






原文链接:https://tecdat.cn/?p=37034
原文出处:拓端数据部落公众号
分析师:Ruoyi Xu
在数据分析的浩瀚宇宙中,我们时常面对多变量的数据海洋。这些变量虽然信息丰富,却也给处理带来了巨大挑战:工作量激增,而关键信息却可能淹没在繁杂的数据之中。为了有效减少指标数量同时尽可能保留原有信息,我们引入了相关性这一强大工具,通过它,我们得以重构数据世界,从而诞生了主成分分析法(PCA)——一种广泛应用的数据降维利器。
【视频讲解】PCA主成分分析原理及R语言经济研究可视化2实例合集
PCA:概念解析
主成分分析法(PCA)是一种精妙的数据处理技术,旨在从原始的高维特征空间中提取出少数几个相互正交的主成分,这些主成分不仅保留了数据的主要变异信息,还极大地简化了后续分析过程。简单来说,PCA就像是在一个由多个坐标轴构成的复杂空间中寻找一组新的、相互垂直的坐标轴,这些新坐标轴能够最佳地代表原始数据的分布情况。
PCA的实施步骤
1. 数据预处理
-
标准化:将不同尺度的数据转化为具有相同尺度的数据,常用的标准化方法包括均值标准化和均方差标准化。这是为了确保数据的准确性和一致性。
-
去平均值:对每一位特征减去各自的平均值,即中心化数据。
2. 计算协方差矩阵
-
协方差矩阵描述了数据之间的相关性,是后续特征值分解的基础。
3. 特征值分解
-
对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。特征值表示了数据中的方差,而特征向量表示了数据的主要方向。
4. 特征值排序
-
根据特征值的大小,对特征值进行排序。特征值越大,表示该特征所包含的信息越多,对数据的解释能力越强。
5. 特征选择(特征转化)
-
选择主成分:根据特征值的排序结果,选择前k个最大的特征值对应的特征向量作为新的特征空间。选择的依据可以是特征值的大小、累计贡献率等。累计贡献率是指前k个特征值的和占总特征值和的比例,通常选择累计贡献率超过一定阈值(如80%)的特征值。
-
数据转换:将原始数据投影到这k个特征向量构建的新空间中,得到降维后的数据。这个过程实际上是数据的特征转化,从原始的高维空间转换到了低维的主成分空间。
6. 解释主成分
-
解释主成分是分析PCA结果的一种方法,可以帮助我们理解主成分的含义和作用。每个主成分都是原始变量的线性组合,具有解释原始变量方差的能力。


PCA的魔力所在
-
