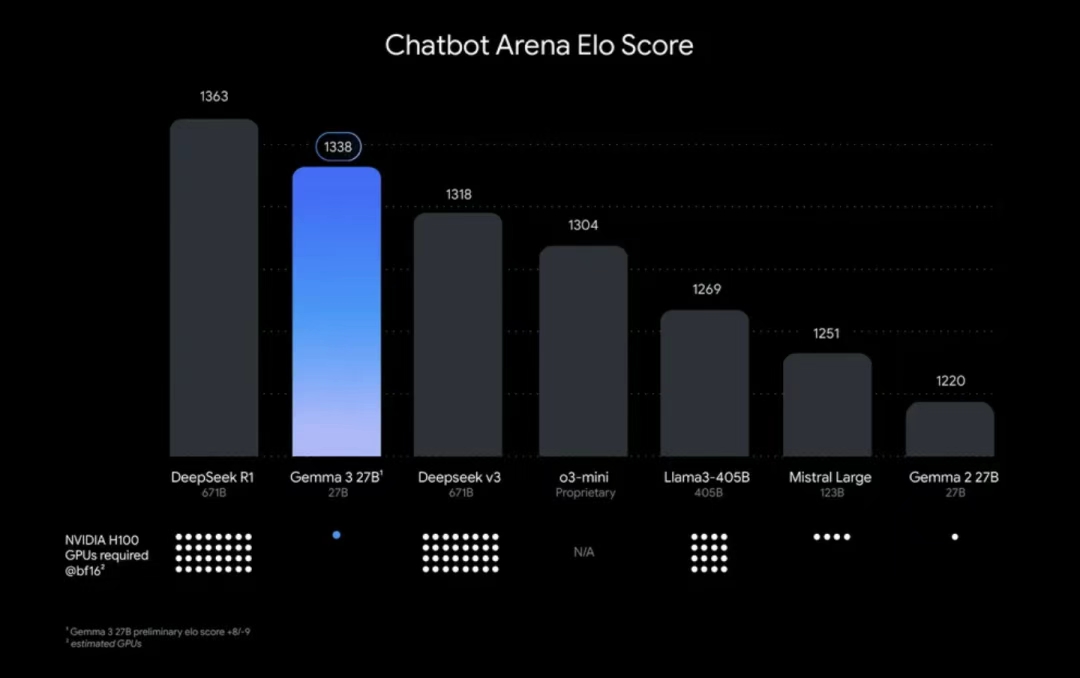
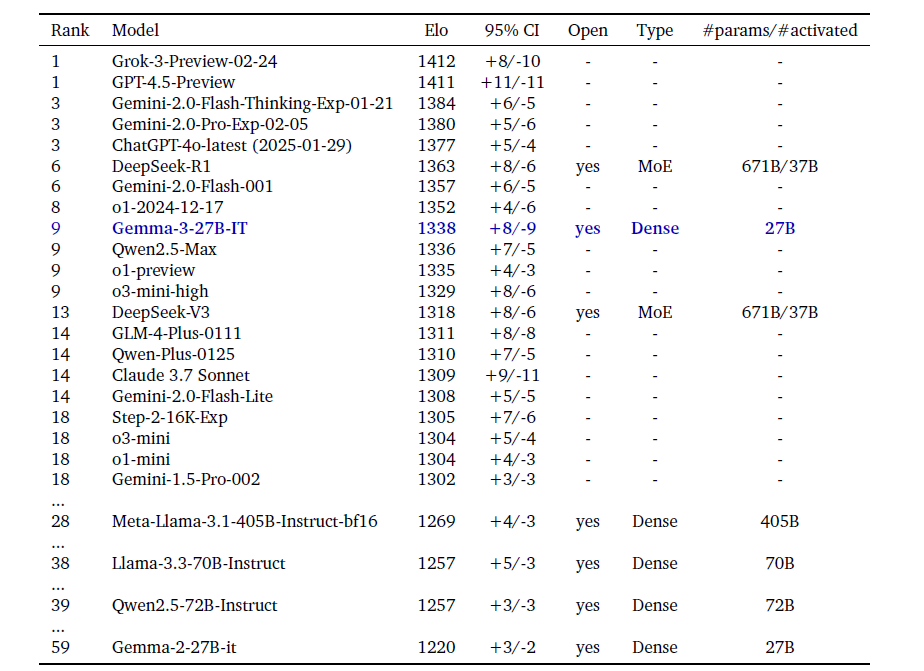
该图表根据 Chatbot Arena Elo 分数对 AI 模型进行排名;分数越高(顶部数字)表示用户偏好越高。圆点表示预估的 NVIDIA H100 GPU 需求。Gemma 3 27B 排名靠前,尽管其他模型需要多达 32 个 GPU,但它仅需单个 GPU 即可运行。
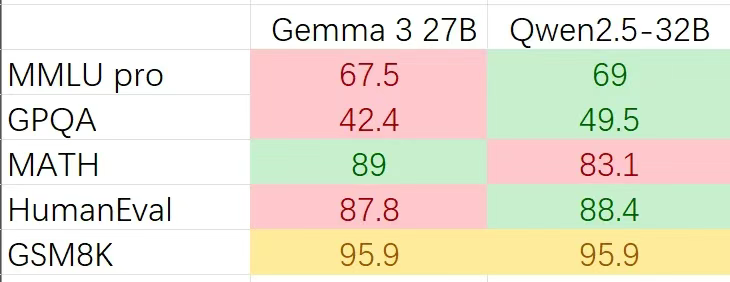
Gemma 3 和 Qwen 2.5 对比
Gemma3 主要特性
架构创新
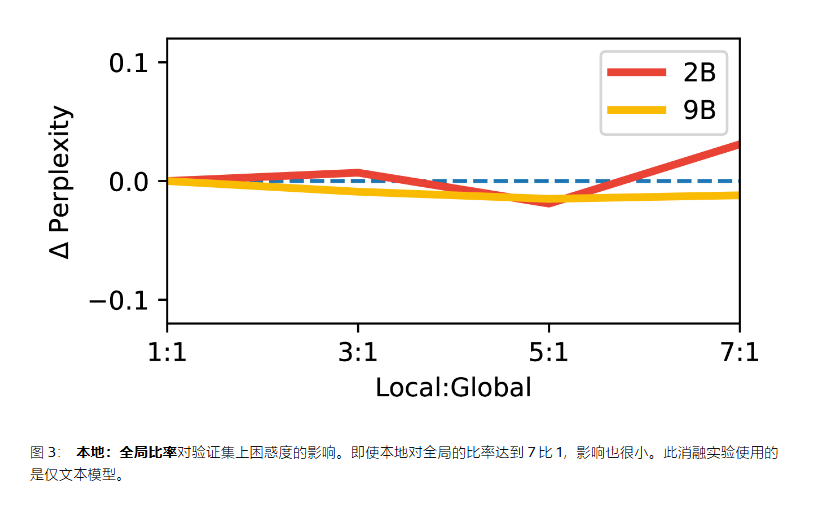
本地:全局注意力层
gemma 2 模型使用的是 1:1,而 Gemma 3 使用的是 5:1。我们观察到更改此比例对困惑度的影响几乎没有。
滑动窗口大小
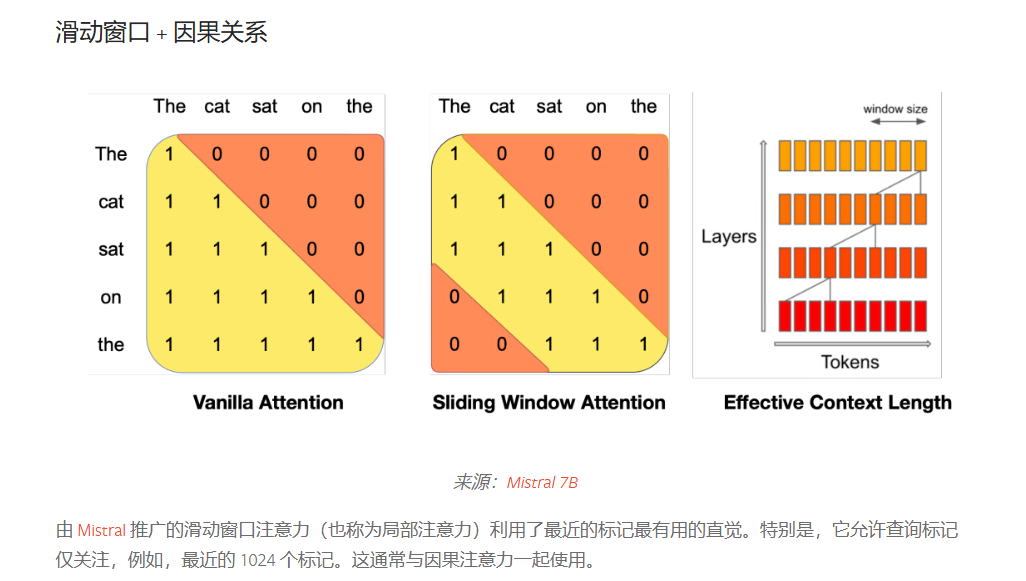
SLIDING_WINDOW = 1024
def sliding_window_causal(b, h, q_idx, kv_idx):
causal_mask = q_idx >= kv_idx
window_mask = q_idx - kv_idx <= SLIDING_WINDOW
return causal_mask & window_mask
