









论文地址:Cutout
论文总结
本文的方法名为cutout,是一种数据增强的方法,主要应用于分类任务中。
cutout的实现方法为,在图像中随机选取一个点作为中心点,覆盖一个固定大小的方形zero-mask。mask的大小是一个超参数,在文中是通过网格搜索得到的长度。mask区域可以在图像外。

论文介绍
cutout方法提出的出发点是作为一个正则化方法,防止CNN过拟合。cutcout方法很简单,就是在训练的时候,在随机位置应用一个方形矩阵。
作者认为这种技术鼓励网络去利用整个图片的信息,而不是依赖于小部分特定的视觉特征。
相比于dropout,cutout更像是数据增强的一种手段,而不是添加噪声。
在刚开始应用maks的时候,作者也尝试应用mask于关键部位(那些激活值最大的区域),并得到了不错的结果(如下图所示)。但后来发现随机去除固定大小区域和直接在目标区域的效果是相当的,所以之后都采用移除固定大小区域的策略。

同时,作者发现zero-mask区域大小的选择比形状的选择更重要。大小的选择在文中是通过网格搜索完成的,但都是应用于较小的数据集(CIFAR10/CIFAR100/SVHN)上。在选择应用区域的时候,发现zero-mask随机应用效果比较好,即部分mask在图像外。作者解释为,部分mask在图像外是实现良好性能的关键。
论文实验
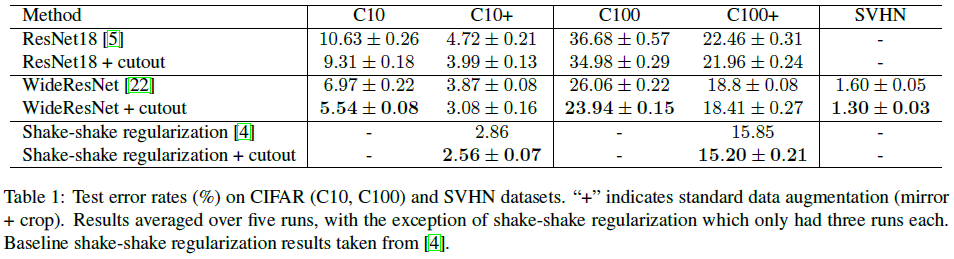
CIFAR-10和CIFAR-100
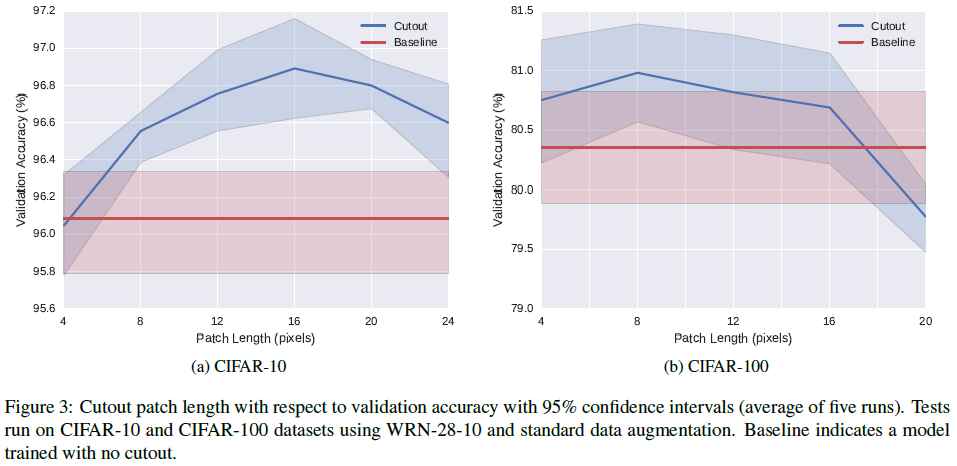
CIFAR数据集的图像大小为 32 ∗ 32 32*32 32∗32。通过网格搜索zero-mask的边长,边长和accuracy上的关系如下:在CIFAR10上选择 16 ∗ 16 16*16 16∗16像素,在CIFAR100上选择 8 ∗ 8 8*8 8∗8像素。 作者认为,随着类别增加,最优cutout size在减小,这点是重要的。当需要更细粒度的检测时,图像的上下文信息在识别类别时就不太有用了。相反,更小更细微的细节是更重要的。
SVHN
SVHN数据集的图像大小为 32 ∗ 32 32*32 32∗32,最后的cutout size为 20 ∗ 20 20*20 20∗20。
STL-10
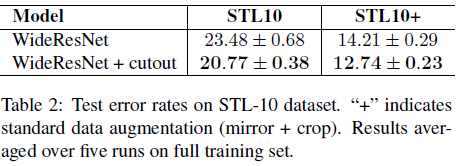
STL-10数据集的图像大小为 96 ∗ 96 96*96 96∗96,最后的cutout size为 24 ∗ 24 24*24 24∗24(没有数据增强时)或 32 ∗ 32 32*32 32∗32(有数据增强时)。
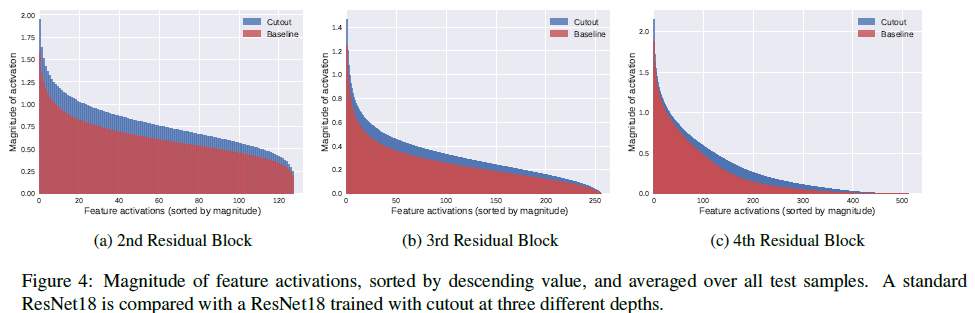
Cutout对激活值的影响
在应用cutout后,作者发现浅层激活值强度普遍增加,在深层激活值增加的主要在尾部。

















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