信息保留:尽管PCA通过减少变量数量简化了数据,但它却能够最大限度地保留原始数据中的主要变异信息,使得降维后的数据依然具有高度的代表性。
-
去相关性:通过主成分分析,原始变量间的相关性被消除,新生成的主成分之间彼此独立,这大大简化了后续的数据分析和模型构建过程。
-
可视化:对于高维数据,直接可视化几乎是不可能的。而PCA能够将数据降至二维或三维空间,使我们能够直观地观察数据的分布情况和内在结构。
R语言主成分分析(PCA)葡萄酒可视化:主成分得分散点图和载荷图
我们将使用葡萄酒数据集进行主成分分析。
数据
数据包含177个样本和13个变量的数据框;vintages包含类标签。这些数据是对生长在意大利同一地区但来自三个不同栽培品种的葡萄酒进行化学分析的结果:内比奥罗、巴贝拉和格里格诺葡萄。来自内比奥罗葡萄的葡萄酒被称为巴罗洛。
这些数据包含在三种类型的葡萄酒中各自发现的几种成分的数量。
# 看一下数据
head(no)输出

转换和标准化数据
对数转换和标准化,将所有变量设置在同一尺度上。
# 对数转换
no_log <- log(no)
# 标准化
log_scale <- scale(no_log)
head(log_scale)
主成分分析(PCA)
使用奇异值分解算法进行主成分分析
prcomp(log_scale, center=FALSE)
summary(PCA)
基本图形(默认设置)
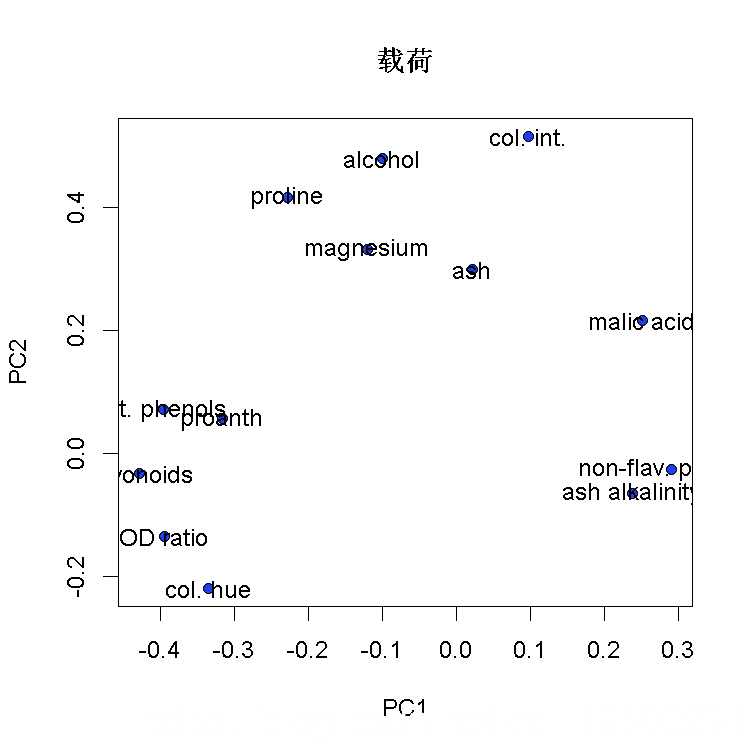
带有基础图形的主成分得分和载荷图
plot(scores[,1:2], # x和y数据
pch=21, # 点形状
cex=1.5, # 点的大小
legend("topright", # legend的位置
legend=levels(vint), # 图例显示
plot(loadings[,1:2], # x和y数据
pch=21, # 点的形状
text(loadings[,1:2], # 设置标签的位置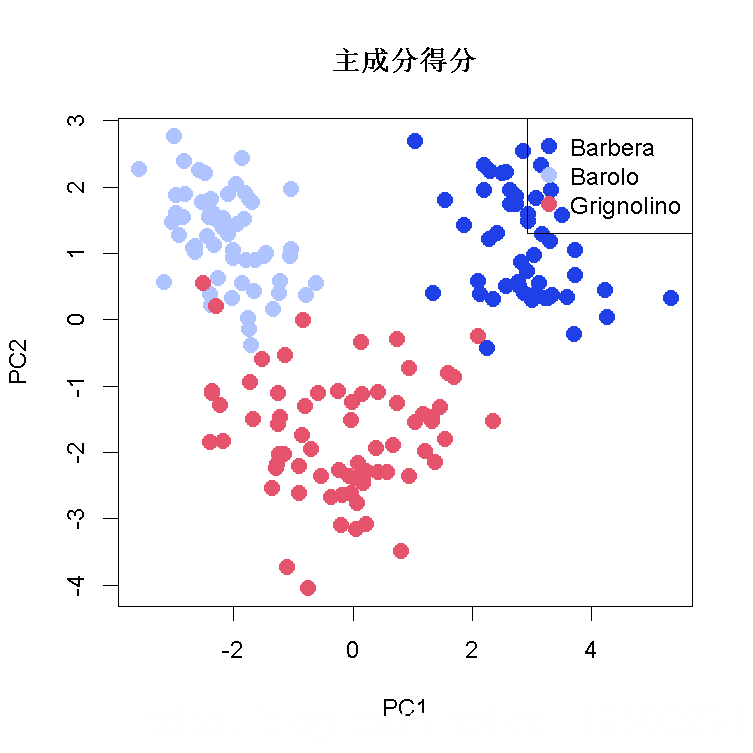
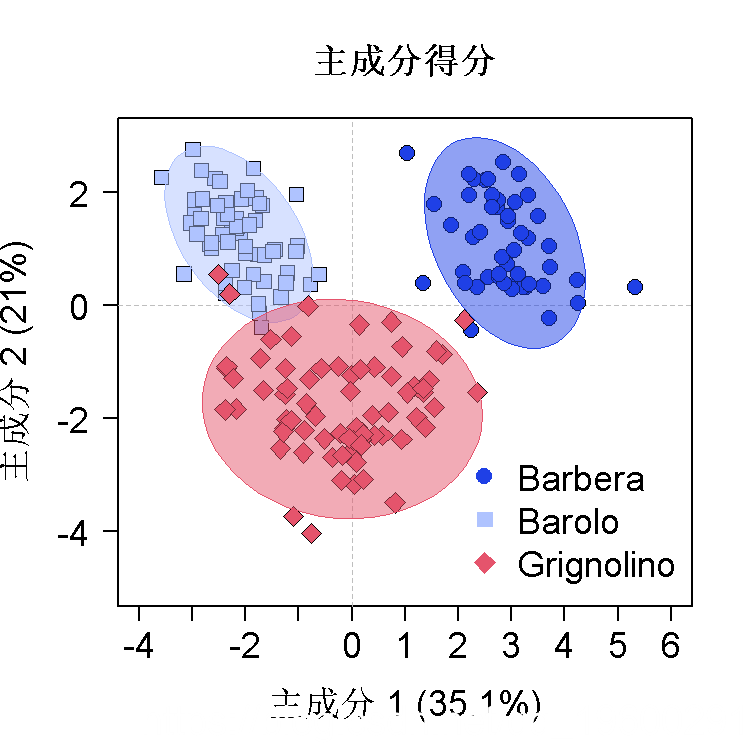
此外,我们还可以在分数图中的组别上添加95%的置信度椭圆。
置信度椭圆图函数
## 椭圆曲线图
elev=0.95, # 椭圆概率水平
pcol=NULL, # 手工添加颜色,必须满足长度的因素
cexsize=1, # 点大小
