







K 最近邻 (k-Nearest Neighbor,KNN) 分类算法
利用训练数据集对特征向量空间进行划分
三要素: k值的选择、距离度量、分类决策规则
k近邻算法
(1)给定距离度量,在训练集T中找到与x最近邻的k个点
涵盖这k个点的x领域记作Nk(x);
(2)在Nk(x)中根据分类决策规则(如多数表决)决定x的类别y:
y=argmax∑I(yi=cj), i=1,2...N;j=1,2...K
I为指示函数,yi=cj 时 I =1,否则 I =0.
K=1时称为最近邻算法
k近邻没有显式的学习过程
k近邻模型

1:距离度量
-
距离度量一般采用 Lp 距离
-
1. 欧氏距离 ,最常见的两点之间或多点之间的距离表示法,又称之为欧几里得度量,它定义于欧几里得空间中,如点 x = (x1,...,xn) 和 y = (y1,...,yn) 之间的距离为:

(1)二维平面上两点a(x1,y1)与b(x2,y2)间的欧氏距离:

(2)三维空间两点a(x1,y1,z1)与b(x2,y2,z2)间的欧氏距离:

(3)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的欧氏距离:

也可以用表示成向量运算的形式:

其上,二维平面上两点欧式距离,代码可以如下编写:
2. 曼哈顿距离 ,我们可以定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是在欧几里得空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和。例如在平面上,坐标(x1, y1)的点P1与坐标(x2, y2)的点P2的曼哈顿距离为: ,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
,要注意的是,曼哈顿距离依赖座标系统的转度,而非系统在座标轴上的平移或映射。
通俗来讲,想象你在曼哈顿要从一个十字路口开车到另外一个十字路口,驾驶距离是两点间的直线距离吗?显然不是,除非你能穿越大楼。而实际驾驶距离就是这个“曼哈顿距离”,此即曼哈顿距离名称的来源, 同时,曼哈顿距离也称为城市街区距离(City Block distance)。
(1)二维平面两点a(x1,y1)与b(x2,y2)间的曼哈顿距离

(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的曼哈顿距离

3. 切比雪夫距离 ,若二个向量或二个点p 、and q,其座标分别为及,则两者之间的切比雪夫距离定义如下: ,
,
这也等于以下Lp度量的极值:  ,因此切比雪夫距离也称为L∞度量。
,因此切比雪夫距离也称为L∞度量。
以数学的观点来看,切比雪夫距离是由一致范数(uniform norm)(或称为上确界范数)所衍生的度量,也是超凸度量(injective metric space)的一种。
在平面几何中,若二点p及q的直角坐标系坐标为  及
及  ,则切比雪夫距离为:
,则切比雪夫距离为: 。
。
玩过国际象棋的朋友或许知道,国王走一步能够移动到相邻的8个方格中的任意一个。那么国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?。你会发现最少步数总是max( | x2-x1 | , | y2-y1 | ) 步 。有一种类似的一种距离度量方法叫切比雪夫距离。
(1)二维平面两点a(x1,y1)与b(x2,y2)间的切比雪夫距离

(2)两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的切比雪夫距离 
这个公式的另一种等价形式是 
4. 闵可夫斯基距离(Minkowski Distance) ,闵氏距离不是一种距离,而是一组距离的定义。
(1) 闵氏距离的定义
两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:

其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
2:k值的选择
K 值的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,是预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最有的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
3:分类决策规则
该算法中的分类决策规则往往是多数表决,即由输入实例的 K 个最临近的训练实例中的多数类决定输入实例的类别
----------------------------------------------------------------------------------------------------------------------------------------------------------------
k近邻法的实现:kd树
实现k近邻法,主要考虑如何对训练数据进行快速k近邻搜索(在特征空间维数大及训练数据容量大尤其必要)
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索)
应用背景
SIFT算法中做特征点匹配的时候就会利用到k-d树。而特征点匹配实际上就是一个通过距离函数在高维矢量之间进行相似性检索的问题。针对如何快速而准确地找到查询点的近邻,现在提出了很多高维空间索引结构和近似查询的算法,k-d树就是其中一种。
索引结构中相似性查询有两种基本的方式:一种是范围查询(range searches),另一种是K近邻查询(K-neighbor searches)。范围查询就是给定查询点和查询距离的阈值,从数据集中找出所有与查询点距离小于阈值的数据;K近邻查询是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,就是最近邻查询(nearest neighbor searches)。
特征匹配算子大致可以分为两类。一类是线性扫描法,即将数据集中的点与查询点逐一进行距离比较,也就是穷举,缺点很明显,就是没有利用数据集本身蕴含的任何结构信息,搜索效率较低,第二类是建立数据索引,然后再进行快速匹配。因为实际数据一般都会呈现出簇状的聚类形态,通过设计有效的索引结构可以大大加快检索的速度。索引树属于第二类,其基本思想就是对搜索空间进行层次划分。根据划分的空间是否有混叠可以分为Clipping和Overlapping两种。前者划分空间没有重叠,其代表就是k-d树;后者划分空间相互有交叠,其代表为R树。(这里只介绍k-d树)
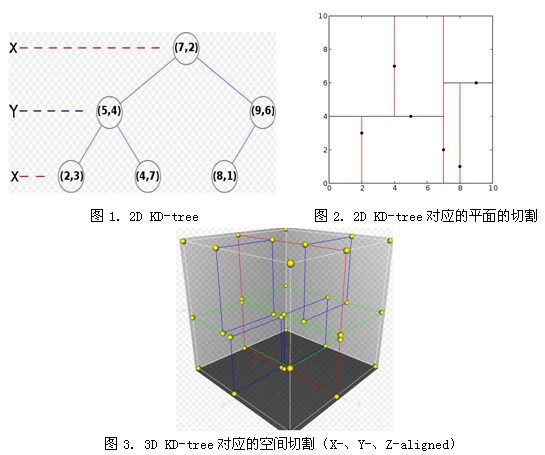
假设有六个二维数据点 = {(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间中。为了能有效的找到最近邻,Kd-树采用分而治之的思想,即将整个空间划分为几个小部分。六个二维数据点生成的Kd-树的图为:
对于拥有n个已知点的kD-Tree,其复杂度如下:
- 构建:O(log2n)
- 插入:O(log n)
- 删除:O(log n)
- 查询:O(n1-1/k+m) m---每次要搜索的最近点个数
一 Kd-树的构建
Kd-树是一个二叉树,每个节点表示的是一个空间范围。下表表示的是Kd-树中每个节点中主要包含的数据结构。Range域表示的是节点包含的空间范围。Node-data域就是数据集中的某一个n维数据点。分割超面是通过数据点Node-Data并垂直于轴split的平面,分割超面将整个空间分割成两个子空间。令split域的值为i,如果空间Range中某个数据点的第i维数据小于Node-Data[i],那么,它就属于该节点空间的左子空间,否则就属于右子空间。Left,Right域分别表示由左子空间和右子空间空的数据点构成的Kd-树。
| 域名 | 数据类型 | 描述 |
| Node-Data | 数据矢量 | 数据集中某个数据点,是n维矢量 |
| Range | 空间矢量 | 该节点所代表的空间范围 |
| Split | 整数 | 垂直于分割超面的方向轴序号 |
| Left | Kd-tree | 由位于该节点分割超面左子空间内所有数据点构成的Kd-树 |
| Right | Kd-tree | 由位于该节点分割超面左子空间内所有数据点构成的Kd-树 |
| Parent | Kd-tree | 父节点 |
实例
先以一个简单直观的实例来介绍k-d树算法。假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间内(如图1中黑点所示)。k-d树算法就是要确定图1中这些分割空间的分割线(多维空间即为分割平面,一般为超平面)。下面就要通过一步步展示k-d树是如何确定这些分割线的。
图1 二维数据k-d树空间划分示意图
k-d树算法可以分为两大部分,一部分是有关k-d树本身这种数据结构建立的算法,另一部分是在建立的k-d树上如何进行最邻近查找的算法。
k-d树构建算法
k-d树是一个二叉树,每个节点表示一个空间范围。表1给出的是k-d树每个节点中主要包含的数据结构。
表1 k-d树中每个节点的数据类型
| 域名 | 数据类型 | 描述 |
| Node-data | 数据矢量 | 数据集中某个数据点,是n维矢量(这里也就是k维) |
| Range | 空间矢量 | 该节点所代表的空间范围 |
| split | 整数 | 垂直于分割超平面的方向轴序号 |
| Left | k-d树 | 由位于该节点分割超平面左子空间内所有数据点所构成的k-d树 |
| Right | k-d树 | 由位于该节点分割超平面右子空间内所有数据点所构成的k-d树 |
| parent | k-d树 | 父节点 |
简单地给x,y两个方向轴编号为0,1,也即split={0,1}。
(1)确定split域的首先该取的值。分别计算x,y方向上数据的方差得知x方向上的方差最大,所以split域值首先取0,也就是x轴方向;
(2)确定Node-data的域值。根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以Node-data = (7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于split = 0(x轴)的直线x = 7;
(3)确定左子空间和右子空间。分割超平面x = 7将整个空间分为两部分,如图2所示。x < = 7的部分为左子空间,包含3个节点{(2,3),(5,4),(4,7)};另一部分为右子空间,包含2个节点{(9,6),(8,1)}。
(4)再根据区域重新计算方差确定split域值,当区域只剩一点时,用初始确定的垂直方向划分

