









最近我们被要求撰写关于时间序列聚类的研究报告,包括一些图形和统计输出。
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
,时长06:05
本文我们将使用k-Shape时间序列聚类方法检查与我们有业务关系的公司的股票收益率的时间序列。
企业对企业交易和股票价格
在本研究中,我们将研究具有交易关系的公司的价格变化率的时间序列的相似性。
由于特定客户的销售额与供应商公司的销售额之比较大,当客户公司的股票价格发生变化时,对供应商公司股票价格的反应被认为更大。
k-Shape
k-Shape [Paparrizos和Gravano,2015]是一种关注时间序列形状的时间序列聚类方法。在我们进入k-Shape之前,让我们谈谈时间序列的不变性和常用时间序列之间的距离测度。
时间序列距离测度
欧几里德距离(ED)和动态时间规整(DTW)通常用作距离测量值,用于时间序列之间的比较。
两个时间序列x =(x1,...,xm)和y =(y1,...,ym)的ED如下。

DTW是ED的扩展,允许局部和非线性对齐。
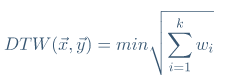
k-Shape提出称为基于形状的距离(SBD)的距离。
k-Shape算法
k-Shape聚类侧重于归一化和移位的不变性。k-Shape有两个主要特征:基于形状的距离(SBD)和时间序列形状提取。
SBD
互相关是在信号处理领域中经常使用的度量。使用FFT(+α)代替DFT来提高计算效率。
![]()
归一化互相关(系数归一化)NCCc是互相关系列除以单个系列自相关的几何平均值。检测NCCc最大的位置ω。
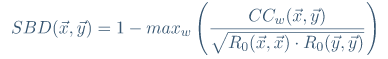
SBD取0到2之间的值,两个时间序列越接近0就越相似。
形状提取
通过SBD找到时间序列聚类的质心向量 。
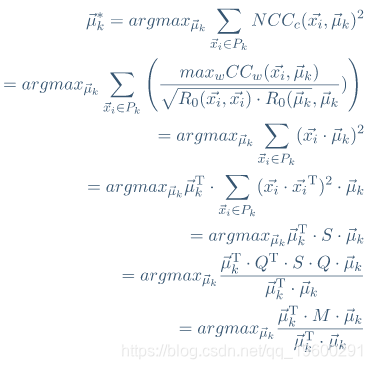
k-Shape的整个算法如下。
k-Shape通过像k-means这样的迭代过程为每个时间序列分配聚类簇。
- 将每个时间序列与每个聚类的质心向量进行比较,并将其分配给最近的质心向量的聚类
- 更新群集质心向量
重复上述步骤1和2,直到集群成员中没有发生更改或迭代次数达到最大值。
R 语言k-Shape
> start <- "2014-01-01"
> df_7974 %>%
+ filter(date > as.Date(start))
# A tibble: 1,222 x 10
date open high low close volume close_adj change rate_of_change code
1 2014-01-06 14000 14330 13920 14320 1013000 14320 310 0.0221 7974
2 2014-01-07 14200 14380 14060 14310 887900 14310 -10 -0.000698 7974
3 2014-01-08 14380 16050 14380 15850 3030500 15850 1540 0.108 7974
4 2014-01-09 15520 15530 15140 15420 1817400 15420 -430 -0.0271 7974
5 2014-01-10 15310 16150 15230 16080 2124100 16080 660 0.0428 7974
6 2014-01-14 15410 15755 15370 15500 1462200 15500 -580 -0.0361 7974
7 2014-01-15 15750 15880 15265 15360 1186800 15360 -140 -0.00903 7974
8 2014-01-16 15165 15410 14940 15060 1606600 15060 -300 -0.0195 7974
9 2014-01-17 15100 15270 14575 14645 1612600 14645 -415 -0.0276 7974
10 2014-01-20 11945 13800 11935 13745 10731500 13745 -9缺失度量用前一个工作日的值补充。(K-Shape允许一些偏差,但以防万一)
每种股票的股票价格和股票价格变化率。
将zscore作为“preproc”,“sbd”作为距离,以及centroid =“shape”,k-Shape聚类结果如下。
> df_res %>%
+ arrange(cluster)
cluster centroid_dist code name
1 1 0.1897561 1928 積水ハウス
2 1 0.2196533 6479 ミネベアミツミ
3 1 0.1481051 8411 みずほ
4 2 0.3468301 6658 シライ電子工業
5 2 0.2158674 6804 ホシデン
6 2 0.2372485 7974 任天堂Nintendo,Hosiden和Siray Electronics Industries被分配到同一个集群。Hosiden在2016年对任天堂的销售比例为50.5%,这表明公司之间的业务关系也会影响股价的变动。
另一方面,MinebeaMitsumi成为另一个集群,但是在2017年Mitsumi与2017年的Minebea合并, 没有应对2016年7月Pokemon Go发布时股价飙升的影响 。
如果您有任何疑问,请在下面发表评论。

最受欢迎的见解
3.R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
5.Python Monte Carlo K-Means聚类实战
















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