ppch=21, # 点类型,必须满足因素的长度
legcexsize=2, # 图例字体大小
legptsize=2, # 图例点尺寸
## 设定因子水平
if(is.factor(factr) {
f <- factr
} else {
f <- factor(factr, levels=unique(as.character(factr)))
}
intfactr <- as.integer(f) # 设置与因子水平相匹配的整数向量
## 获取椭圆的数据
edf <- data.frame(LV1 = x, LV2=y, factr = f) # 用数据和因子创建数据框
ellipses <- dlply(edf, .(factr), function(x) {
Ellipse(LV1, LV2, levels=elev, robust=TRUE, draw=FALSE) #从dataEllipse()函数中按因子水平获取置信度椭圆点
})
## 获取X和Y数据的范围
xrange <- plotat(range(c(as.vector(sapply(ellipses, function(x) x[,1])), min(x), max(x))))
## 为图块设置颜色
if(is.null(pcol) != TRUE) { # 如果颜色是由用户提供的
pgcol <- paste(pcol, "7e", sep="") # 增加不透明度
# 绘图图形
plot(x,y, type="n", xlab="", ylab="", main=""
abline(h=0, v=0, col="gray", lty=2) #在0添加线条
legpch <- c() # 收集图例数据的矢量
legcol <- c() # 收集图例col数据的向量
## 添加点、椭圆,并确定图例的颜色
## 图例
legend(x=legpos, legend=levels(f), pch=legpch,
## 使用prcomp()函数的PCA输出的轴图示
pcavar <- round((sdev^2)/sum((sdev^2))基础图形
绘制主成分得分图,使用基本默认值绘制载荷图
plot(scores[,1], # X轴的数据
scores[,2], # Y轴的数据
vint, # 有类的因素
pcol=c(), # 用于绘图的颜色(必须与因素的数量相匹配)
pbgcol=FALSE, #点的边框是黑色的?