# If you want to be cute...
from torch.nn.attention import and_masks
def sliding_window(b, h, q_idx, kv_idx)
return q_idx - kv_idx <= SLIDING_WINDOW
sliding_window_causal = and_masks(causal_mask, sliding_window)
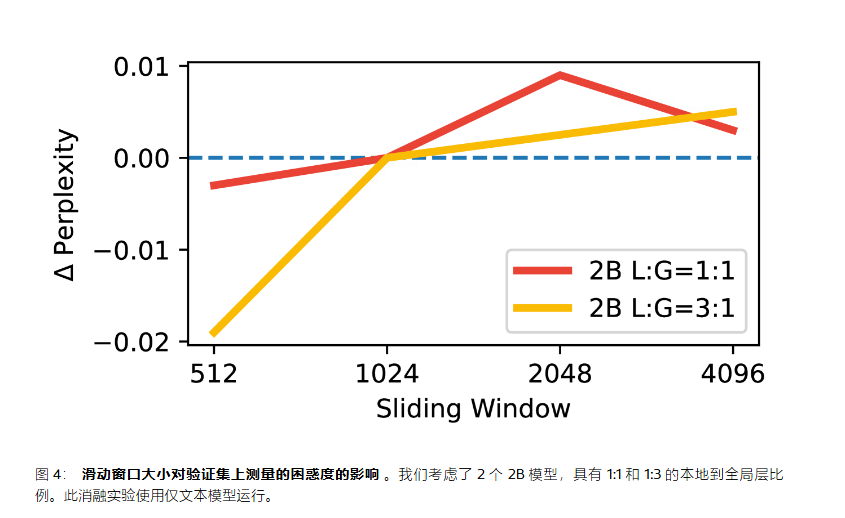
KV 缓存内存的影响
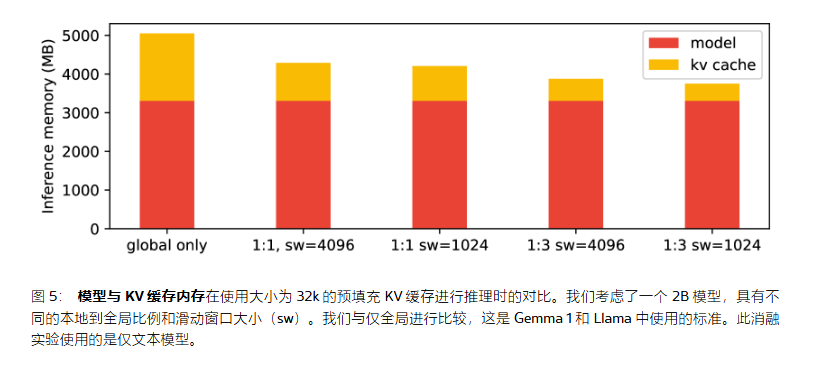
Gemma 2 中使用的是"1:1, sw=4096"配置。我们观察到,"仅全局"配置导致内存开销为 60%,而使用 1:3 和滑动窗口为 1024(“sw=1024”)时,这可以减少到不到 15%。
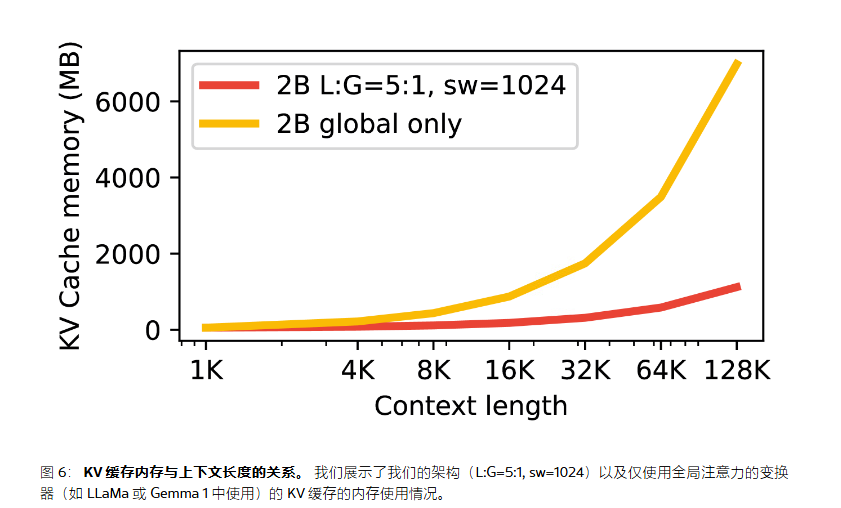
在图 6 中,我们计算了 KV 缓存使用的内存作为上下文长度的函数,使用我们的 2B 架构(L:G=5:1, sw=1024)与"仅全局"的 2B 模型进行比较。
训练细节
- 硬件与框架
- 使用TPU训练
- 结合Zero-3类算法与JAX
- 训练规模
- 27B版本:14万亿tokens
- 12B版本:12T tokens
- 4B版本:4T tokens
- 1B版本:2T tokens
- 后训练优化
