







一起学AI:核心基础概念

一起学AI系列博客:目录索引
本文笔记小结深度学习里的核心基础概念和高频知识点分析。
AI基础概念
什么是学习率?
- 学习率alpha是一个人为控制的超参数,有时也叫
learning rate(lr) - 学习率的范围,通常是
(0, 1] - 学习率通常用在神经元权重更新上,公式为:
w = w - alpha * D - 学习率的用途是控制权重更新的步幅,一个合适lr可以帮助模型找到最优权重,从而快速收敛。
batchsize和epoch分别是什么?
epoch和batchsize概念辨析
- batchsize,是将训练集拆分成若干个mini batch,每个batch的大小称为batchsize;设训练集m个样本,每个batch样本n个,则batch个数为k=m/n个
- epoch,指整个训练集通过训练模型的次数,也可称为训练次数。整个训练集每进一轮网络迭代更新权重,算1个epoch,一般10-100个epoch就能将整个训练集收敛了
- 参考说明:神经网络中的Epoch、Iteration、Batchsize
梯度消失与梯度爆炸是什么?
梯度消失与梯度爆炸问题与解决
- 梯度消失,又称梯度弥散
- 现象:离输出层越远的神经元越难以快速更新权重,主要源自
sigmoid求导函数乘的a(1-a),a范围是0-1,则求导函数值域就是(0,0.25)永远小于1,致使网络层数加深后,输入层附近的神经元权重几乎无法更新,难以训练。 - 解决:BP出了后,因为这一问题,深度学习又消停许多年。直到relu出现,relu求导为1或0不会有权值缩放的问题,最终更换激活函数得以解决。
- 现象:离输出层越远的神经元越难以快速更新权重,主要源自
- 梯度爆炸
- 现象:
relu引入又可能导致梯度爆炸,即若权重初始值很大时,迭代w=w-D,D不断累积而来变成一个极大的数(梯度爆炸),导致w更新后极负。 - 后果:有关神经元炸死,w*a数值均小于0,relu输出0,不管啥输入都会置零,神经元失效。
- 解决:1、用改进后的relu;2、采用适当的权重初始化方法,逐层初始化
- 现象:
什么是过拟合、欠拟合和泛化?
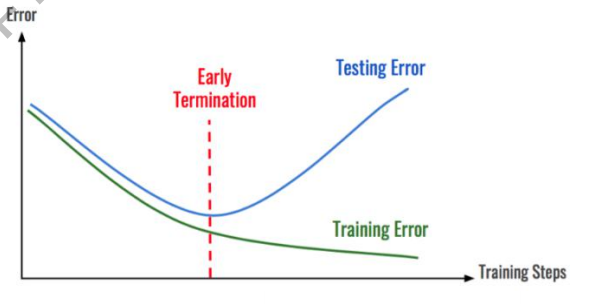
- 过拟合:就是指虽然训练集误差越来越小,但是在测试集上误差越来越大的现象。表示模型对训练集数据过拟合了,无法有效预测集外数据。
- 泛化性:指的是评价模型好坏的一个标准,针对新数据的预测准确率越差泛化性越差,反之,则泛化性越好。如果模型不鲁棒,或训练集准确率高、测试集准确率低,就可以称模型泛化性差。本质上,过拟合就是模型泛化性差的体现。
- 欠拟合:与过拟合相反,指的是模型在训练集上准确率一直无法提升到预期值,说明当前模型无法顺利拟合,需要修改模型或者增加数据。
过拟合与泛化
- 拟合指的是和目标的接近程度
- 过拟合和泛化是相互矛盾的点
- 过拟合,导致泛化能力差
- 泛化能力好,拟合精度可能就没那么完美
归一化、正则化、标准化是什么?
归一化(Normalization)- 是为了统一尺度,
- 统一尺度为无量纲数,将数据都缩放到[0, 1]区间
- 方式1:不改分布,Min-Max 归一化
- 通过最大值、最小值和平均值来映射,公式为:
X_normal = (X - min) / (max - min)
- 通过最大值、最小值和平均值来映射,公式为:
- 方式2:改分布,Z-Score 标准化,则成为标准化(Standardization)
- 调整后mu和sigma分别为0,1。
- 公式为:
X_normal = (X - mu) / sigma
- 效果:便于观察分析,使不同维度的神经元误差等高线一致,网络快速收敛。
正则化(Regularization)- 惩罚高阶参数,最小化误差的同时,防止过拟合。
- 注意与正交化相区分,正交化是为了去除数据相关性,使其正交,便于计算
- 进阶参考:link1,link2
线性回归和逻辑回归是什么?
- 线性回归
- 输出是一条直线,连续值,适合做拟合
- 回归前是连续的,回归后分类,是离散的
- 类型已知,是个固定值
- 逻辑回归(softmax回归)
- 输出单独结果,离散值,适合做分类
- 翻译问题,这里的logistic,本质跟逻辑无关,而是取Logarithm:对数的意思
- 将R实数压缩到[0, 1]范围,转换成概率后,就能适用分类问题
- 若X输进去,分别检测是否为0、1、…、9,输出对应的概率,选择概率最大的那个,作为最终分类结果
- 联系
- 逻辑回归是线性回归的特例
- sigmoid/softmax非线性激活函数接在线性回归的输出上,成为了逻辑回归
- 所有机器学习都可以化归为以上两种:
- 如果是分类任务,输出离散值,则是逻辑回归
- 如果是预测任务,输出连续值,则是线性回归