cexsize=1.5, # 点的大小
ppch=c(21:23), # 点的形状(必须与因子的数量相匹配)
legpos="bottom right", # 图例的位置
legcexsize=1.5, # 图例文字大小
legptsize=1.5, # 图例点的大小
axissize=1.5, # 设置轴的文字大小
linewidth=1.5 # 设置轴线尺寸
)
title(xlab=explain[["PC1"]], # PC1上解释的方差百分比
ylab=explain[["PC2"]], # PC2解释的方差百分比
main="Scores", # 标题
cex.lab=1.5, # 标签文字的大小
cex.main=1.5 # 标题文字的大小
plot(loadings[,1:2], # x和y数据
pch=21, # 点的形状
cex=1.5, # 点的大小
# type="n", # 不绘制点数
axes=FALSE, # 不打印坐标轴
xlab="", # 删除x标签
ylab="" # 删除y标签
)
pointLabel(loadings[,1:2], #设置标签的位置
labels=rownames(PCAloadings), # 输出标签
cex=1.5 # 设置标签的大小
) # pointLabel将尝试将文本放在点的周围
axis(1, # 显示x轴
cex.axis=1.5, # 设置文本的大小
lwd=1.5 # 设置轴线的大小
)
axis(2, # 显示y轴
las=2, # 参数设置文本的方向,2是垂直的
cex.axis=1.5, # 设置文本的大小
lwd=1.5 # 设置轴线的大小
)
title(xlab=explain[["PC1"]], # PC1所解释的方差百分比
ylab=explain[["PC2"]], # PC2解释的方差百分比
cex.lab=1.5, # 标签文字的大小
cex.main=1.5 # 标题文字的大小
)

R语言主成分pca、因子分析、聚类对地区经济研究分析重庆市经济指标
最近我们被客户要求撰写关于重庆市经济指标的研究报告,包括一些图形和统计输出。
建立重庆市经济指标发展体系,以重庆市一小时经济圈作为样本,运用因子分析方法进行实证分析,在借鉴了相关评价理论和评价方法的基础上,本文提取出经济规模、人均发展水平、经济发展潜力、3个主因子,从重庆市统计年鉴选取8个指标构成的指标体系数据对重庆市38个区县经济发展基本情况的八项指标进行分析,并基于主因子得分矩阵对重庆市38个区县进行聚类分析
结果表明:根据综合得分,可以看出各区县社会经济发展水平排前三的是渝中区、渝北区、九龙坡区,得分最低的三个是巫山县、巫溪县、城口县,结合总体的分析可以看出渝中区、九龙坡区在经济总体规模和建筑业方面较好,而重庆周边的地区经济实力较差,投资环境不好,特别是在建筑方面的缺乏,以至于经济发展相对而言薄弱的地区,不论从哪方面来说重庆各区县中渝中区的经济实力是最好的。