- 采用蒸馏技术
- 每个token采样256个logits
- 使用BOND、WARM和WARP算法进行强化学习
对话模板更新
- 强制包含BOS(Begin of Sentence)起始标记
- 采用格式:
<start_of_turn>user<start_of_turn>model

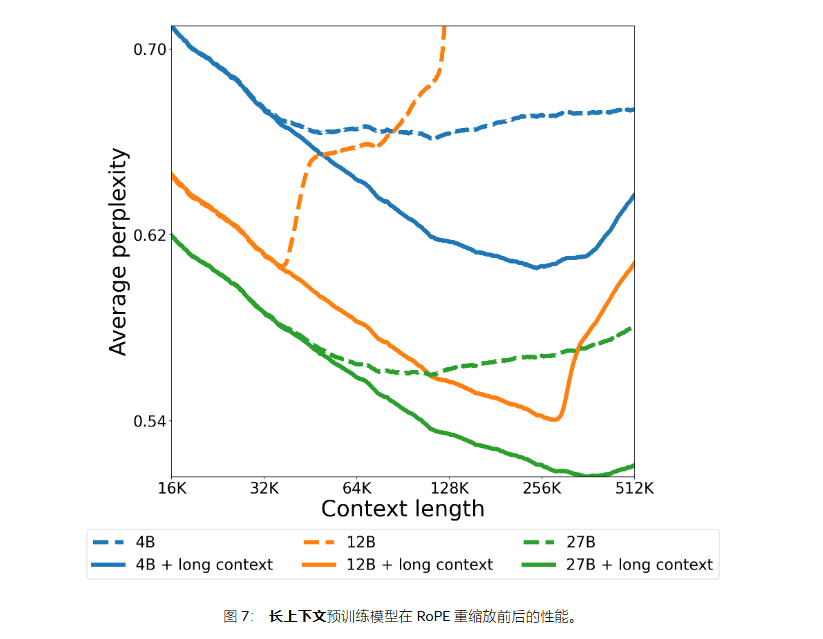
长文本与视觉能力
- 上下文处理
- 训练过程从32K扩展到128K
- RoPE缩放因子:8
- 视觉处理
- 采用"Pan & Scan"算法
- 固定分辨率:896×896
- 使用窗口化支持其他尺寸

1. RoPE基础频率的基本概念
RoPE基础频率是用来控制位置编码的一个重要参数:
- 较低的基础频率(如10,000)会使位置编码变化更缓慢
- 较高的基础频率(如1,000,000)会使位置编码变化更快速
2. 两种注意力层的频率设置
局部自注意力层(Local Attention)
- 基础频率:10,000
- 特点:
- 只关注局部窗口内的信息(如前面提到的1024个token)
- 较低的频率有助于在局部范围内更精确地捕捉位置关系
- 因为处理范围有限,不需要很高的基础频率
全局自注意力层(Global Attention)
- 基础频率:1,000,000
- 特点:
- 需要处理整个序列的信息
- 更高的频率让模型能够更好地区分远距离位置
- 有助于处理长距离依赖关系
为什么要这样设计?