参考资料:
- 浅析机器学习:线性回归 & 逻辑回归,https://zhuanlan.zhihu.com/p/39363869
激活函数中softmax与sigmoid有啥区别与联系?
- sigmoid,输出为0-1分布,输出为标量(仅有1个值),表征是该类别的概率p,另一类的概率则为1-p。适合二分类任务。
- 公式:s(x) = 1 / (1 + exp(-x))
- 导数:s’ = s * (1 - s)
- softmax,输出为不同类别的概率,所有类别组成一个向量,各概率元素之和为1,概率越大的即为对应类别。适合多分类任务。
- 本质让各类别e^x / (求和e^x) = 1/ n概率
- 评价每种分类的可能性,从而输出最终的分类结果
- 联系与区别
- 当处理多分类任务时,两者无联系
- 当处理2分类任务时,两者相似却有些区别
- softmax输出是两个神经元,分别对应a,b两类的概率,两者之和为1。a/b为互补关系。
- sigmoid输出为一个神经元,为对应a类的概率值,否则为非a。
- 进阶了解:Softmax函数和Sigmoid函数的区别与联系
神经网络里普通参数与超参的区别是什么?
- 普通参数,指模型根据数据不断学习更新而来,根据数据和损失函数,不断梯度下降,可以自动处理的模型参数,主要指神经元权重w
- 超参,指需人工根据经验指定的参数,如卷积核的尺寸、连接神经元个数、层数、维度,批量大小beta,学习率lr等
如何衡量模型的算力开销?FLOPS表示啥意思?
- 常用每秒浮点运算次数来衡量模型的算法时间复杂度,即算力开销。
- FLOPS:floating-point operation per second,每秒所执行的浮点运算次数
- 1GFLOPS, 10^9,10亿次每秒
- 1MFLOPS,10^6,1百万次每秒
AI常见问题与解决
学习率衰减lr-decay
- 问题:训练集误差越来越小,而测试误差会先减小,后增大,则此时出现了过拟合
- 解决:
- 利用学习率衰减的方法,前期大步跑,后期小步跑;再过拟合前刹住,停止迭代。
人工数据增强的常见方法
- 问题:数据集样本少,质量低
- 解决:思路是数据不够,人工拼凑
- 具体方法:以图像为例
- 亮度、饱和度、对比度调节
- 随机截取、旋转、对称图像
- 图像加噪















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