评价指标的建立
评价地区的之间的经济发展水平,必须建立适当的指标体系。考虑到地区经济指标的复杂性、多样性和可操作性,本文在此基础上建立了一套较为完整的易于定量分析的地区经济评价指标体系,分别从不同的角度反映地区经济发展特征。
本文所建立的指标体系共包括8个指标,分别从经济规模、人均发展水平、经济发展潜力等方面来反映地区经济发展特征。具体指标如下:
地区生产总值(万元)(X1)
社会消费品零售总额(万元)(X2)
工业总产值(万元)(X3)
建筑业总产值(万元)(X4)
高技术生产总值(万元)(X5)
全社会固定资产投资(万元)(X6)
人均可支配收入(元)(X7)
人均地区生产总值(元)(X8)
因子分析在地区经济研究中的应用
因子分析模型及其步骤
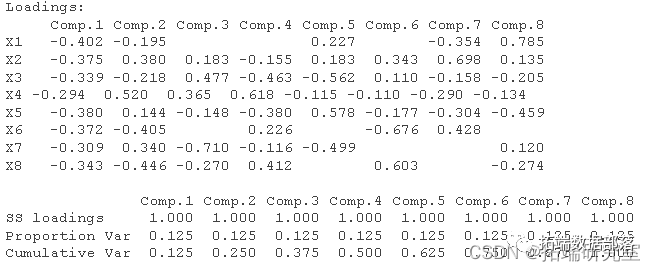
因子分析是一种数据简化的技术。它通过研究众多变量之间的内部依赖关系,探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。这几个假想变量能够反映原来众多变量的主要信息。原始的变量是可观测的显在变量,而假想变量是不可观测的潜在变量,称为因子。设p个变量,则因子分析的数学模型可表示为:
![]()
称
![]()
为公共因子,是不可观测的变量,他们的系数称为因子载荷。是特殊因子,是不能被前m个公共因子包含的部分。因子分析步骤如下:
(1)将原始数据标准化,仍记为X;(2)建立相关系数矩阵R;(3)解特征方程,计算特征值和特征向量,当累计贡献率不低于85%时,提取k个主成分代替原来的m个指标,计算因子载荷矩阵A;(4)对A进行最大正交旋转交换;(5)对主因子进行命名和解释。如需进行排序,则计算各个主因子的得分,以贡献率为权重,对加权计算综合因子得分。
样本选取及数据来源
本文选取了重庆市38个区县作为样本进行分析,目的在于探索如何基于R统计软件的因子分析和聚类分析方法研究地区经济发展。具体数据如下:
数据分析过程
将原始数据录入R软件中,选取地区生产总值(万元)(X1)、社会消费品零售总额(万元)(X2)、工业总产值(万元)(X3)、建筑业总产值(万元)(X4)、高技术生产总值(万元)(X5)、全社会固定资产投资(万元)(X6)、人均可支配收入(元)(X7)、人均地区生产总值(元)(X8)。
在进行因子分析之前,我们通过观察相关系数矩阵,并用KMO and Bartlett’s Test检验一下数据是否适合作因子分析。再做描述性分析Analysis-factor-description得到初始公因子方差、因子、特征值以及由每个因子解释的百分比和累计百分比。分析结果如下:
coebaltt(COR,)#Bartlett球形检
Bartlett 的球形度检验的p值(显著性概率值sig)<0.05,表明通过检验,分布可以近似为正态分布,由此则可以进行因子分析。
sreeot(PCA,type="lines")