用一个比喻来解释:想象你在看一本书:
- 局部自注意力层(频率10,000)就像是在仔细阅读当前这一页的内容,需要精确理解每个词之间的关系。
- 全局自注意力层(频率1,000,000)则像是在理解整本书的结构,需要能够快速定位和关联不同章节的内容。
通过这种设计:
- 局部层保持较低频率,确保近距离的词之间关系被准确建模
- 全局层使用高频率,帮助模型更好地处理长距离的关系
这种差异化设计有助于:
- 提高模型处理长文本的能力
- 在保持局部精确性的同时,提升全局理解能力
- 平衡计算效率和模型性能
简而言之,这是一种"分工合作"的设计:局部层专注于精细处理,全局层负责长距离关联,两者互补来提升整体性能。
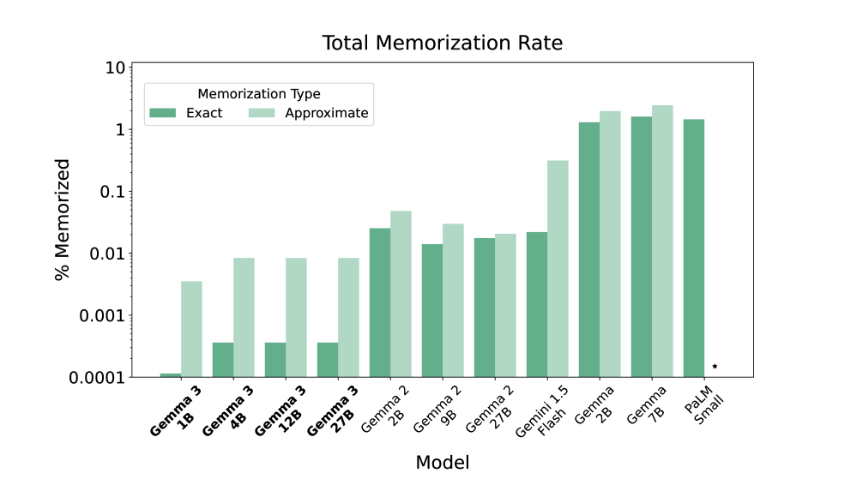
记忆率
记忆率被定义为模型生成内容中与其训练数据匹配的比例,相对于使用以下设置的所有模型生成内容。
我们遵循 Gemma Team (2024b) 中描述的方法来测量它。具体来说,我们从不同语料库中均匀分布地抽取大量训练数据,并使用长度为 50 的前缀和长度为 50 的后缀来测试可发现的提取 (Nasr et al., 2023)。我们将文本标记为“完全记忆”,如果续接部分的所有标记与源后缀完全匹配,或者标记为“大致记忆”,如果它们在编辑距离 10%以内匹配。