图2 x=7将整个空间分为两部分
3.搜索kd树
在k-d树中进行数据的查找也是特征匹配的重要环节,其目的是检索在k-d树中与查询点距离最近的数据点。这里先以一个简单的实例来描述最邻近查找的基本思路。
星号表示要查询的点(2.1,3.1)。通过二叉搜索,顺着搜索路径很快就能找到最邻近的近似点,也就是叶子节点(2,3)。而找到的叶子节点并不一定就是最邻近的,最邻近肯定距离查询点更近,应该位于以查询点为圆心且通过叶子节点的圆域内。为了找到真正的最近邻,还需要进行'回溯'操作:算法沿搜索路径反向查找是否有距离查询点更近的数据点。此例中先从(7,2)点开始进行二叉查找,然后到达(5,4),最后到达(2,3),此时搜索路径中的节点为小于(7,2)和(5,4),大于(2,3),首先以(2,3)作为当前最近邻点,计算其到查询点(2.1,3.1)的距离为0.1414,然后回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点更近的数据点。以(2.1,3.1)为圆心,以0.1414为半径画圆,如下图所示。发现该圆并不和超平面y = 4交割,因此不用进入(5,4)节点右子空间中去搜索。 
再回溯到(7,2),以(2.1,3.1)为圆心,以0.1414为半径的圆更不会与x = 7超平面交割,因此不用进入(7,2)右子空间进行查找。至此,搜索路径中的节点已经全部回溯完,结束整个搜索,返回最近邻点(2,3),最近距离为0.1414。
一个复杂点了例子如查找点为(2,4.5)。同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径<(7,2),(5,4),(4,7)>,取(4,7)为当前最近邻点,计算其与目标查找点的距离为3.202。然后回溯到(5,4),计算其与查找点之间的距离为3.041。以(2,4.5)为圆心,以3.041为半径作圆,如下图左所示。可见该圆和y = 4超平面交割,所以需要进入(5,4)左子空间进行查找。此时需将(2,3)节点加入搜索路径中得<(7,2),(2,3)>。回溯至(2,3)叶子节点,(2,3)距离(2,4.5)比(5,4)要近,所以最近邻点更新为(2,3),最近距离更新为1.5。回溯至(7,2),以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,如下图右所示。至此,搜索路径回溯完。返回最近邻点(2,3),最近距离1.5。















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