从表可以得出,提取3个因子的累计方差贡献率已经达到89.854%>86%,信息损失仅为10.146%,从第4个因子开始方差贡献率都低于5%,因此选取3个公因子进行因子分析效果较为理想;从图的碎石图可以看出从第4个因子开始,特征值差异变化很小,综上所述:在特征值大于0.5的条件下,所提取的三个因子能通过检验并能很好的描述8个指标,所以提取前3个特征值建立因子载荷矩阵。
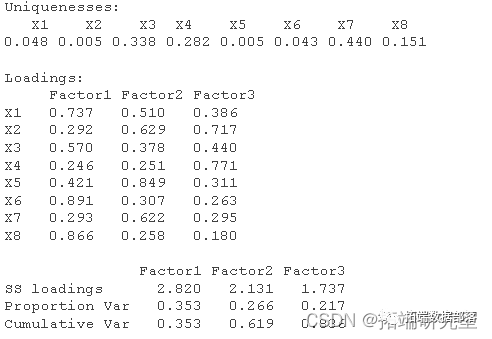
表中为初始因子载荷矩阵表, F1、F2、F3分别作为第一、第二、第三公共因子。建立了因子分析数学目的不仅仅要找出公共因子以及对变量进行分组,更重要的要知道每个公共因子的意义,以便进行进一步的分析,如果每个公共因子的含义不清,则不便于进行实际背景的解释。由于因子载荷阵是不唯一的,所以应该对因子载荷阵进行旋转。目的是使因子载荷阵的结构简化,使载荷矩阵每列或行的元素平方值向0和1两极分化。有三种主要的正交旋转法。四次方最大法、方差最大法和等量最大法。
因此需求进行因子旋转,使得因子对变量的贡献达到极化的效果。为此采用方差最大化的正交旋转方式,使各变量在某个因子上产生较高载荷,而其余因子上载荷较小,从而得到旋转后的因子载荷矩阵,如下表所示:
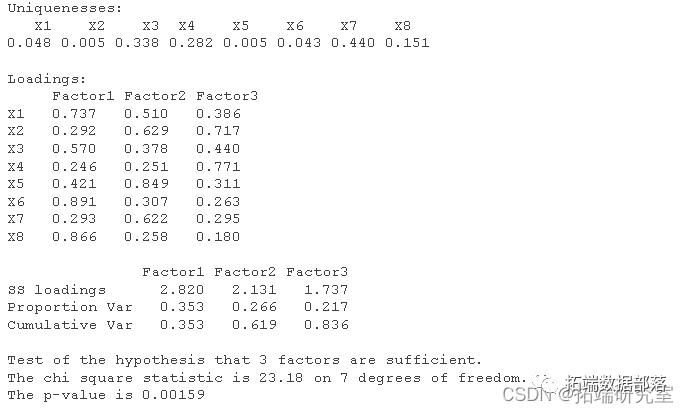
由表和旋转后的因子图可以看出,通过旋转后的公共因子的解释原始数据的能力提高了,表现为公共因子F1在X1(地区生产总值),X6(全社会固定资产投资)和X8(人均地区生产总值)上的载荷值都很大。因此我们可以把第一公共因子确立为综合经济实力因子,宏观上反映了地区经济发展规模的总体情况,在这个因子上的得分越高,说明城市经济发展的总体情况越好。
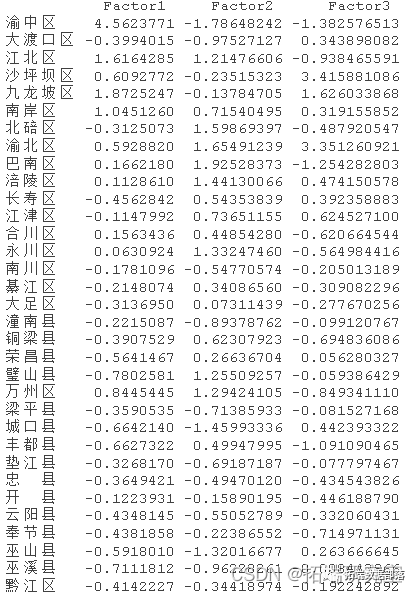
利用各公共因子方差贡献率计算综合得分,并计算综合得分=因子1的方差贡献率因子1的得分+因子2的方差贡献率因子2的得分+因子3的方差贡献率*因子3的得分。将数据按综合得分降序排列,得到部分因子得分和综合得分情况如下图所示:


结果讨论
基于上述因子得分,可以得出2012年重庆38个区县的经济发展状况如下:
1、根据经济实力因子F1得分大于1的依次有渝中区、渝北区、九龙坡区、江北区和万州区,分数分别为4.4211、1.8967、1.7808、1.201、1.2804。说明在经济总体规模和建筑业方面,渝中区、渝北区、九龙坡、江北区和万州区在重庆市的38个区县中是最好的,规模较大,经济实力最强,发展前景很好,经济发展实力雄厚的地区。
2、根据经济发展潜力因子F2得分大于1的有沙坪坝区和渝北区,分数分别为3.7052、3.4396。说明在高技术科技和工业方面比较发达,固定资产投资最大,这两个地区都在主城,对外开放程度高,科技创新方面比较好,有自己的工业发展,已基本形成了自己的产业结构,充分发挥了自己的地理优势和资源环境优势,发展潜力较大。