附录
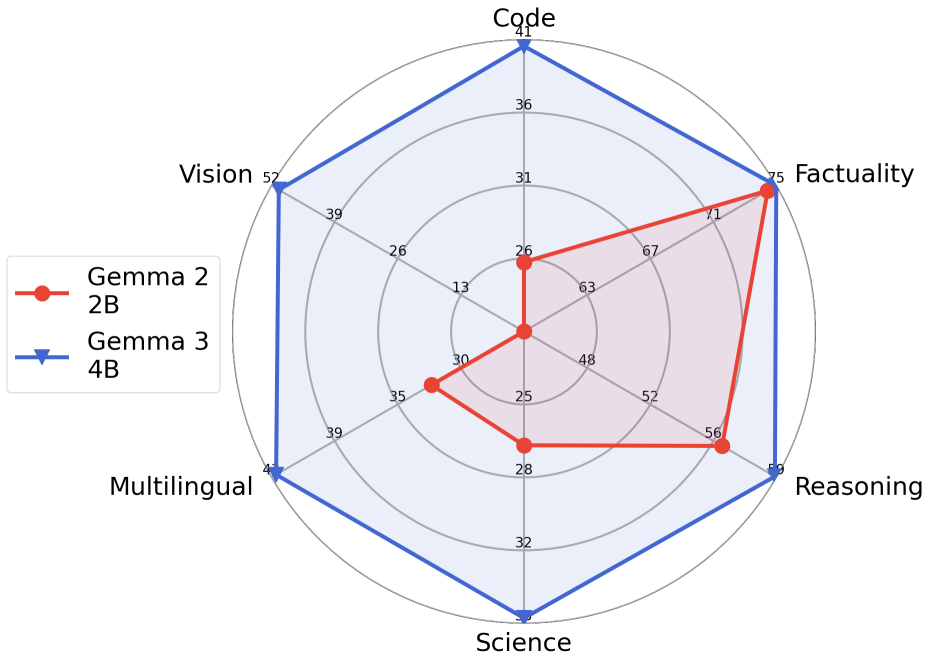
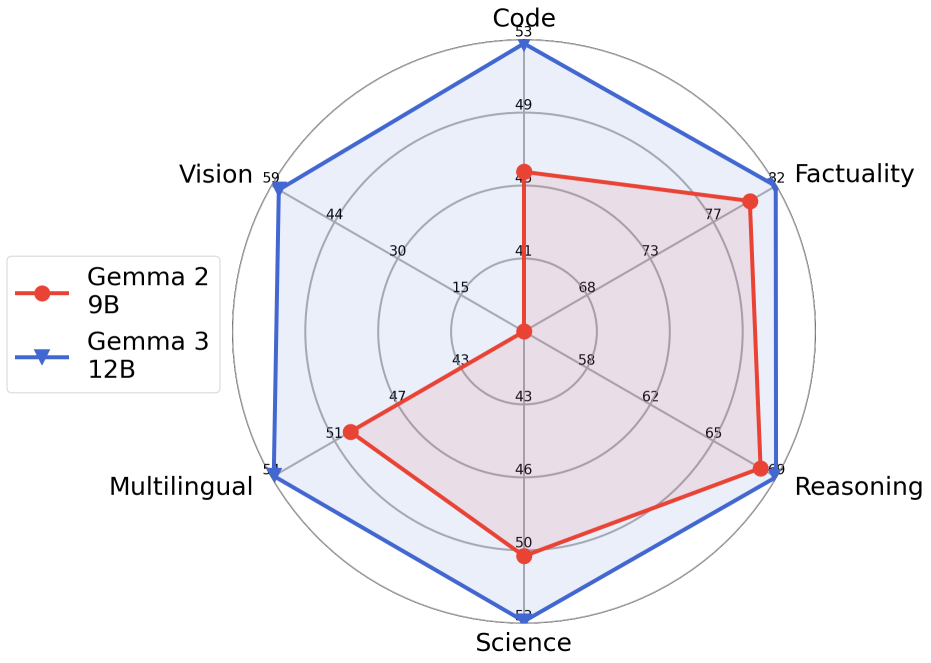
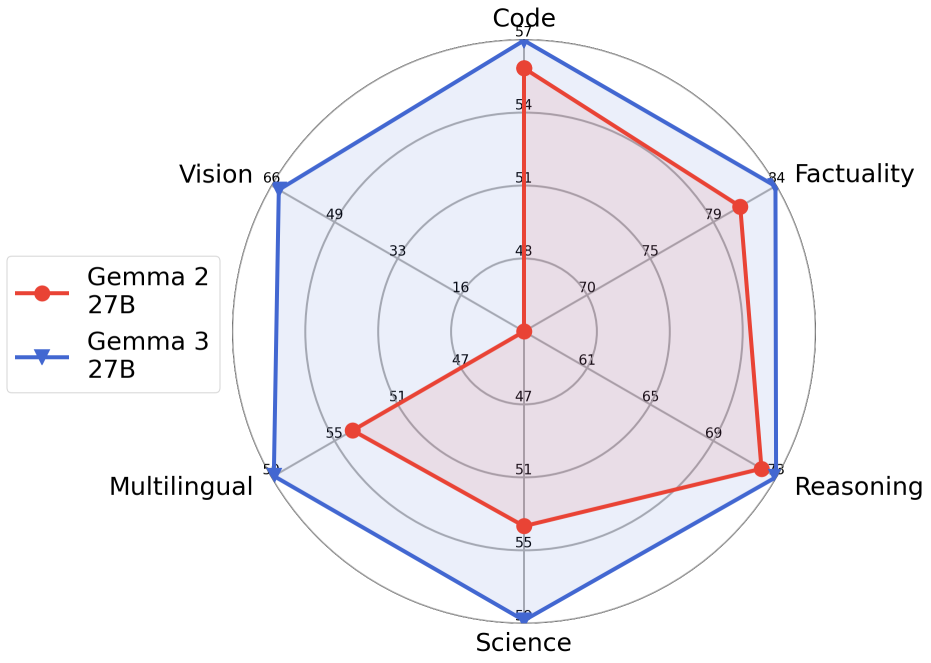
gemma2 和 gemma3 能力对比图
FlexAttention
论文地址:https://arxiv.org/html/2412.05496?_immersive_translate_auto_translate=1
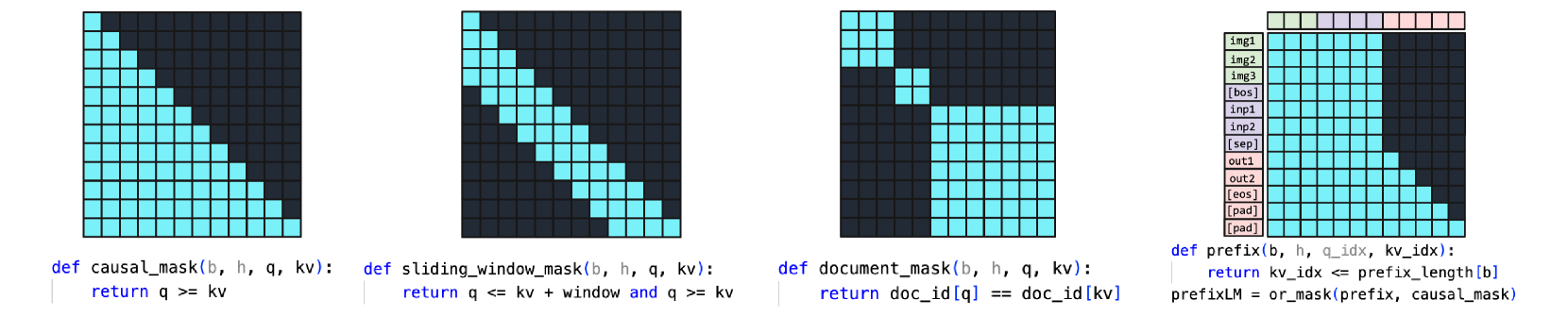
关于注意力变体的几个例子,我们有因果关系 、 相对位置嵌入 、Alibi、 滑动窗口注意力 、 前缀语言模型 、 文档掩码/样本打包/锯齿张量 、 双曲正切软上限 、PagedAttention 等。更糟糕的是,人们常常想要这些的组合!滑动窗口注意力+文档掩码+因果关系+上下文并行?还是 PagedAttention+滑动窗口+双曲正切软上限?
