




写在前面:
DPM(Deformable Part Model),正如其名称所述,可变形的组件模型,是一种基于组件的检测算法,其所见即其意。该模型由大神Felzenszwalb在2008年提出,并发表了一系列的cvpr,NIPS。并且还拿下了2010年,PASCAL VOC的“终身成就奖”。
由于DPM用到了HOG的东西,可以参考本人http://blog.csdn.net/qq_14845119/article/details/52187774
算法思想:
(1)Root filter+ Part filter:
该模型包含了一个8*8分辨率的根滤波器(Root filter)(左)和4*4分辨率的组件滤波器(Part filter)(中)。其中,中图的分辨率为左图的2倍,并且Part filter的大小是Root filter的2倍,因此,看的梯度会更加精细。右图为其高斯滤波后的2倍空间模型。

(左)Rootfilter(中) Part filter (右)高斯滤波后模型
(2)响应值(score)的计算:
响应值得分公式如下:
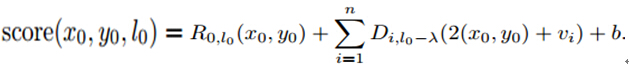
其中,
x 0, y 0, l 0分别为锚点的横坐标,纵坐标,尺度。
R 0,l 0 (x 0, y 0)为根模型的响应分数
Di,l 0−λ(2(x 0, y 0) + vi)为部件模型的响应分数
b为不同模型组件之间的偏移系数,加上这个偏移量使其与跟模型进行对齐
2(x 0, y 0)表示组件模型的像素为原始的2倍,所以,锚点*2
vi为锚点和理想检测点之间的偏移系数,如下图中红框和黄框
其部件模型的详细响应得分公式如下:
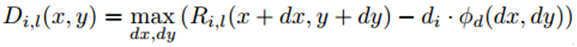
其中,
x, y为训练的理想模型的位置
Ri,l(x + dx, y + dy)为组件模型的匹配得分
di · φd(dx, dy))为组件的偏移损失得分
di ·为偏移损失系数
φd(dx, dy))为组件模型的锚点和组件模型的检测点之间的距离
简单的说,这个公式表明,组件模型的响应越高,各个组件和其相应的锚点距离越小,则响应分数越高,越有可能是待检测的物体。
(3)DPM特征定义:
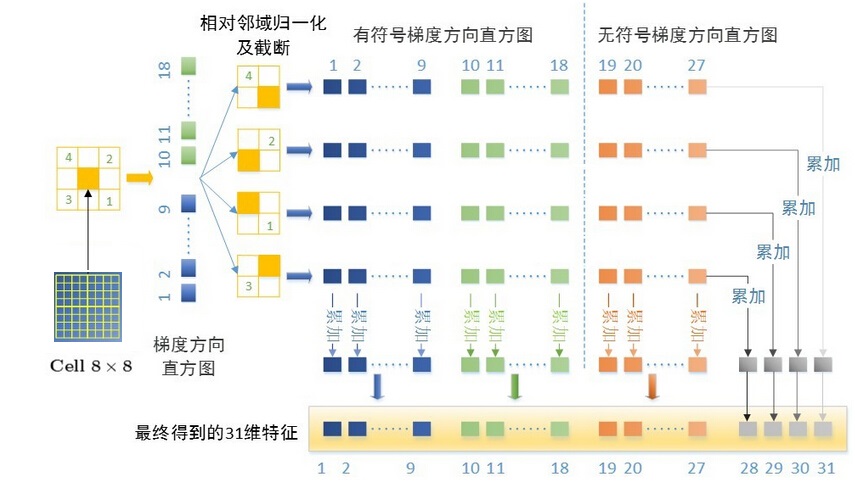
DPM首先采用的是HOG进行特征的提取,但是又有别于HOG,DPM中,只保留了HOG中的Cell。如上图所示,假设,一个8*8的Cell,将该细胞单元与其对角线临域的4个细胞单元做归一化操作。
提取有符号的HOG梯度,0-360度将产生18个梯度向量,提取无符号的HOG梯度,0-180度将产生9个梯度向量。因此,一个8*8的细胞单元将会产生,(18+9)*4=108,维度有点高,Felzenszwalb大神给出了其优化思想。
首先,只提取无符号的HOG梯度,将会产生4*9=36维特征,将其看成一个4*9的矩阵,分别将行和列分别相加,最终将生成4+9=13个特征向量,为了进一步提高精度,将提取的18维有符号的梯度特征也加进来,这样,一共产生13+18=31维梯度特征。实现了很好的目标检测。
( 4 ) DPM 检测流程:
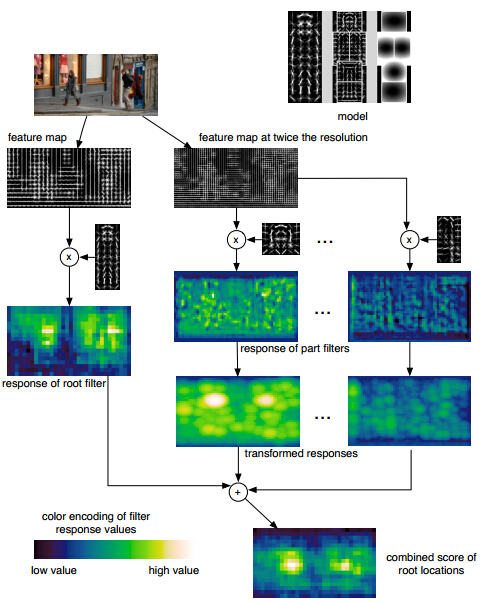
如上图所示,对于任意一张输入图像,提取其DPM特征图,然后将原始图像进行高斯金字塔上采样,然后提取其DPM特征图。对于原始图像的DPM特征图和训练好的Root filter做卷积操作,从而得到Root filter的响应图。对于2倍图像的DPM特征图,和训练好的Part filter做卷积操作,从而得到Part filter的响应图。然后对其精细高斯金字塔的下采样操作。这样Root filter的响应图和Part filter的响应图就具有相同的分辨率了。然后将其进行加权平均,得到最终的响应图。亮度越大表示响应值越大。
(5)Latent SVM:

传统的Hog+SVM和DPM+LatentSVM的区别如上面公式所示。
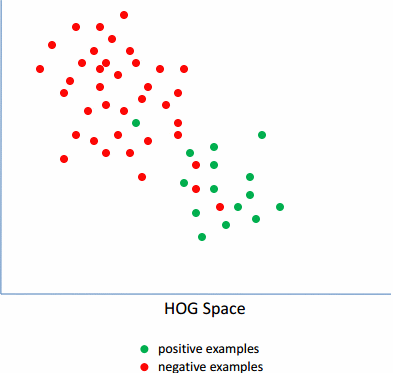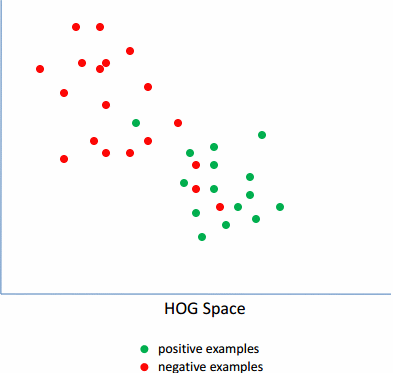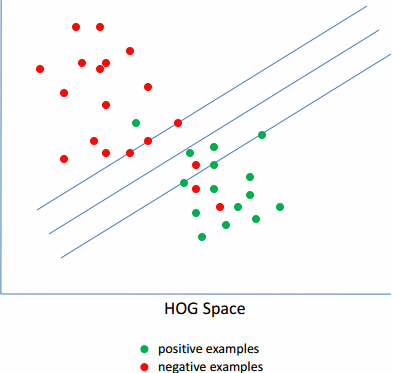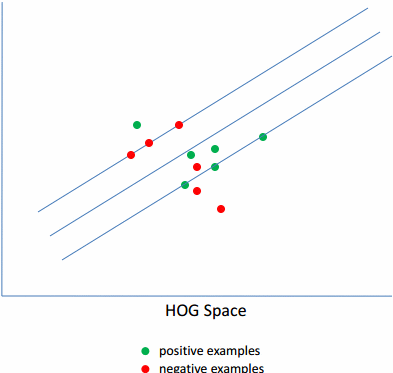
由于,训练的样本中,负样本集肯定是100%的准确的,而正样本集中就可能有噪声。因为,正样本的标注是人工进行的,人是会犯错的,标注的也肯定会有不精确的。因此,需要首先去除里面的噪声数据。而对于剩下的数据,里面由于各种角度,姿势的不一样,导致训练的模型的梯度图也比较发散,无规则。因此需要选择其中的具有相同的姿势的数据,即离正负样本的分界线最近的那些样本,将离分界线很近的样本称为Hard-examples,相反,那些距离较远的称为Easy-examples。
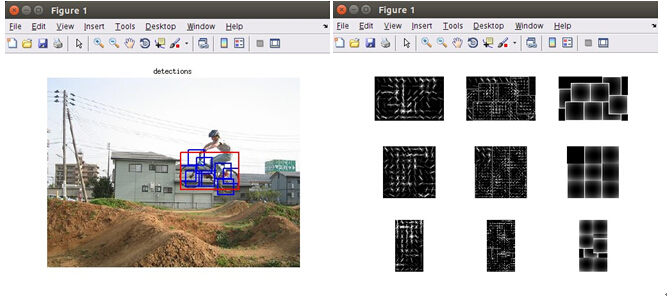
实际效果图如下图所示:
实验效果:
如下图所示,左面为检测自行车的检测效果,右面为Root filter,Part filter,2维高斯滤波下的偏离损失图
References:
[1]: https://people.eecs.berkeley.edu/~rbg/latent/index.html
[2]: P. Felzenszwalb, D. McAllester, D.Ramanan A Discriminatively Trained, Multiscale, Deformable Part Model IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2008
[3]: P. Felzenszwalb, R. Girshick, D.McAllester, D. Ramanan Object Detection with Discriminatively TrainedPart Based Models IEEE Transactions on Pattern Analysis and MachineIntelligence, Vol. 32, No. 9, Sep. 2010
[4]: P. Felzenszwalb, R. Girshick, D.McAllester Cascade Object Detection with Deformable Part Models IEEEConference on Computer Vision and Pattern Recognition (CVPR), 2010
[5]: P. Felzenszwalb, D. McAllester ObjectDetection Grammars University of Chicago, Computer Science TR-2010-02, February2010
[6]: R. Girshick, P. Felzenszwalb, D.McAllester Object Detection with Grammar Models Neural InformationProcessing Systems (NIPS), 2011
[7]: R. Girshick From RigidTemplates to Grammars: Object Detection with Structured Models
Ph.D. dissertation, The University of Chicago, Apr. 2012

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









