






CLIP论文精度
-
Zero-shot
-
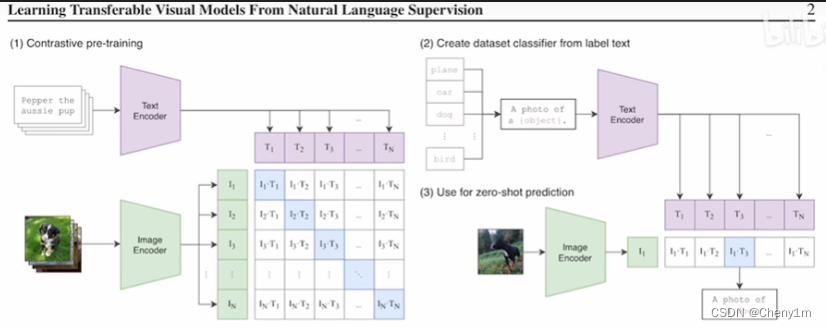
CLIP多模态模型
-
Image Endecoder是一个图片编码器,既可以是ResNet,也可以是Vision Transformer.
-
Text Encoder和Image Encoder产生的两组特征进行对比学习(无监督训练)
-
分类头?“分类头” 是指网络结构中用于执行具体分类任务的一组层,将网络提取的特征转化为分类或检测结果。
-
CLIP训练好后,没有使用微调,所以也就没有分类头,而利用它做推理的过程是借用了自然语言处理(NLP)的方法,也就是prompt template.
-
把每个分类类别变成相应的句子,句子通过之前训练好的文本编码器Text Encoder后就会得到对应数量文本的特征。做这一步的原因是因为在训练过程中,输入到Text Encoder中的是一个句子,为了保证模型输出的效果,所以采用输入形式的一致。
-
关于如何将分类的每个标签变成一个句子,OpenAI也提出了prompt engineering和prompt ensemble这两种方式来提高模型的准确率。
-
在推理的过程中,对于输入的图片,经过ImageEncoder后,得到图片特征,然后跟所有的文本特征去计算一个cosine similarity(相似性),将与图片最相近的一个文本挑出来,完成分类任务。
-
categorical label限制。需要在训练或者推理时,提前准备一个标签的列表,以编写分类头。而CLIP则是摆脱了这种限制。
-
CLIP迁移性非常强,因为他学习到的语义性强。
-
CLIP的应用:图像生成、物体检测和分割、视频检索clifs。
> Abstract
- CLIP出来前,先进的视觉系统训练都需要一个提前定义好的标签集合,但采用这样有限制性的监督学习很可能会模型的泛化性。
- 所以CLIP从NLP中得到监督信息,因为本文描述的监督信号非常广。
- CLIP使用4亿个文本-图像训练集去进行了大模型的训练。生成的模型可以直接用于下游的Zero-shot推理。
- OpenAI公开了CLIP的预训练模型和推理代码,但没公开预训练代码。
> Introduction
- 从原始的文本里去预训练一个模型在NLP领域取得了成功。(如GPT,它的模型架构同样也是与下游任务无关的,所以直接应用在下游应用时,无需去设计分类头等特殊处理。)
- 所以CLIP将NLP里面的这套框架应用到了视觉里面。
- 自监督学习:transformer、对比学习、掩码填空、自回归。
- CLIP主打泛化性。
> Approach
-
利用自然语言的监督信号来训练一个比较好的视觉模型。好处:
- 不需要标注数据,只需要文本-图片配对集。
- 训练时,图片和文字绑定,所以学习到的是一个多模态特征。
-
Transformer出现后,为NLP带来革命性的改变,开始使用具有上下文语义环境的学习方式去替代传统且复杂的Topic model和n-gram等。让其可以比较方便地进行跨模态训练。
-
大数据集:WebImageText:WIT
-
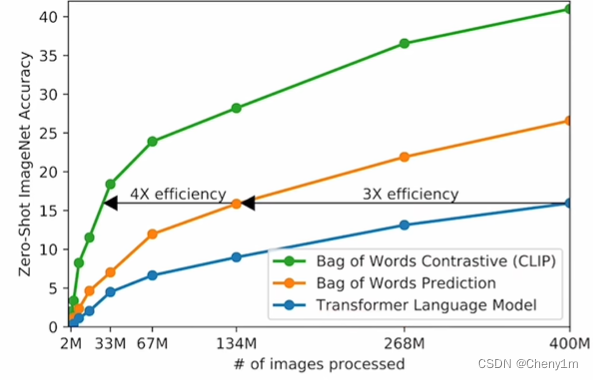
由于数据集巨大,训练成本高时间长,所以训练效率对多模态的训练效果有直接影响。所以CLIP由于训练效率的原因,使用了对比学习的方法,而非预测性的方法。
-
仅仅把预测型的目标函数改为对比型的目标函数,训练效率就提升了4倍。
-
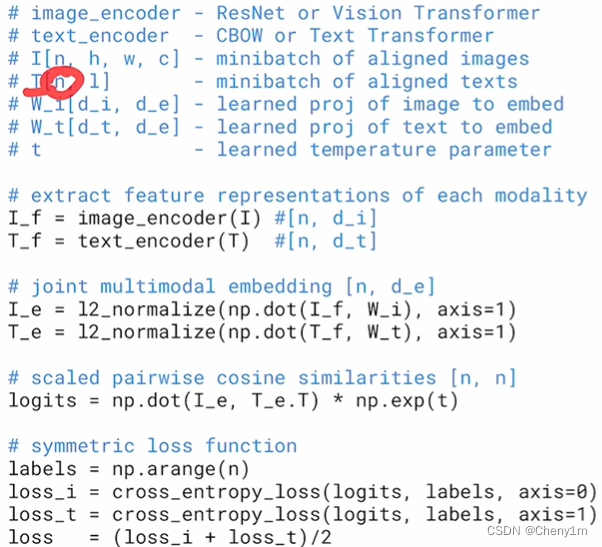
模型预训练伪代码:与其他对比学习没有太大区别,主要是将单模态正样本替换成了多模态正样本。
- CLIP数据集较大,不太会产生过拟合的情况。
- 它在最后的投射中(表示和对比学习层之间)仅使用了线性的投射层。
- 同时由于数据集太大,也不需要做过多的数据增强(?),唯一使用的是随机的剪裁。
- 由于模型太耗时,不好做微调,所以将对比学习中的超参数temperature在模型中重新设置为可学习的参数。
-
训练过程:
视觉方面:训练了8种模型,ResNet-50,ResNet-101,和三个基于EfficientNet-style model改进的ResNet变体。同时还使用了3个Vision Transformers,包括ViT-B/32,ViT-B/16,ViT-L/14。-
32 epochs。
-
使用Adam optimizer优化器
-
对超参数进行了grid searches,random search或者manual tuning。
-
bitch size = 32768
-
使用了混精度训练
-
工程上的问题:

-
训练Vision transformer比训练残差网络高效。
-
> Experiments
-
Zero-shot Transfer:
- 动机:一旦借助文本训练好了这个又大又好的模型之后,就可以使用文本做引导,去灵活地做zero shot的迁移学习。而不必再进行微调。
- 推理过程:
-
Prompt engineering and ensembling:
- Prompt是在微调或者直接推理时用的一种方法。
- 需要使用Prompt,是因为1.单个单词具有歧义性。2.预训练的时候输入是文本信息,而非单词,为了防止出现分布偏移(distribution gap)问题。
- 所以作者使用Prompt template
A photo of a {label}来描述推理时的输入,可以使模型准确率得到提升。 - 如果你已经提前知道类别,那么可以添加更多的提示词来使模型的输出更加准确。
- Prompt ensemble就是利用多段提示词,最后将结果聚合起来。
-
few-shot transfer(每个类别拿出少量图片来做微调):将CLIP里面的图片编码器拿出来“冻住”,去做linear probe(对最后的分类头进行训练)。
-
如果下游任务用全部的数据而不是zero/few shot:
- 方法1:linear probe
- 方法2:fine-tune ,把整个网络都放开,直接去做端对端的学习。比linear probe更灵活、数据集大的时候效果更好。
-
而在CLIP中,作者专门使用了linear probe,是因为(1)CLIP本来就是用来研究跟数据集无关的预训练方式的,能能好地反映出预训练模型的好坏(2)linear probe不用调参来适应各个数据集。
Limitations
- CLIP在大多数模型平均下来来看,只是与比较简单的机械模型打成平手,而无法与state of the art(SOTA,最前沿)的结果媲美。
扩大训练数据集是一个不太可能的方案(要达到SOTA的效果,需要再训练当前的1000X+),所以需要有新的方法在计算和数据上更加高效。 - CLIP在细分类任务和抽象概念的处理上表现得较差。
- CLIP的泛化性较好,但推理数据集不能out-of-distribution。
- 虽然CLIP可以用zero-shot去做推理,但仍然是从给定的类别里去做的选择。所以OpenAI还是想将其作为生成式的模型。
- 数据利用率不高效。(预训练)
- 数据没有经过清洗,可能会带着社会的偏见。
Conclusion
- CLIP的宗旨就是想把NLP领域当中与下游任务无关的训练方式带到其他领域中去。
- CLIP方法总结:在预训练阶段使用对比学习,利用文本的提示去做zero shot的迁移学习。在大数据和大模型的双向加持下,CLIP的效果能和之前精心设计的且是有监督训练出来的基线模型打成平手。

















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