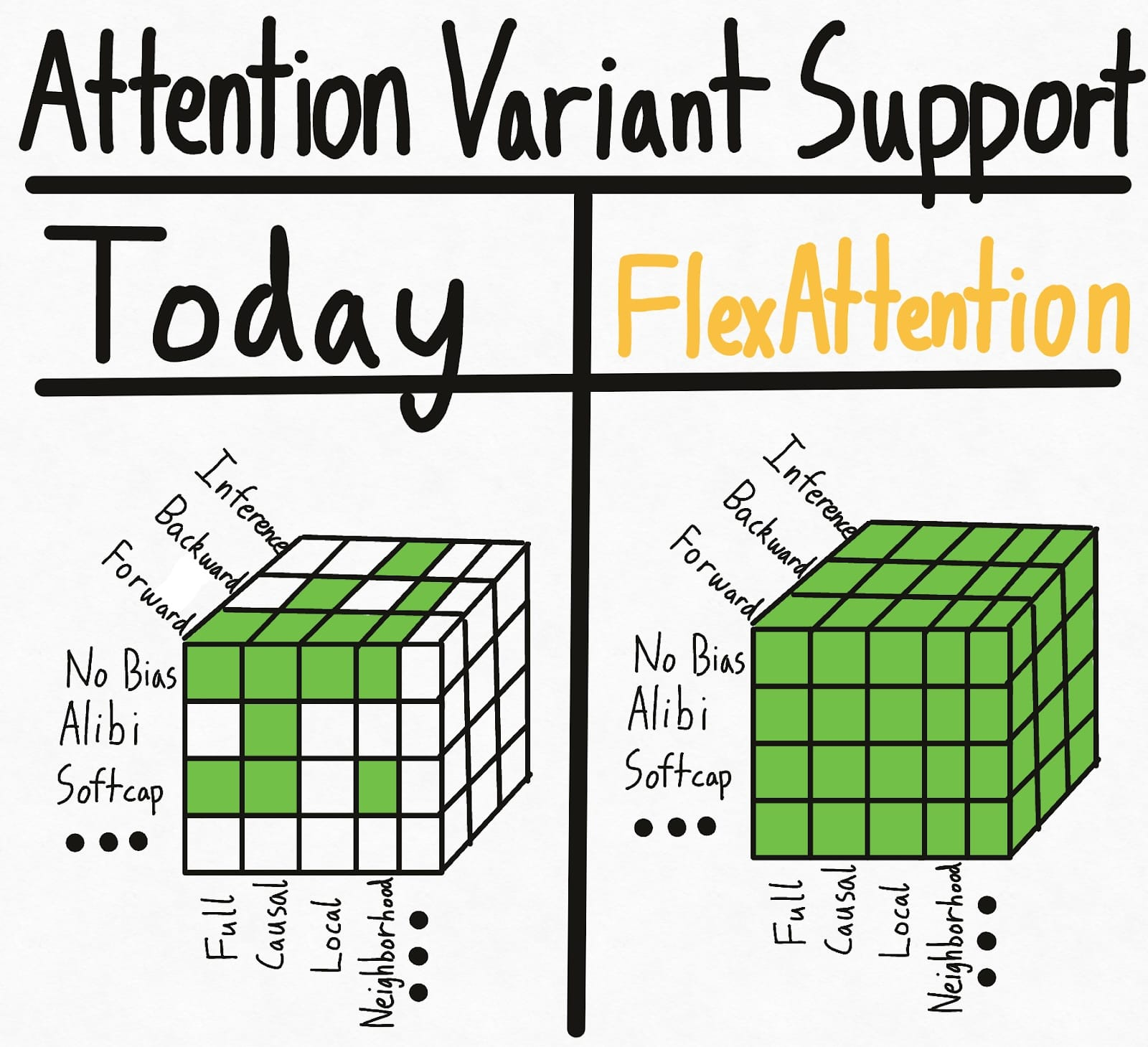
下图左侧展示了当今世界的状态——某些掩码+偏置+设置的组合已经有了现成的内核实现。但各种选项导致设置数量呈指数级增长,因此总体上我们得到的支持相当零散。更糟糕的是,研究人员提出的新注意力变体将得到零支持。
这是经典的注意力方程:
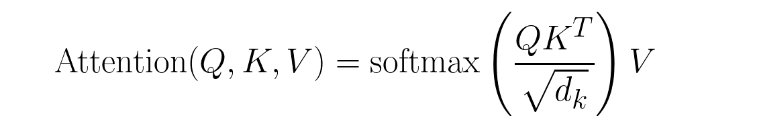
以代码形式:
Q, K, V: Tensor[batch_size, num_heads, sequence_length, head_dim]
score: Tensor[batch_size, num_heads, sequence_length, sequence_length] = (Q @ K) / sqrt(head_dim)
probabilities = softmax(score, dim=-1)
output: Tensor[batch_size, num_heads, sequence_length, head_dim] = probabilities @ V
FlexAttention 允许用户定义函数 score_mod:
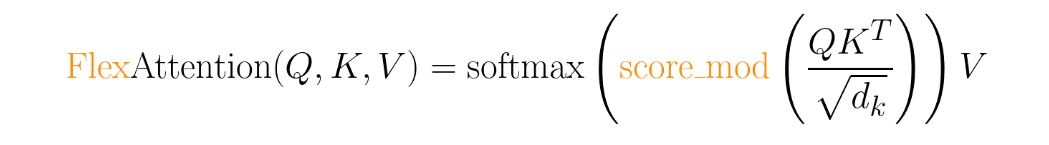
以代码形式:
Q, K, V: Tensor[batch_size, num_heads, sequence_length, head_dim]
score: Tensor[batch_size, num_heads, sequence_length, sequence_length] = (Q @ K) / sqrt(head_dim)
modified_scores: Tensor[batch_size, num_heads, sequence_length, sequence_length] = score_mod(score)
probabilities = softmax(modified_scores, dim=-1)
output: Tensor[batch_size, num_heads, sequence_length, head_dim] = probabilities @ V
此函数允许您在 softmax 之前修改注意力得分。令人惊讶的是,这对于绝大多数注意力变体的需求已经足够(见下面的示例)!
