







Google Gemma 3-27B 模型总结
模型概述
Google 的 Gemma 3-27B 模型是一个开源的多模态模型,擅长处理文本和图像输入并生成文本输出。它具有以下特点:
多模态能力:能同时处理文本和图像数据。
大上下文窗口:拥有 128K 的上下文窗口,能够处理更长的文本序列。
多语言支持:支持 140 多种语言,具有广泛的多语言处理能力。
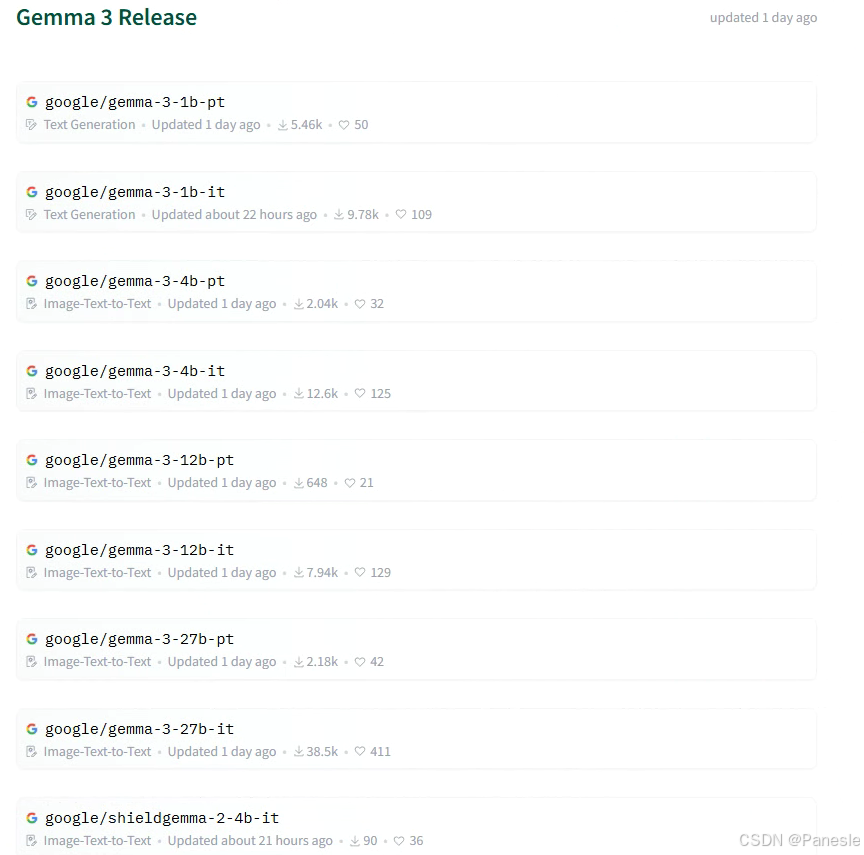
多种尺寸:提供不同参数规模的版本,包括 1B、4B、12B 和 27B 参数模型,适用于不同应用场景。
支持Function Calling,可接入MCP
输入输出
输入:
文本字符串,如问题、提示或待总结的文档。
图像,需归一化为 896 x 896 分辨率并编码为 256 个 token。
总输入上下文为 128K token(对于 4B、12B 和 27B 尺寸)或 32K token(对于 1B 尺寸)。
输出:
根据输入生成的文本,如问题答案、图像内容分析或文档总结。
总输出上下文为 8192 token。
使用方法
API 管道:通过安装特定版本的 Transformers 库,使用简单的代码初始化模型和处理器,即可进行推理。
单机 / 多 GPU 运行:在本地 GPU 上运行模型时,需要安装相关库并使用代码进行模型和处理器的初始化,然后处理输入数据并生成输出。
训练数据与处理
数据来源:训练数据包括网页文档、代码、数学文本和图像等多种来源,确保模型接触到广泛的语言风格、主题和词汇。
数据处理:对训练数据进行了严格的过滤和清洗,包括 CSAM 过滤、敏感数据过滤等,以确保模型的安全性和可靠性。
模型内部细节
硬件支持:使用 Tensor Processing Unit (TPU) 硬件进行训练,具有高性能、高内存、可扩展性和成本效益等优势。
训练框架:采用 JAX 和 ML Pathways 进行训练,简化了开发工作流程。
性能评估
评估指标:在多个数据集和指标上进行评估,涵盖文本生成的不同方面,如推理能力、事实性、STEM 和代码能力、多语言支持等。
评估结果:在各项评估中表现出色,优于其他同等规模的开源模型。
伦理与安全考量
评估方法:包括结构化评估和内部红队测试,针对儿童安全、内容安全和代表性危害等方面进行评估。
评估结果:在安全性方面有显著改进,生成的内容违反政策的情况较少。
潜在应用与局限性
潜在应用:包括文本生成、聊天机器人、文本总结、图像数据提取、自然语言处理研究、语言学习工具和知识探索等。
局限性:模型的性能受训练数据质量和多样性影响,对于复杂任务可能表现不佳,且在语言的细微差别、事实准确性、常识推理等方面可能存在局限。
风险与缓解措施
风险:包括偏见延续、有害内容生成、恶意用途和隐私侵犯等。
缓解措施:建议进行持续监测、探索去偏技术、实施内容安全机制、加强开发者和用户教育等。
总体而言,Gemma 3-27B 模型是一个高性能的开源多模态模型,在多方面表现出色,但也需要注意其潜在的风险和局限性,以实现负责任的 AI 开发和应用。
开源明细:


















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