基于主因子得分的聚类分析
系统聚类分析
聚类分析又称群分析,就是将数据分组成为多个类。在同一个类内对象之间具有较高的相似度,不同类之间的对象差别较大。在社会经济领域中存在着大量分类问题,比如若对某些大城市的物价指数进行考察,而物价指数很多,有农用生产物价指数、服务项目价指数、食品消费物价指数、建材零售价格指数等等。由于要考察的物价指数很多,通常先对这些物价指数进行分类。总之,需要分类的问题很多,因此聚类分析这个有用的工具越来越受到人们的重视,它在许多领域中都得到了广泛的应用。
聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等;最常用最成功的聚类分析为系统聚类法,系统聚类法的基本思想为先将n个样品各自看成一类,然后规定样品之间的“距离”和类与类之间的距离。选择距离最近的两类合并成一个新类,计算新类和其他类(各当前类)的距离,再将距离最近的两类合并。这样,每次合并减少一类,直至所有的样品都归成一类为止。
系统聚类法的基本步骤:
1、计算n个样品两两间的距离。
2、构造n个类,每个类只包含一个样品。
3、合并距离最近的两类为一新类。
4、计算新类与各当前类的距离。
5、重复步骤3、4,合并距离最近的两类为新类,直到所有的类并为一类为止。
6、画聚类谱系图。
7、决定类的个数和类。
系统聚类方法:1、最短距离法;2、最长距离法;3、中间距离法;4、重心法;5、类平均法;6、离差平方和法(Ward法)。
基于主因子得分对重庆市38个区县经济发展分析,采用聚类方法选择组间链接法,计算距离选择平方欧式距离,标准化数据才用标准正太数据化处理。得到如下结果:
rct.st(hc,k = 6, border = "red")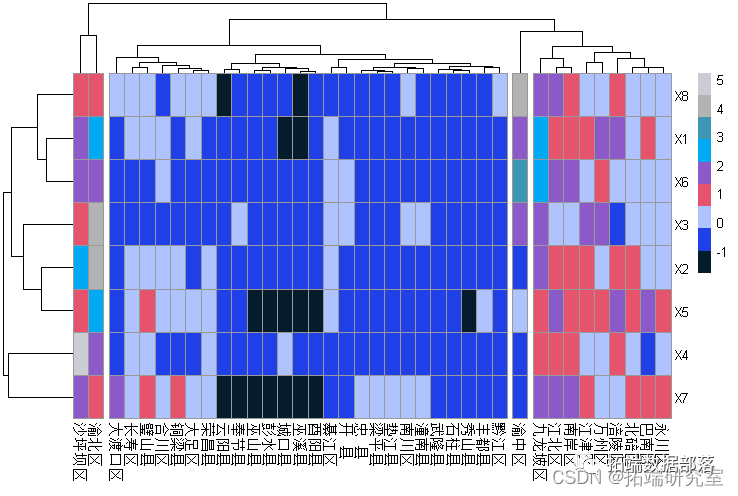
由树状图可知,可以将重庆各区县按经济中和实力实际情况分为六类:
第一类只包括渝中区,渝中区是重庆市的中心城市,是重庆市的政治经济文化中心、基础教育高地、具有特殊的区位优势和突出的战略地位。产业结构的现状特征是第三产业占绝对优势,其中金融业、商贸业以及中介服务业为主导行业,属于经济发展实力雄厚的地区。
第二类只包括渝北区,渝北区先后启动了总体规划近65平方公里的重庆科技产业园、重庆现代农业园区、渝东开发区等项目,被市政府命名为"重庆农业科技园区",所以该地区在高技术生产总值贡献很大,而且投资环境优越,且大部分地区有个自己中心商业地带,对外开放程度高,区位优势很明显,产业结构合理,属于经济发展较强的地区。
关于分析师
![]()
在此对Ruoyi Xu对本文所作的贡献表示诚挚感谢,她在重庆大学完成了数据科学与大数据技术专业学位,专注深度学习、数据挖掘、数据分析领域。擅长Python 。

















 686
686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