具体来说,score_mod 的预期签名有些独特。
def score_mod(score: f32[], b: i32[], h: i32[], q_idx: i32[], kv_idx: i32[])
return score # noop - standard attention
Soft-capping
Soft-capping是 Gemma2 和 Grok-1 中使用的技术,用于防止 logits 过度增长。在 FlexAttention 中,它看起来像这样:
softcap = 20
def soft_cap(score, b, h, q_idx, kv_idx):
score = score / softcap
score = torch.tanh(score)
score = score * softcap
return score
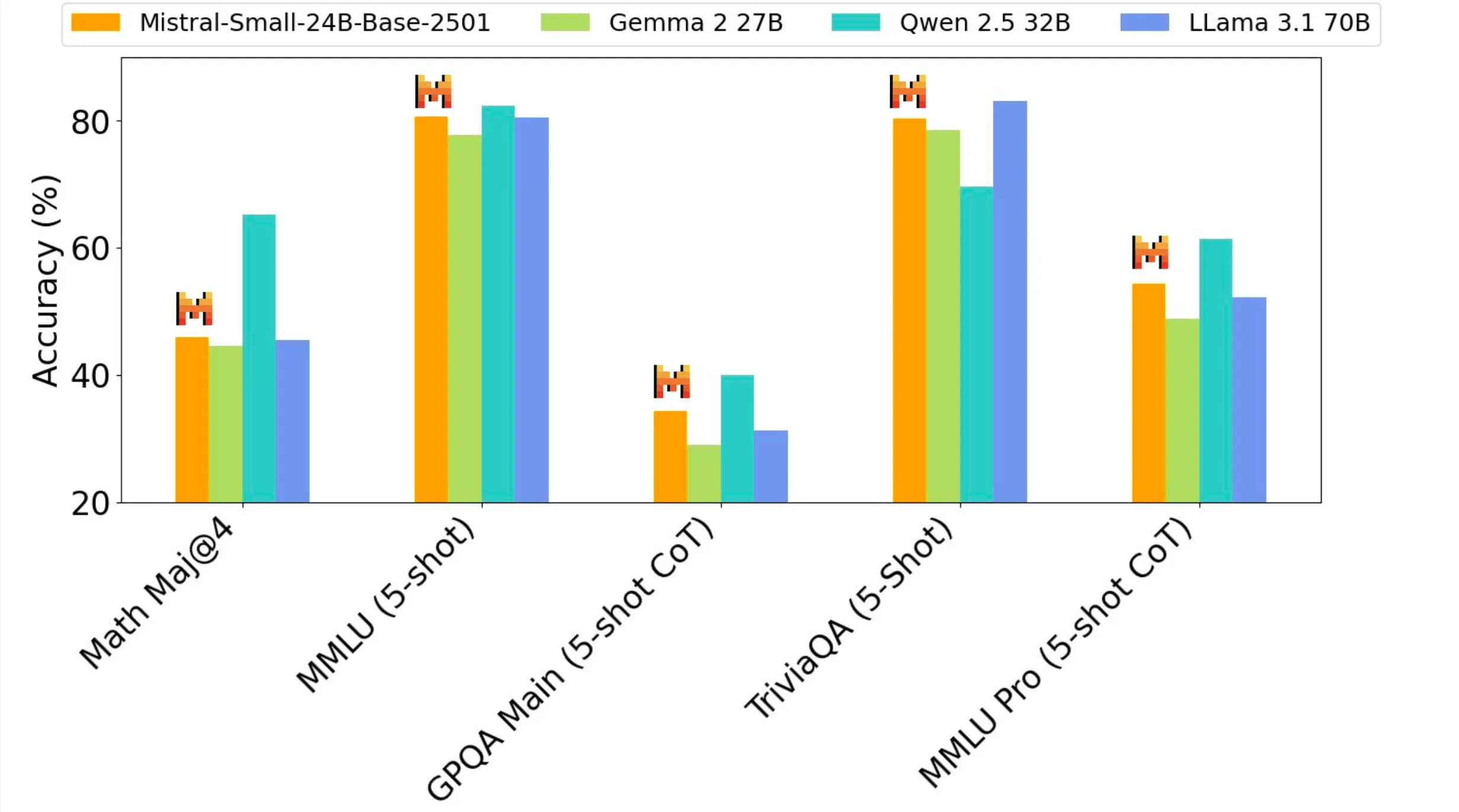
Mistral Small 3
LLaMA4
型号
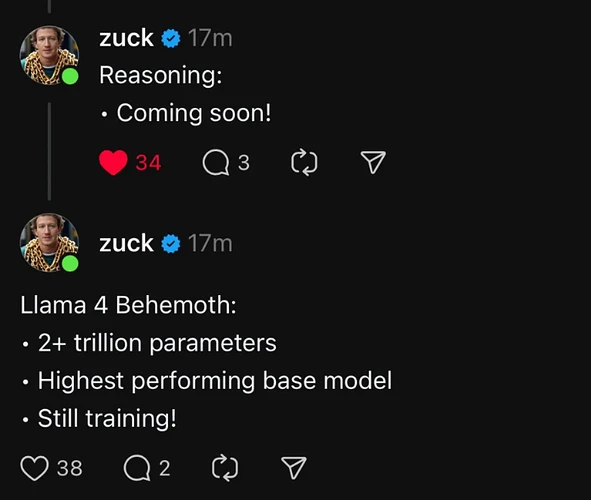
- Llama-4-2T-Behemoth (期货)
288B活跃参数,16个专家,2T总参数
教师模型,用来蒸馏400B和109B模型
还在继续训练
对标Claude Opus,Gemini Ultra,应该暂时不会出API,以防止被同行蒸馏
- Llama-4-400B-Maverick
17B活跃参数,128个专家,400B总参数
原生多模态,具备100万上下文长度
价格输入$0.22,输出$0.88
低于ds3-0324(输出$1.1)
参考2.5pro(输出$10),3.7sonnet(输出$15),4o-0326(输出$10)
- Llama-4-109B-Scout
17B活跃参数,16个专家,109B总参数
对标2.0flash,4o-mini,3.5haiku
- Llama-4-Resoning
前面三个现在应该都没推理,推理是另一个单独的模型,小扎说一个月内上线
创新点解读
- MoE架构****创新
- 首次在旗舰模型中采用专家混合(MoE)架构
- 包含128个路由专家和1个共享专家
- 相比传统稠密模型,提供更高的计算效率
- 能在单个H100主机上运行,降低计算成本
- 原生多模态能力
- 采用早期融合(Early Fusion)技术
- 使用改进版MetaCLIP视觉编码器
- 预训练可处理多达48张图像,实际应用支持8张
- 支持图像定位和视觉问答功能
- 超长上下文处理
- Scout版本支持1000万(10M)token上下文窗口
- Maverick版本支持1M token
- 采用iRoPE(交错注意力层)架构创新
- 结合推理时温度缩放,增强长度泛化能力
- 训练与优化****创新
- 引入MetaP训练技术优化超参数设置
- 采用FP8精度训练提升效率
- 增加中期训练阶段
- 实施精细化后训练流程(SFT、在线RL、DPO)
- 从Behemoth到Maverick的协同蒸馏
- 多语言支持
