







拟合、泛化能力和模型复杂度之间权衡关系以及改善泛化能力的方法
本文介绍了机器学习中的过拟合、欠拟合、泛化能力以及模型复杂度的基本内容,并阐述了它们之间的关系,并对提高模型泛化能力的方法进行了总结。
一、过拟合与欠拟合
1.1 过拟合
过拟合 (Overfitting): 过拟合是指模型过度学习了训练数据中的噪声或细节,导致在训练集上表现极好,但在测试集上表现很差。这表明模型缺乏泛化能力,它只是“死记硬背”了训练数据,而不是真正理解了数据的底层模式。
1.2 欠拟合
欠拟合 (Underfitting): 欠拟合是指模型过于简单,无法捕捉训练数据的复杂模式,导致在训练集和测试集上的表现都很差。这同样表明模型缺乏泛化能力,因为它过于简化了问题。
二、泛化能力与模型复杂度
2.1 泛化能力
泛化能力 (Generalization ability) 指的是一个模型在未见过的数据上的表现能力。 它衡量一个模型学习到的知识是否能够推广到新的、不同的数据,而不是仅仅在训练数据上表现良好。 一个具有良好泛化能力的模型,即使面对训练数据中未出现的情况,也能做出准确的预测或决策。
泛化能力是机器学习模型的一个核心指标,直接关系到模型的实际应用价值。 一个具有良好泛化能力的模型才能在实际应用中可靠地做出预测和决策。
泛化:如果一个模型能够对没有见过的数据做出准确预测,我们就说它能够从训练集泛化(generalize)到测试集。
2.2 模型复杂度
模型复杂度: 模型的复杂度与泛化能力密切相关。过于复杂的模型更容易过拟合,而过于简单的模型更容易欠拟合。 寻找一个合适的模型复杂度,平衡训练集和测试集上的性能,是提高泛化能力的关键。
三、拟合、泛化能力和模型复杂度之间权衡关系
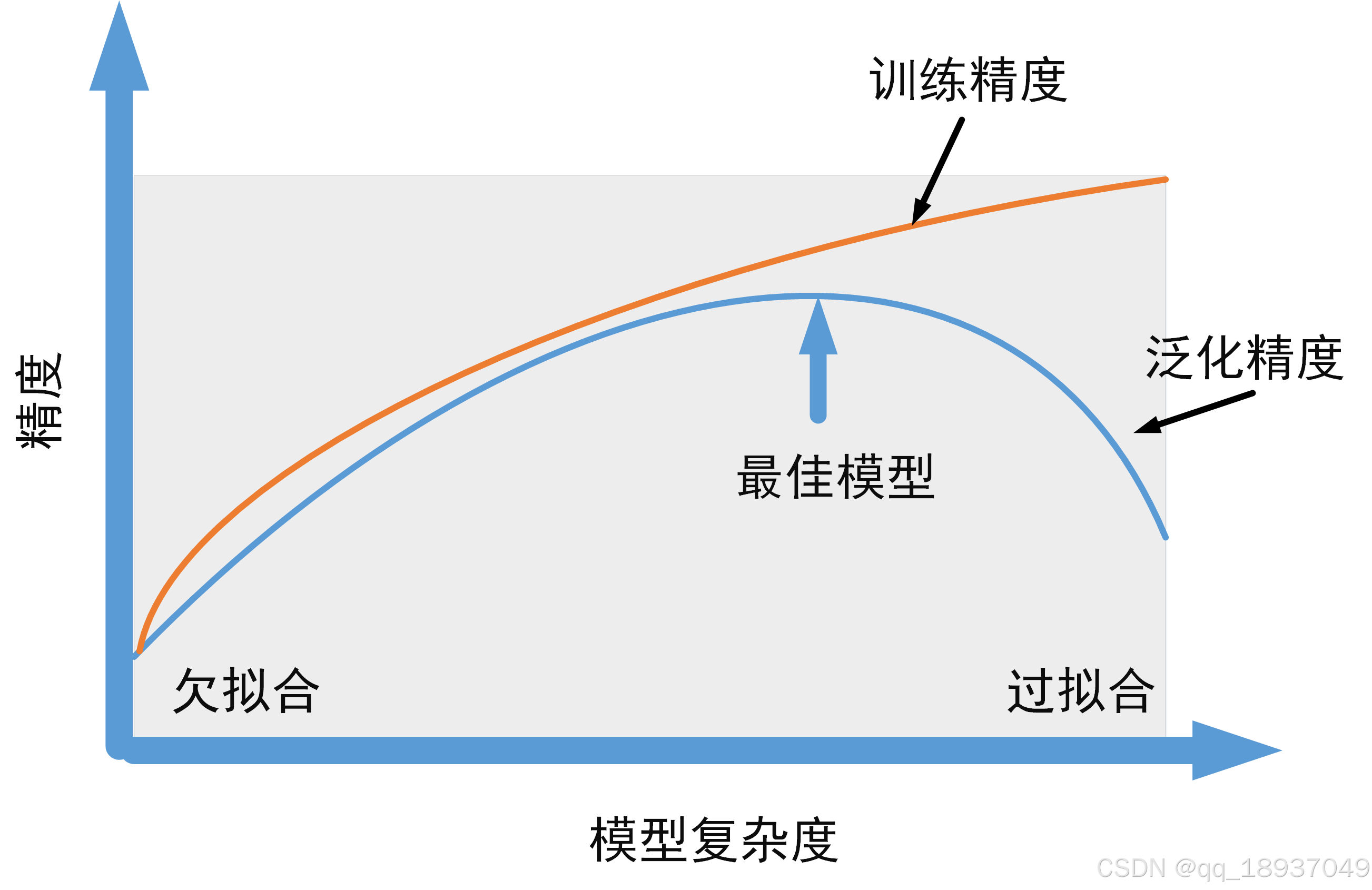
图1 模型复杂度与训练精度和测试精度之间的权衡
四、提高泛化能力的方法
4.1 使用合适的模型: 选择适合你的数据的模型类型。
4.2 使用正则化技术: 限制模型的复杂度。
正则化 (Regularization): 正则化技术(例如L1正则化和L2正则化)可以帮助减少过拟合,从而提高泛化能力。 它们通过对模型参数施加惩罚来限制模型的复杂度。
4.3 使用交叉验证: 更可靠地评估模型的泛化能力。
4.4 增大训练数据集: 提供更多数据供模型学习。
数据量: 充足的训练数据对于提高泛化能力至关重要。 大量的、多样化的数据可以帮助模型学习到更鲁棒的特征表示,减少过拟合的风险。
4.5 进行特征工程: 选择并预处理合适的特征。
特征工程 (Feature Engineering): 选择合适的特征,并对特征进行有效的预处理,可以显著影响模型的泛化能力。 好的特征工程可以帮助模型更好地捕捉数据的底层模式。


















 15
15

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









