







论文:DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better
Github:https://github.com/TAMU-VITA/DeblurGANv2
https://github.com/KupynOrest/DeblurGANv2
ICCV 2019

论文提出了DeblurGAN的改进版,DeblurGAN-v2,在efficiency, quality, flexibility 三方面都取得了state-of-the-art 的效果。
主要贡献:
Framework Level:
对于生成器,为了更好的保准生成质量,论文首次提出采用Feature Pyramid Network (FPN) 结构进行特征融合。对于判别器部分,采用带有最小开方损失(least-square loss )的相对判别器(relativistic discriminator),并且分别结合了全局(global (image) )和局部(local (patch) )2个尺度的判别loss。
Backbone Level:
论文采用了3种骨架网络,分别为Inception-ResNet-v2,MobileNet,MobileNet-DSC。Inception-ResNet-v2具有最好的精度,MobileNet和MobileNet-DSC具有更快的速度。
Experiment Level:
在3个指标PSNR, SSIM, perceptual quality 都取得了很好的结果。基于MobileNet-DSC 的DeblurGAN-v2比DeblurGAN快了11倍,并且只有4M大小。
网络结构:

生成器基本结构为FPN结构,分别获取5个分支的特征输出,基于上采样操作进行融合。最后再加入原图的shortcut分支,得到最终的输出。
输入图片归一化到了[-1,1],输出图片也经过tanh函数归一化到[-1,1]。
损失函数Loss:
传统GAN的损失函数:
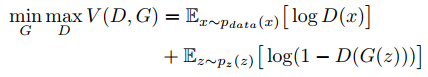
Least Squares GANs(LSGAN)的损失函数:
该损失有助于使得训练过程更加平稳,高效。

判别器RaGAN-LS loss :
该loss是在LSGAN loss的基础上,进行的改进。

生成器整体loss:
![]()
其中,Lp表示mean-square-error (MSE)
Lx表示感知loss,表示内容的损失
Ladv表示全局和局部的损失,全局表示整个图片的损失,局部类比于PatchGAN,表示将整个图片分块为一个一个的70*70的局部图片的损失。
训练集:
GoPro :3214 blurry/clear 图片对,其中2103作训练,1111做测试。
DVD :6708 blurry/clear 图片对
NFS :75个视频
实验结果:

训练&测试:
本人使用的是GOPRO数据集进行的训练。
代码修改,config/config.yaml
files_a: &FILES_A ./datasets/GOPRO/GOPRO_3840FPS_AVG_3-21/**/*.png数据集目录结构,

fpn_inception训练,测试:
从头开始训练,python3 train.py
加载预训练模型训练,修改,train.py,
def _init_params(self):
self.criterionG, criterionD = get_loss(self.config['model'])
self.netG, netD = get_nets(self.config['model'])
self.netG.load_state_dict(torch.load("offical_models/fpn_inception.h5", map_location='cpu')['model'])
self.netG.cuda()
self.adv_trainer = self._get_adversarial_trainer(self.config['model']['d_name'], netD, criterionD)
self.model = get_model(self.config['model'])
self.optimizer_G = self._get_optim(filter(lambda p: p.requires_grad, self.netG.parameters()))
self.optimizer_D = self._get_optim(self.adv_trainer.get_params())
self.scheduler_G = self._get_scheduler(self.optimizer_G)
self.scheduler_D = self._get_scheduler(self.optimizer_D)
训练loss,
Epoch 25, lr 0.0001: 100%|##################################################################################################################| 1000/1000 [07:27<00:00, 2.23it/s, loss=G_loss=-0.0117; PSNR=38.5462; SSIM=0.9783]
Validation: 100%|#############################################################################################################################################################################| 100/100 [00:36<00:00, 2.76it/s]
G_loss=-0.0147; PSNR=36.3670; SSIM=0.9769开始测试,python3 predict.py 007952_9.png
fpn_inception的测试效果如下,模型大小234M,


fpn_mobilenet训练,测试:
mobilenet_v2.pth.tar模型的url:http://sceneparsing.csail.mit.edu/model/pretrained_resnet/mobilenet_v2.pth.tar
修改,config/config.yaml
g_name: fpn_mobilenet加载预训练模型训练,修改train.py,
def _init_params(self):
self.criterionG, criterionD = get_loss(self.config['model'])
self.netG, netD = get_nets(self.config['model'])
self.netG.load_state_dict(torch.load("offical_models/fpn_mobilenet.h5", map_location='cpu')['model'])
self.netG.cuda()
self.adv_trainer = self._get_adversarial_trainer(self.config['model']['d_name'], netD, criterionD)
self.model = get_model(self.config['model'])
self.optimizer_G = self._get_optim(filter(lambda p: p.requires_grad, self.netG.parameters()))
self.optimizer_D = self._get_optim(self.adv_trainer.get_params())
self.scheduler_G = self._get_scheduler(self.optimizer_G)
self.scheduler_D = self._get_scheduler(self.optimizer_D)训练loss,
Epoch 0, lr 0.0001: 100%|####################################################################################################################| 1000/1000 [05:13<00:00, 3.19it/s, loss=G_loss=0.0194; PSNR=39.9682; SSIM=0.9801]
Validation: 100%|#############################################################################################################################################################################| 100/100 [00:36<00:00, 2.71it/s]
G_loss=0.0275; PSNR=39.7776; SSIM=0.9802
开始测试,python3 predict.py 007952_9.png
fpn_mobilenet的测试效果如下,模型大小13M,
















 7202
7202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









