







Unet模型使用官方基于kaggle Carvana Image Masking Challenge数据集训练的模型。
模型输入为572*572*3,输出为572*572*2。分割目标分别为,0:背景,1:汽车。
Pytorch的pth模型转化onnx模型:
import torch
from unet import UNet
model = UNet(n_channels=3, n_classes=2, bilinear=False)
model = model.to(memory_format=torch.channels_last)
state_dict = torch.load("unet_carvana_scale1.0_epoch2.pth", map_location="cpu")
#del state_dict['mask_values']
model.load_state_dict(state_dict)
dummy_input = torch.randn(1, 3, 572, 572)
torch.onnx.export(model, dummy_input, "unet.onnx", verbose=True)

模型输入输出节点分析:
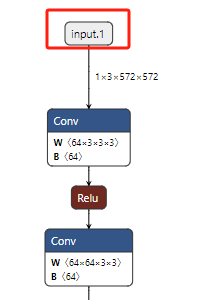
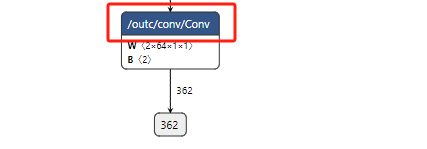
使用工具Netron查看模型结构,确定模型输入节点名称为input.1,输出节点名称为/outc/conv/Conv
onnx模型转化atlas模型:
atc --model=./unet.onnx --framework=5 --output=unet --soc_version=Ascend310P3 --input_shape="input.1:1,3,572,572" --output_type="/outc/conv/Conv:0:FP32" --out_nodes="/outc/conv/Conv:0"![]()
推理代码实现:
import base64
import json
import os
import time
import numpy as np
import cv2
import MxpiDataType_pb2 as mxpi_data
from StreamManagerApi import InProtobufVector
from StreamManagerApi import MxProtobufIn
from StreamManagerApi import StreamManagerApi
def check_dir(dir):
if not os.path.exists(dir):
os.makedirs(dir, exist_ok=True)
class SDKInferWrapper:
def __init__(self): # 完成初始化
self._stream_name = None
self._stream_mgr_api = StreamManagerApi()
if self._stream_mgr_api.InitManager() != 0:
raise RuntimeError("Failed to init stream manager.")
pipeline_name = './nested_unet.pipeline'
self.load_pipeline(pipeline_name)
self.width = 572
self.height = 572
def load_pipeline(self, pipeline_path):
with open(pipeline_path, 'r') as f:
pipeline = json.load(f)
self._stream_name = list(pipeline.keys())[0].encode() # 'unet_pytorch'
if self._stream_mgr_api.CreateMultipleStreams(
json.dumps(pipeline).encode()) != 0:
raise RuntimeError("Failed to create stream.")
def do_infer(self, img_bgr):
# preprocess
image = cv2.resize(img_bgr, (self.width, self.height))
image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB)
image = image.astype('float32') / 255.0
image = image.transpose(2, 0, 1)
tensor_pkg_list = mxpi_data.MxpiTensorPackageList()
tensor_pkg = tensor_pkg_list.tensorPackageVec.add()
tensor_vec = tensor_pkg.tensorVec.add()
tensor_vec.deviceId = 0
tensor_vec.memType = 0
for dim in [1, *image.shape]:
tensor_vec.tensorShape.append(dim) # tensorshape属性为[1,3,572,572]
input_data = image.tobytes()
tensor_vec.dataStr = input_data
tensor_vec.tensorDataSize = len(input_data)
protobuf_vec = InProtobufVector()
protobuf = MxProtobufIn()
protobuf.key = b'appsrc0'
protobuf.type = b'MxTools.MxpiTensorPackageList'
protobuf.protobuf = tensor_pkg_list.SerializeToString()
protobuf_vec.push_back(protobuf)
unique_id = self._stream_mgr_api.SendProtobuf(
self._stream_name, 0, protobuf_vec)
if unique_id < 0:
raise RuntimeError("Failed to send data to stream.")
infer_result = self._stream_mgr_api.GetResult(
self._stream_name, unique_id)
if infer_result.errorCode != 0:
raise RuntimeError(
f"GetResult error. errorCode={infer_result.errorCode}, "