- 支持200种语言预训练
- 100多种语言可进行开源微调
- 每种语言数据量超过10亿token
- 多语言token数量是Llama 3的10倍
中文能力有待提升,建议等待即将发布的Qwen3。
创新还是缝合
细数一下Llama 4的创新点:
- MoE 架构? 主流玩家早都已经换完了,Llama 4 是 首次 在旗舰模型用,但不是第一个吃螃蟹的。
- 原生多模态? GPT-4V、Gemini 珠玉在前,大家都在做。早期融合 (Early Fusion) 算是一个实现细节上的优化,但多模态本身不是新概念。
- 超长上下文? Llama 4 Scout 的 10M 确实是目前最长,iRoPE 架构是其实现的关键,这算是一个不错的工程创新。但追求长上下文这个 方向 本身,也是行业趋势,之前Gemini、Minimax,甚至Qwen也在这方面进行过探索,并且成果都挺显著的。
- 训练优化? FP8 训练、RLHF/DPO 流程、模型蒸馏,这些都是当前大模型训练的常规操作或渐进式改进(让我们感谢DeepSeek)。MetaP 可能是 Meta 内部提效的法宝,但对外界来说,更多是工程细节的打磨。
Llama 4本次相当于整合了市场上最热门、最有效的技术方向,优化并且 在理论上 推向了新的规模和性能高度,尤其是在开源模型领域再次树立了标杆。
但要说开创了全新的、颠覆性的技术路线,好像还谈不上。更像是站在前人(或者说同行)的肩膀上,做了一次** 工程和整合能力的极致展现** ,把现有的 “SOTA 配方” 调得更猛、融合得更好了。
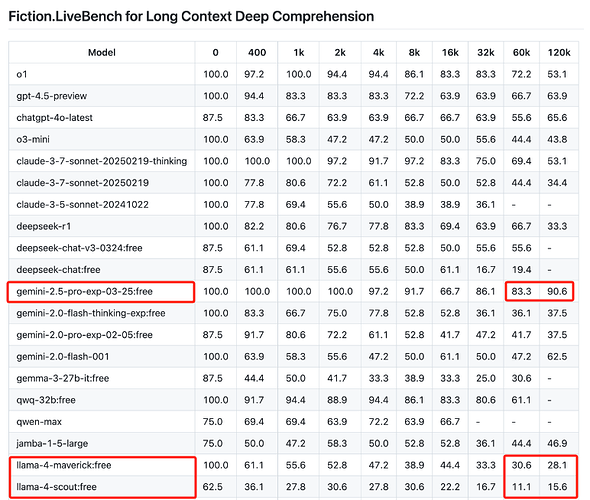
翻车1:llama4-400b Aider编程评分(250407 06:50更新)
排名第29,甚至不敌DeepSeek2.5
表现与lmarena的官方api版本差异过大
- 最乐观的情况:模型没问题,第三方API调教不行
- 中等的情况:开源的版本与送评版本并不是一个版本,以后会开源送评这个版本
- 最悲观的情况:Lmarena机制有漏洞,这货本来就这水平,刷分刷上来的
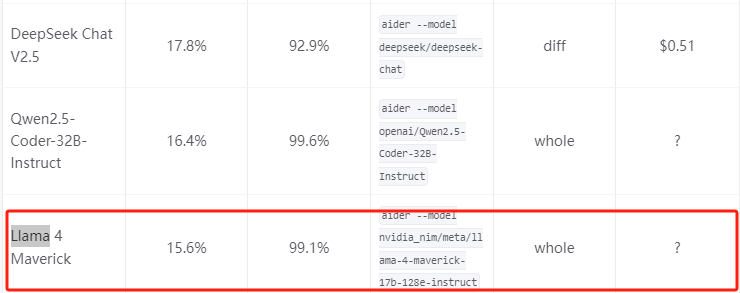
翻车2:FictionBench长上下文评分(250407 07:55更新)
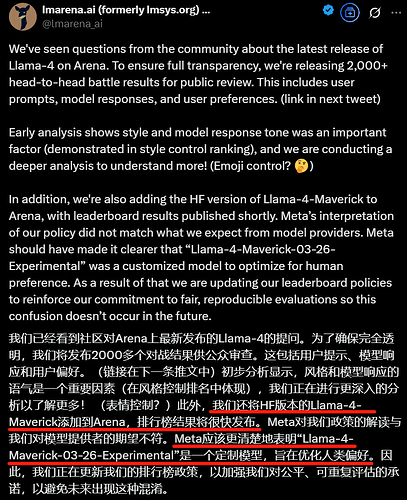
翻车3:Lmarena承认被Meta坑了(250408 13:00更新)
Lmarena承认Meta使用了与开源版不同的,专门刷分的版本,lmarena会上架llama4的Hugging face版本,重新评分
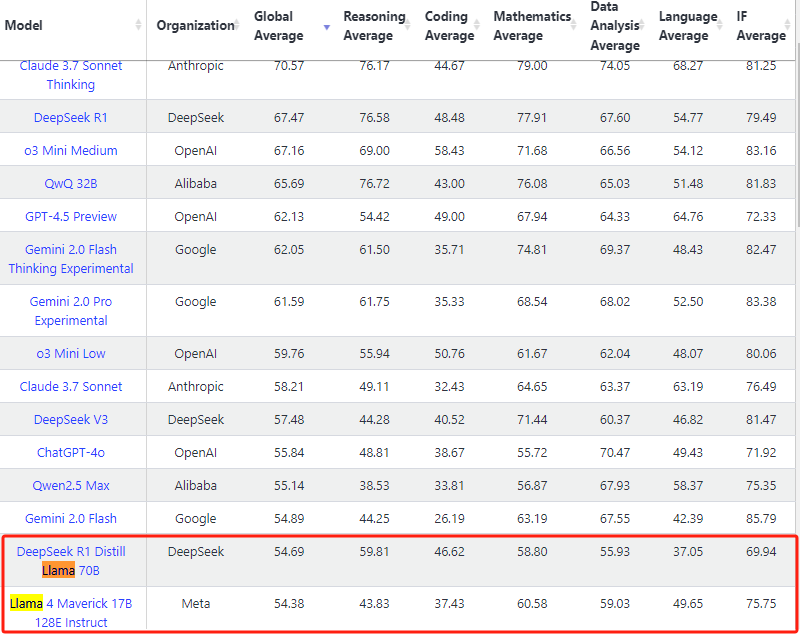
翻车4:LiveBench评分(250408 13:10更新)
llama-4-400b的分数,竟然不如r1-llama3-70b


















 148
148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











