








博主最近在逛Github,发现一个刚推出的Star指数迅速上升的Github开源项目,该项目可实现提取部分语音的片段就可以仿照说话者的特色去生成不同语言,甚至不同情感、口音、韵律、停顿和语调,也就是使用它可以细致地控制语音风格。这个项目是myshell-ai开源的OpenVoice项目。
仅开源了不到三周,就有了6.1k的star,还是可以的。

OpenVoice除了灵活的语音风格控制外,还实现了零样本跨语言语音克隆,也就是不需要庞大说话者训练集中的语言,与先前的方法不同,先前的方法通常需要为所有语言提供大规模说话者多语言(MSML)数据集,而OpenVoice可以在没有该语言的大规模说话者训练数据的情况下将语音克隆到新语言中,下面是它的功能详细介绍:
We introduce OpenVoice, a versatile voice cloning approach that requires only a short audio clip from the reference speaker to replicate their voice and generate speech in multiple languages. OpenVoice represents a significant advancement in addressing the following open challenges in the field: 1) Flexible Voice Style Control. OpenVoice enables granular control over voice styles, including emotion, accent, rhythm, pauses, and intonation, in addition to replicating the tone color of the reference speaker. The voice styles are not directly copied from and constrained by the style of the reference speaker. Previous approaches lacked the ability to flexibly manipulate voice styles after cloning. 2) Zero-Shot Cross-Lingual Voice Cloning. OpenVoice achieves zero-shot cross-lingual voice cloning for languages not included in the massive-speaker training set. Unlike previous approaches, which typically require extensive massive-speaker multi-lingual (MSML) dataset for all languages, OpenVoice can clone voices into a new language without any massive-speaker training data for that language. OpenVoice is also computationally efficient, costing tens of times less than commercially available APIs that offer even inferior performance. To foster further research in the field, we have made the source code and trained model publicly accessible. We also provide qualitative results in our demo website. Prior to its public release, our internal version of OpenVoice was used tens of millions of times by users worldwide between May and October 2023, serving as the backend of MyShell.
从下面官网提供的流程可以看到,OpenVoice基于一定的文本内容+口音情感风格参数生成了一个基础的说话者TTS模型,然后基于此模型,用户只需要输入自己的声音片段,便可以根据里面的口音生成不同语言且可控的说话风格。
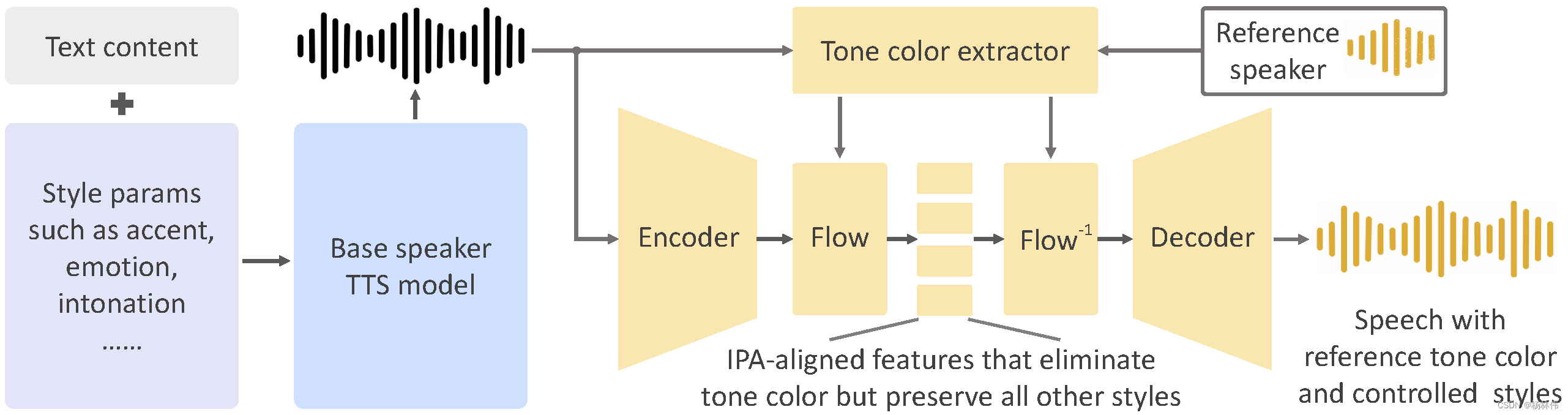
具体的视频和演示效果大家可以去官网查看:https://research.myshell.ai/open-voice

















 6168
6168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