f"errorMsg={infer_result.data.decode()}")
output_tensor = self._parse_output_data(infer_result)
output_tensor = np.squeeze(output_tensor)
output_tensor = softmax(output_tensor)
mask = np.argmax(output_tensor, axis =0)
score = np.max(output_tensor, axis = 0)
mask = cv2.resize(mask, [img_bgr.shape[1], img_bgr.shape[0]], interpolation=cv2.INTER_NEAREST)
score = cv2.resize(score, [img_bgr.shape[1], img_bgr.shape[0]], interpolation=cv2.INTER_NEAREST)
return mask, score
def _parse_output_data(self, output_data):
infer_result_data = json.loads(output_data.data.decode())
content = json.loads(infer_result_data['metaData'][0]['content'])
tensor_vec = content['tensorPackageVec'][0]['tensorVec'][0]
data_str = tensor_vec['dataStr']
tensor_shape = tensor_vec['tensorShape']
infer_array = np.frombuffer(base64.b64decode(data_str), dtype=np.float32)
return infer_array.reshape(tensor_shape)
def draw(self, mask):
color_lists = [(255, 0, 0), (0, 255, 0), (0, 0, 255)]
drawed_img = np.stack([mask, mask, mask], axis = 2)
for i in np.unique(mask):
drawed_img[:,:,0][drawed_img[:,:,0]==i] = color_lists[i][0]
drawed_img[:,:,1][drawed_img[:,:,1]==i] = color_lists[i][1]
drawed_img[:,:,2][drawed_img[:,:,2]==i] = color_lists[i][2]
return drawed_img
def softmax(x):
exps = np.exp(x - np.max(x))
return exps/np.sum(exps)
def sigmoid(x):
y = x.copy()
y[x >= 0] = 1.0 / (1 + np.exp(-x[x >= 0]))
y[x < 0] = np.exp(x[x < 0]) / (1 + np.exp(x[x < 0]))
return y
def check_dir(dir):
if not os.path.exists(dir):
os.makedirs(dir, exist_ok=True)
def test():
dataset_dir = './sample_data'
output_folder = "./infer_result"
os.makedirs(output_folder, exist_ok=True)
sdk_infer = SDKInferWrapper()
# read img
image_name = "./sample_data/images/111.jpg"
img_bgr = cv2.imread(image_name)
# infer
t1 = time.time()
mask, score = sdk_infer.do_infer(img_bgr)
t2 = time.time()
print(t2-t1, mask, score)
drawed_img = sdk_infer.draw(mask)
cv2.imwrite("infer_result/draw.png", drawed_img)
if __name__ == "__main__":
test()
运行代码:
set -e
. /usr/local/Ascend/ascend-toolkit/set_env.sh
# Simple log helper functions
info() { echo -e "\033[1;34m[INFO ][MxStream] $1\033[1;37m" ; }
warn() { echo >&2 -e "\033[1;31m[WARN ][MxStream] $1\033[1;37m" ; }
#export MX_SDK_HOME=/home/work/mxVision
export LD_LIBRARY_PATH=${MX_SDK_HOME}/lib:${MX_SDK_HOME}/opensource/lib:${MX_SDK_HOME}/opensource/lib64:/usr/local/Ascend/ascend-toolkit/latest/acllib/lib64:${LD_LIBRARY_PATH}
export GST_PLUGIN_SCANNER=${MX_SDK_HOME}/opensource/libexec/gstreamer-1.0/gst-plugin-scanner
export GST_PLUGIN_PATH=${MX_SDK_HOME}/opensource/lib/gstreamer-1.0:${MX_SDK_HOME}/lib/plugins
#to set PYTHONPATH, import the StreamManagerApi.py
export PYTHONPATH=$PYTHONPATH:${MX_SDK_HOME}/python
python3 unet.py
exit 0
运行效果:


![]()
个人思考:
华为atlas的参考案例细节不到位,步骤缺失较多,摸索困难,代码写法较差,信创化道路任重而道远。
参考资料:
https://gitee.com/ascend/samples/tree/master/python/level2_simple_inference/3_segmentation/unet++















 4089
4089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









